爱站程序员基地
爱站程序员基地
有时候爬数据遇到像下面这种,数据在script标签中以javascript形式存在。
<script type=\"text/javascript\">var totalReviewsValue = 32;var averageRating = 4.5;if(totalReviewsValue != 0){events = \"...\";}</script>
一般我们都是通过正则的方式抽取,其实还可以使用js2xml。将js转换为xml标记的文本,这样就可以通过抽取。
先提前出js文本
from pyquery import PyQuery as pqdoc = pq(html)js_text = doc(\'script\').text()print(js_text)var totalReviewsValue = 32;var averageRating = 4.5;if(totalReviewsValue != 0){ events = \"...\";}
js2xml
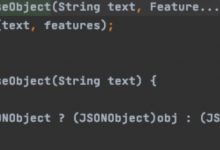
import js2xmldoc = pq(html)js_text = doc(\'script\').text()parse_js = js2xml.parse(js_text)print(type(parse_js))print(parse_js)<class \'lxml.etree._Element\'><Element program at 0x10f136888>
为了方便我们查看Element对象,使用下面的代码:
js2xml.pretty_print(data)
wow,返回我们熟悉的标记语言字符串。
<program><var name=\"totalReviewsValue\"><number value=\"32\"/></var><var name=\"averageRating\"><number value=\"4.5\"/></var><if><predicate><binaryoperation operation=\"!=\"><left><identifier name=\"totalReviewsValue\"/></left><right><number value=\"0\"/></right></binaryoperation></predicate><then><block><assign operator=\"=\"><left><identifier name=\"events\"/></left><right><string>...</string></right></assign></block></then></if></program>
因为parse_js是lxml库的Element类对象。如果我们熟悉lxml库的话,应该知道可以使用xpath或者css定位数据。

我们想获取name=averageRating节点里的number节点中的value属性的值。
number = parse_js.xpath(\"//program/var[@name=\'averageRating\']/number/@value\")print(number)print(number[0])[\'4.5\']4.5