爱站程序员基地
爱站程序员基地[toc]
问:什么是操作系统?
操作系统其实也是一种软件,不过这个软件不同于用的应用软件,这个软件比较底层,操作系统就是在硬件和软件之间的一个中间层;能够保证软件对内存包括CPU正确的交互;
问:操作系统的内存?虚拟内存?
在操作系统中,现在普遍采用的是分层存储的体系,也就是磁盘、内存、高速缓存的金字塔结构;
- 磁盘的容量大,价格相对较低,是永久存储的,掉电不丢失;
- 内存和高速缓存都是临时存储,掉电丢失,内存中存放进程;
虚拟内存
在计算机中,一个应用程序都是分段运行的,也就是说一个进程并不一定需要全部加载到内存中,当需要一个进程的程序段时,将此程序段加载到内存中,if不需要,需要另一个程序段2的时候,再把段1换出,把段2换入;这样不断的换入和换出,处理器就可以运行一个大于实际物理内存的应用程序,或者看起来好像处理器拥有了大于实际物理内存的空间,这就是虚拟内存空间,真正是内存空间称为物理内存空间;这样的话就存在两个内存空间,分别对应的地址称为虚拟地址和物理地址,对于CPU而言,看到的只是虚拟内存,对于总线而言,看到的是物理地址,所以就需要一个转换单元,将虚拟地址装换为物理地址,也就是地址的映射,这个部分叫做内存管理单元MMU;(CPU的指令是对虚拟内存进行的操作,然后由内存管理单元MMU将虚拟地址转换为物理地址,然后由总线去操作内存的物理地址)
问:有一些任务紧急的进程需要执行,采用什么调度算法,都有哪些调度算法?
可以采用优先级调度,使用剥夺式。
① 先来先服务 FCFS,从后备队列选择最先进入的作业,调入内存。
② 短作业优先 SJF,从后备队列选择估计运行时间最短的作业,调入内存。平均等待时间、平均周转时间最少。
③ 优先级调度算法,分为非剥夺式和剥夺式。
④ 高响应比优先算法,综合了 FCFS 和 SJF,同时考虑了每个作业的等待时间和估计的运行时间。
⑤ 时间片轮转算法,遵循先来先服务原则,但是一次只能运行一个固定的时间片。
问:Linux中进程的状态?
① 可执行状态,正在运行或等待运行。
② 可中断的等待状态。
③ 不可中断的等待状态。
④ 停止状态。
⑤ 终止状态(僵尸进程)。
问:进程间的通信?
每个进程之间彼此相互独立,拥有各自不同的地址空间,所以在一个进程中的全局变量在其他进程里是看不到的,所以进程之间交换数据需要内核,也就是在内核中开辟一块缓冲区,然后把数据从用户空间拷贝到缓冲区,其他线程再从缓冲区把数据读走,这就是进程间的通信;
- 管道pipe:是一种半双工的通信,也就是说数据只能在一个方向上流动,并且只能用于亲缘关系的进程通信(比如父子进程或兄弟进程);实质上就是管道一端的进程顺序的将进程写入缓冲区,然后另一端的进程再依次顺序读取数据;
- 命名管道FIFO:和前面基本一样,但是允许无亲缘关系的进程进行通信;
- 消息队列MessageQueue:就是一个消息的链表,与管道进行相比,就是为每个消息指定了特定的消息类型,接收的时候根据自定义条件接收特定类型的消息;
- 共享内存:也就是允许多个线程共享一个指定的存储区,这样的好处是效率高,因为进程可以直接读写内存,不需要进行数据的拷贝;
- 信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问,实现进程之间的互斥和同步,经常是把它作为一种锁机制,防止当一个进程正在访问共享资源的时候,其他进程也访问该资源;比如当某个进程来访问内存1的时候,就把信号量的值设置为0,这时候其他的进程再访问的时候看到信号量为0就知道已经有进程在访问了;
- 套接字socket:可以实现不同计算机上的进程之间的通信,比如说客户端和服务端;客户端:1创建socket。根据ip地址和端口号构造socket对象;2打开输入输出流:使用getInputStream和getOutStream;3进行读写操作;4关闭socket;
- 服务端:1创建ServerSocket并绑定指定端口,用于监听客户端请求,2调用accept。3调用socket的getOutputStream和getInputStream,用于数据的收发;4福安比socket对象;
问:操作系统中的锁(互斥锁、读写锁、自旋锁、悲观锁、乐观锁)?
所有的虚拟机比如JVM都是运行在操作系统上的,所以jvm上的锁都是基于操作系统而言的,主要是在多线程编程中,为了保证数据操作的一致性,引入了锁机制,用来保证临界区资源的安全。也就是通过锁机制,保证在多核多线程的环境下,在某一个时间点,只要一个线程能够进入临界区。
-
互斥锁(mutex互斥量):这种锁是最直接简单粗暴的,就是多个线程共享一个互斥量,然后多个线程之间去竞争,得到锁的线程进入临界区执行代码,其他的线程就会休眠,然后当锁被释放后会被唤醒;
-
读写锁:顾名思义,就是区分读写操作,比如在读多写少的时候,if不加区分的使用互斥锁是有点浪费的,效率太低,每次只有一个线程拿到锁,其他都阻塞了。读写锁就是区分读操作和写操作,当加了读锁的时候,多个线程可以同时读,当是写锁的时候,那只允许一个线程操作;
-
自旋锁:当阻塞或者唤醒一个线程的时候需要去切换CPU的状态,这种状态的转换是很耗费时间的,比如有时候可能状态转换消耗的时间有可能比用户执行代码的时间都要长。所以有时候把一个线程去挂起然后再唤醒的话有点得不偿失,所以可以不必让当前线程去阻塞,而是让其自旋,if在自旋完成后前面锁定同步资源的线程已经释放了锁,那当前线程就可以不必阻塞而是直接获取同步资源,这样就可以避免线程切换的开销。
缺点:自旋等待的过程是占用CPU的,if锁被占用的时间很短,自旋等待的效果就会很好,但是,if锁被占用的时间很长,那就会浪费处理器的资源。所以需要给自旋等待设置一定的限度,超过了以后还没有获得锁,那就把当前线程挂起;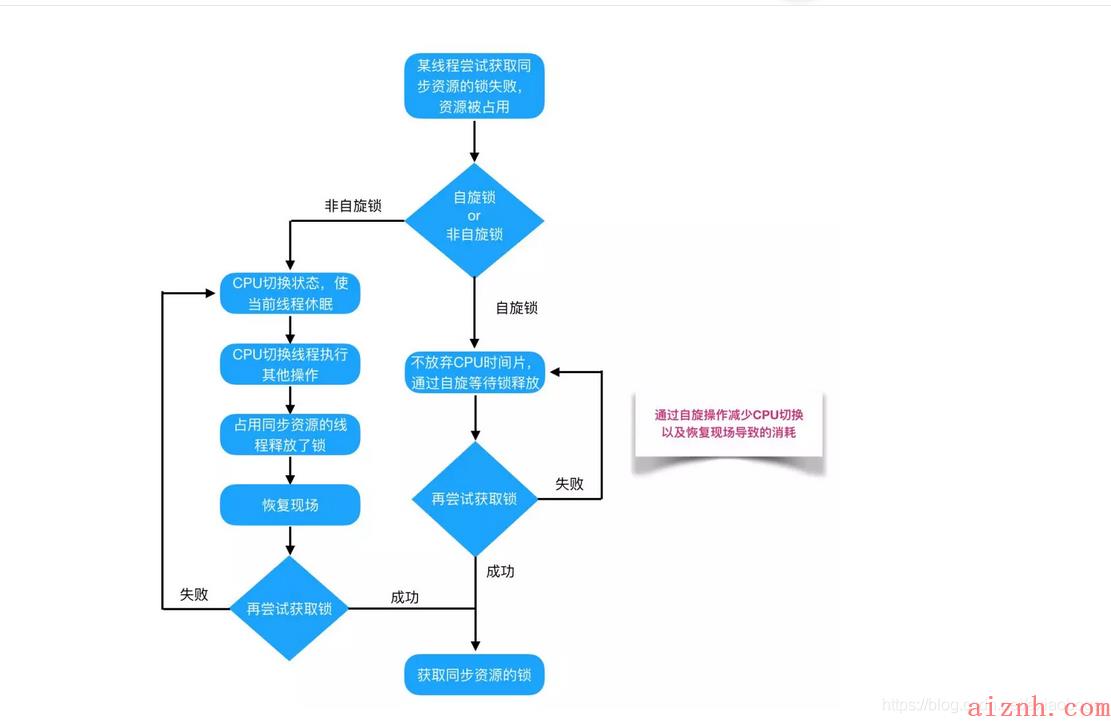
-
悲观锁,就是说我们总是假设的认为每次对数据操作时,其他线程都会修改这个数据,所以无论共享数据是否真正竞争,这种处理都去加锁,比如最常见的使用synchronized关键字,可以将操作共享数据的代码或者方法声明为synchronized,这样每次就只有一个线程能拿到锁;此外也可以用lock来加锁,这样的缺点是其他线程想要访问数据都会阻塞挂起,这样每次阻塞和唤醒都有性能上的消耗; 悲观锁适合写操作多的场景,可以保证写操作时数据正确;(互斥锁、自旋锁都是悲观锁)
-
乐观锁,这种方法就是说总是认为不会发生线程不安全,也就是认为每次取数据的时候,其他线程不会修改共享的数据,所以不用上锁,在执行完需要更新数据的时候再比较判断其他线程是否修改过数据,一种常见的方法就是CAS(compare and swap),假设不会冲突所有不上锁,if冲突了那就重新来,直到成功为止;在CAS中,有3个操作数,当前值V,期望值E,还有新值new,当操作一个共享变量的时候,比较V和E,if相等,那说明这个过程中没有其他线程修改了这个变量,就把V置为新值new;if不相等,那说明这个过程中有其他线程修改了这个变量,那就改变期望值E重新进行比较。 乐观锁适合读操作多的场景,不加锁的特点能够使其性能提升;

举个例子,比如两个线程操作共享变量a=0;要执行a++;线程A先对变量a进行a++,V=0,E=0,新值new=1;但是在执行的过程中,线程B执行了a++将值改为1了,所以在比较的时候V=1,不等于E了,所以就需要重新比较,将3个操作数更新为V=1,E=1,new=2,这时候if没有其他线程操作了,那就将新值赋给V,修改成功;
问:什么是LRU算法?
LRU算法的全称是Least Recently Used,也就是最近最少使用的意思,是一种内存管理算法,意思就是说:长期不使用的数据,在未来被使用的几率也不大,所以当内存中的数据达到一定阈值后,就需要移除最近最少使用的数据;整体如图所示:

LRU算法的实现是依靠于哈希链表的结构,原本无序的哈希表使用一个链表串联了起来,也就是每一个key-value都被作为了链表中的节点;
- if内存还没有满而且访问的新数据,那就接着把访问的数据接到链表后面;
- if内存还没有满而且访问的数据之前已经访问过了,那把之前的移除,然后把新的数据放到链表末尾;
- if内存满了,那就把链表头移除;
在实际实现上使用java里已有的LinkedHashMap,
package edu.test.algorithm;import java.util.LinkedHashMap;public class LRUCache {LinkedHashMap<Integer,Integer> linkedHashMap;int capacity;public LRUCache(int capacity) {linkedHashMap=new LinkedHashMap<Integer, Integer>(capacity);this.capacity=capacity;}public int get(int key) {if(linkedHashMap.containsKey(key)){int value=linkedHashMap.get(key);linkedHashMap.remove(key);linkedHashMap.put(key, value);return value;}return -1;}public void set(int key, int value) {if(linkedHashMap.containsKey(key)){linkedHashMap.remove(key);}else if(linkedHashMap.size()>=capacity){linkedHashMap.remove(linkedHashMap.keySet().iterator().next());}linkedHashMap.put(key, value);}}
问:什么是消息队列(MQ)?
我理解的消息队列就是一种转发器,生产者将消息发送到一个叫做队列的容器里,然后队列再将消息转发给消费者,就是这样的过程(常见的消息队列有Kafka、RabbitMQ)
为什么使用消息队列?
- 异步:比如说在下单系统,本来我们是下单付钱之后,这个流程就应该走完了,但是可能会在这个系统里面添加很多其他的系统,比如说优惠券系统、积分系统等等,这样如果不处理的话来依次把这些任务完成,链路越长,耗的时间也就越长,所以有了消息队列,可以,我们的主要的下单系统在完成任务后,将消息写到队列里,就可以返回了,至于后面的系统,就可以让它们去异步处理;
- 解耦:上面的过程似乎线程也可以去处理,但是if要用多线程的话,其实有个问题就是每个系统的耦合程度太高,把这些线程接口写在一起,那里面随便一个出现问题都可以会导致系统出错,所以可以使用消息队列,来进行解耦,比如说下单系统,当你成功后,你只需要把支付成功的消息告诉别的系统就可以了,别的系统收到了就去做处理,哪个系统订阅了你的消息,那它就去做出自己的反映。这样的话就很大程度的解耦合;
- 削峰:比如这个下单系统在每次大促的时候,也就是高并发的场景下,会涌入大量请求,但是系统能够处理的请求时有限的,所以当请求过多涌入系统后,就会出错,所以可以用消息队列,将请求写到消息队列里,然后系统根据自己能处理的请求数去消息队列里拿数据;
问:服务器为什么都部署在Linux上?
- 免费并且开源,能够轻松建立和编译源代码;
- 可以多人共同登录到一个服务器进行工作,可以多用户多进程;
- 其实据我所知,有很多二三线城市的党政机关官方网站也都是用windows server;
问:几个常用git命令?
git add //将创建或修改的文件添加到本地暂存区,保存临时更改;git commit //提交文件到仓库git push 仓库名 master //将本地代码库同步到远程仓库;git branch -a //查看所有的分支;git clone git://github.com/schacon/grit.git //把代码从服务器拉下来;
问:说出几个常用命令?
//基本命令:shutdown //关机reboot //重启shutdown -- helpman shutdown //两个都是帮助命令//目录操作cd //切换目录ls //查看目录mkdir //创建目录rm [-rf] //删除文件或目录; -r代表递归mv //修改目录cp //拷贝目录//文件操作touch a.txt //创建文件rm -rf a.txt //删除文件cat a.txt //查看文件//cat一次性显示全部文件,more是以页的形式查看tail -10 a.txt //查看后10行;tar -zcvf a.tar * //将文件打包并压缩为a.tar;tar -zxvf a.tar //将文件解压缩;修改文件用vim
问:查看打印日志?,查看包含某字符的所有文件;
有好几个命令,比如tail、head、cat等;
最常用的cat:
cat -n filename | grep "关键字" //搜索关键字附近日志;-n是显示行号的意思;tail -f a.log //实时日志;cat -n a.log | grep "test" //搜索关键字附近日志grep -rn "关键字" * //r是递归,n是行号;*代表全部;find /root/ -name "*.log" //查找root目录中以.log结尾的文件sed -n \'3,9\' file.txt //显示第3行到第9行的内容;sed -n \'10p\' file.txt //显示第10行;
问:如何查看进程?
ps -ef //查看静态的进程统计信息;top //动态的;lsof -i:8080 //查看2020端口的占用情况;netstat -tunlp | grep 端口号 //查看tcp、udp的端口和进程相关情况;t和u分别指tcp和udpnetstat -an //查看当前系统端口;netstat -an | grep 8080 //搜索指定端口;
问:说一下vim?
vim一共有三种模式:命令行模式,编辑模式、底行模式
命令行模式:
i :进入编辑模式;上下左右或者hjkl: 控制移动;: 冒号进入底行模式;50dd : 删除50行,dd代表删除,数字往往代表重复;/字符: 查找字符;
编辑模式:在命令行里按i进入编辑模式,编辑模式就正常的写,写完之后esc退出,进入命令行模式;
底行模式:在命令行里按:进入底行模式,q! :强制退出;wq :保存退出;
问:说一下grep命令?
grep 主要是用来对文本搜索的;
grep -i "test" test.txt //在test文件里搜索含有test字符串(-i不区分大小)grep -i -n "test" test.txt //并显示行号;grep -c "test" test.txt //输出test出现的行数;grep -o "test" test.jtxt | wc -l //-o指示grep显示所有匹配的地方,并且每一个匹配单独一行输出;wc是统计行数;这样就统计出来了;