 爱站程序员基地
爱站程序员基地目录
1. 数据采集
2. 统计展示
2.1. 颜色分布
2.2. 评价词云
2.3. 用户属性
2.4. 丝袜市场
3. 丝袜起源与发展
4.数据源的获取地址

最近在大街上也开始常见丝袜这一道具的出场,那么今天,我们就用
python
来研究研究
丝袜
的故事~

-

1. 数据采集
仅采集在京东销量最高的某莎品牌的某款产品的数据。由于都是均码,区别在于color,所以采集的是各color产品的大致销量分布。这部分数据采集这里不做介绍,和此前推文一致。
不过,这里我们将对评论进行采集,做简单的评价分析。
页面分析
在开发者模式,我们通169be过翻页找到了评论数据源地址。
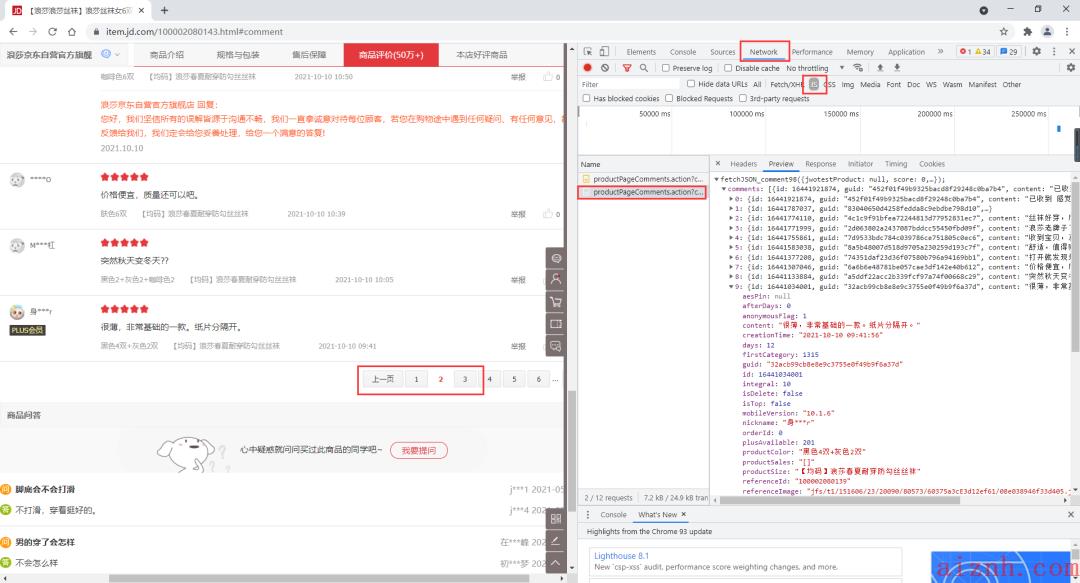
找到评论数据源
某页的地址如下:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100002080143&score=0&sortType=6&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1
解析如下:
url = 'https://club.jd.com/comment/productPageComments.action?'params = { 'callback': 'fetchJSON_comment98', 'productId': productId, 'score': 0, 'sortType': 6, 'page': page, # 变量,页码 'pageSize': 10, 'isShadowSku': 0, 'rid': 0, 'fold': 1, }采集过程
根据对页面分析及所需数据的解析,我们可以构造获取评论信息的函数如下,得到的是某页的评论列表数据
# 获取评论信息def get_comments(productId, page, proxies=None): # time.sleep(0.5) url = 'https://club.jd.com/comment/productPageComments.action?' params = { 'callback': 'fetchJSON_comment98', 'productId': productId, 'score': 0, 'sortType': 6, 'page': page, 'pageSize': 10, 'isShadowSku': 0, 'fold': 1, } # print(proxies) r = requests.get(url, headers=headers, params=params, # proxies=proxies, timeout=6) comment_data = re.findall(r'fetchJSON_comment98\\((.*)\\)', r.text)[0] comment_data = json.loads(comment_data) comments = comment_data['comments'] return comments数据预览
由于请求次数过多可能触发反爬,为了尽可能采集更多数据,实际操作中我会用到
代理ip
的方法。
对于采集到的数据,我们做了简单的清洗处理
df = pd.DataFrame(commentsList)df.drop_duplicates(subset='guid',inplace=True)df = df[~(df['content']=='此用户未填写评价内容')]df = df[['id', 'content', 'creationTime', 'score', 'plusAvailable', 'mobileVersion', 'productColor', 'referenceTime', 'nickname']]
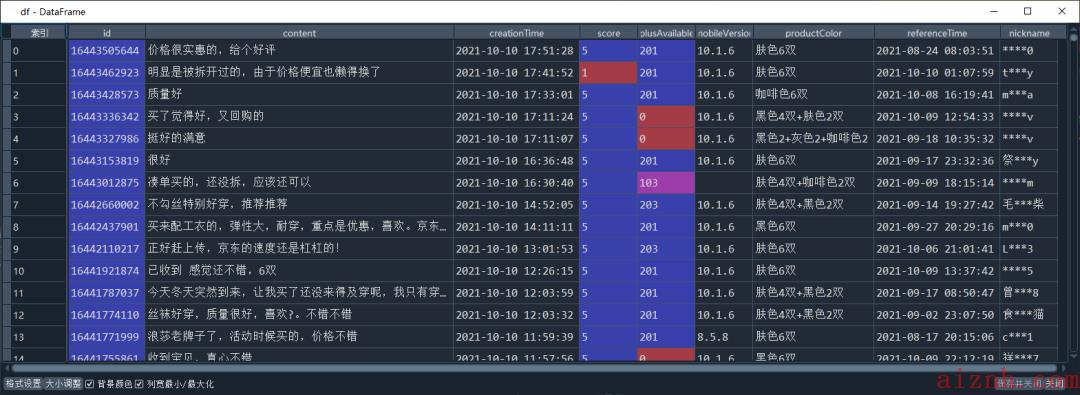
数据预览

2. 统计展示
本部分我们主要看丝袜的颜色分布,购买丝袜的用户评价词云、用户属性以及丝袜市场份额
2.1. 颜色分布
由于采集到的原始数据中是按组合卖的,我们做简单的处理后拆分出每个颜色的数量,然后进行统计展示。
肤色
(也就是肉色)占比最高,达到
62.9%
,其次是黑色占比23.3%。
import pandas as pddf = pd.read_excel('丝袜数据.xlsx')df['颜色'] = df.颜色.str.replace('双','').str.split('+')df = df.explode('颜色')df[['颜色','单件数']] = df.颜色.str.extract('(?P<颜色>.*?)(?P<单件数>\\d)')df['单件数'] = df['单件数'].astype('int')df['数量'] = df['单件数']*df['commentCount']colorNum = df.groupby('颜色')['数量'].sum().to_frame('数量')colorNum颜色 数量 咖啡色 34334 灰色 44372 肤色 359305 黑色 133268 # 饼图绘制import matplotlib.pyplot as pltfrom matplotlib import font_manager as fmplt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falselabels = colorNum.indexsizes = colorNum['数量']explode = (0, 0, 0, 0.1) fig1, ax1 = plt.subplots(figsize=(6,5))patches, texts, autotexts = ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True, startangle=90)ax1.axis('equal') # 重新设置字体大小proptease = fm.FontProperties()proptease.set_size('large')plt.setp(autotexts, fontproperties=proptease)plt.setp(texts, fontproperties=proptease)ax1.set_title('【丝袜 颜色】 分布')plt.show()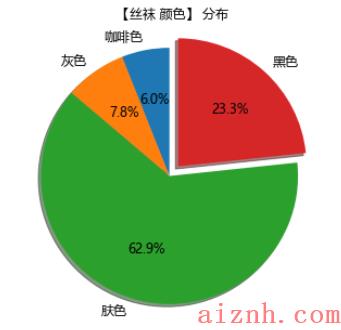
2.2. 评价词云

词云
2.3. 用户属性
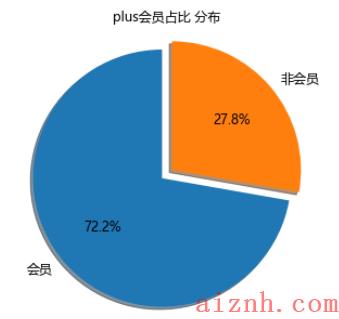
会员分布
plus会员占比高达72.7%
评论时间分布
评论时间集中在
上午10-11点
和晚上的8-10点。。。
labels = timeNum.indexsizes = timeNum['数量']plt.style.use('ggplot')x = labelsplt.figure(figsize=(10,5))plt.title("评论时间折线图")plt.xlabel("时间")plt.xticks(labels)plt.ylabel("数量")plt.plot(x,sizes,'-',color='coral',label="评论数")plt.legend()plt.show()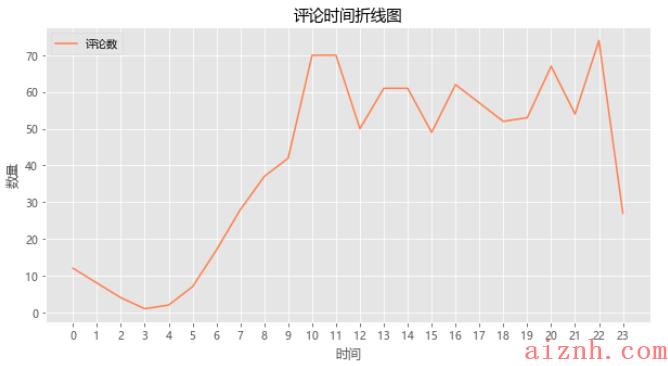
2.4. 丝袜市场
购买丝袜较多的主要是集中在南方的城市
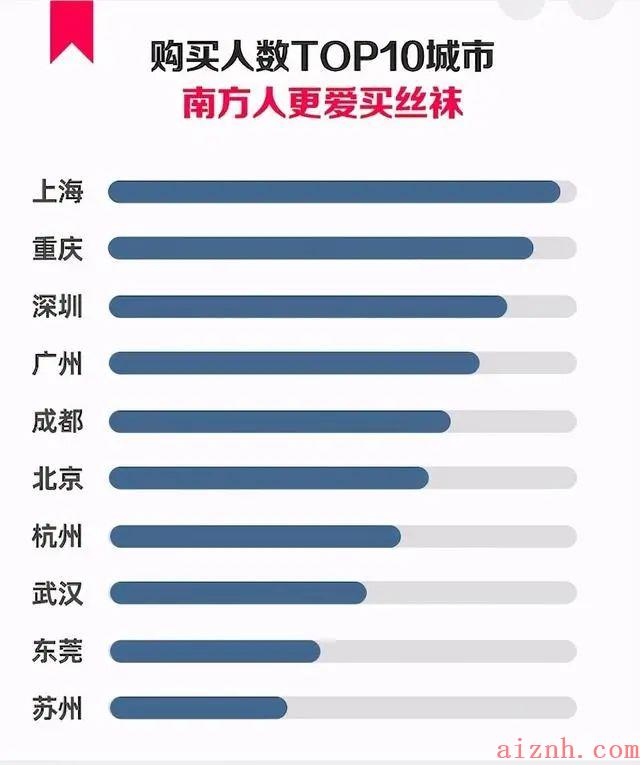
来源:丝袜消费流行趋势报告
随着时尚理念的不断更迭,丝袜的款式也不再单一,年轻人也越来越追求个性化的丝袜,这在最新发布的《丝袜消费流行趋势报告》中也有所体现,越来越多的人开始购买小众款丝袜。
丝袜市场规模
截止到2019年(2020年疫情特殊不做参考),中国年产丝袜39.73亿双,位居全球第一,其中国内销量33.94亿双,市场规模五年间从175亿跃升至266.4亿,说明国人对丝袜的接受度正越来越高。
不过值得一提的是,在这266.4亿中,有3.57亿是男性丝袜,且规模比2014年翻了一倍,或许在不远的将来,男性穿丝袜将变成新的时尚。
fig, ax = plt.subplots(figsize=(10,5))y_data = [175.5, 190.2, 203.8, 224.2, 248.9, 266.4]x_data = ['2014年', '2015年', '2016年', '2017年', '2018年', '2019年']# 柱状图颜色color = 'coral'# 柱状图bar = plt.bar(x_data, y_data, 0.5, color=color,edgecolor='grey')# 设置标题ax.set_title('丝袜市场规模(单位:亿)',fontsize=14,y=1.05)# 设置坐标轴标题ax.set_ylabel("",fontsize = 12,color = 'black',alpha = 0.7,rotation=360)# 设置Y轴区间ax.set_ylim(0,300)# 显示数据标签for a,b in zip(x_data, y_data): plt.text(a,b, b, ha='center', va='bottom', )

3. 丝袜起源与发展
虽然现在我们在大街小巷看到穿着丝袜的基本都是女性,并且我们聊到丝袜的时候都会和女性、性感挂钩。但是,其实我们追溯丝袜的起源会发现,最早丝袜是高质量男性的必备。
大家可以回忆在中学时代欧美历史里的知名人物的插图,是不是都是穿着丝袜的!!

拿破仑
16世纪,随着工业的发展,在欧洲出现了第一台手工针织机。当时丝袜是一种相当昂贵的产品,只有在皇宫中的男性才有资格穿丝袜!对,男性!!你没有看错!!!在法国,贵族男性争抢购买一条丝袜,仿佛丝袜成为一种高贵的象征。
当然在16世纪后期,英国人发明了更为先进的针织机,质量也有进一步提升。欧洲的贵妇名媛也开始穿起丝袜,而此时的丝袜以红色、橙色、紫色为上品,看见女人们穿丝袜的模样,男人们很自觉的不穿了,而是看女人们穿,这标志女人穿丝袜的时代到来了。

法国国王路易十四
20世纪初,随着两次技术革命的重新,尼龙丝袜一度风靡全球,在欧洲尼龙丝袜一度出现脱销。
二战爆发期间,尼龙被列为军需用品,尼龙丝袜生产瘫痪,只能限量发售,战争期间有人做了调查:女人们最想要的是什么?结果三分之二选择了丝袜,而选男人的,还不到三分之一。在丝袜面前,男人一文不值。在黑市上,一双丝袜的价格,一度被炒到四千美元。没钱的女人,只能用粉饼或眉笔在腿上画出丝袜来“画饼充饥”。
战争结束,尼龙丝袜恢复生产,女人们如愿以偿,男人们也如愿以偿了。
1950年,尼龙丝袜开始大规模的生存,在外国普通的女人也可以买到一双价格低廉的丝袜!女人们兴高采烈地排长队抢购尼龙丝袜,“求袜若渴”的女人买到了尼龙丝袜后,等不及回家,干脆坐在马路边,露出雪白大腿当众换上,一时肉色撩人,风情万种,鼻血飞溅。
1980年,丝袜等一些产品相继从香港向内地流行开来,当时的内地女生只是想买而不敢去试穿!
1990年,丝袜逐渐被人所接受,性感的肉丝成为当时女人的时尚标配性搭配。

20世纪80年代穿着时尚丝袜的中国姑娘
21世纪,丝袜出现了材质,颜色,种类的不同。丝袜完全揭开了神秘的面纱,如同冬天我们离不开保暖的打底连裤丝袜一样,可以达到紧致腿部塑性效果的丝袜更是妹子们手中必不可少的神器。
以上就是本次全部内容,我们从京东某品牌丝袜的数据做展开引申,再介绍了丝袜在中国的市场规模发展以及丝袜的起源。
4.数据源的获取地址













点击这段字体即可获取



