爱站程序员基地
爱站程序员基地3 静态网页爬取
- 3.3 使用requests库实现HTTP请求
- 1. 生成请求
- 2. 查看状态码与编码
- 3. 请求头与响应头处理
- 4. Timeout设置
- 5. 生成完整HTTP请求
3.3 使用requests库实现HTTP请求
requests库是一个原生的HTTP库,比urllib3库更为容易使用。requests库发送原生的HTTP 1.1请求,无需手动为URL添加查询字串,也不需要对POST数据进行表单编码。相对于urllib3库,requests库拥有完全自动化Keep-alive和HTTP连接池的功能。requests库包含的特性如下。
1. 生成请求
requests库生成请求的代码非常便利,其使用的request方法的语法格式如下。
requests.request.method(url,**kwargs)
request方法常用的参数及其说明如下。
import requestsurl = \'http://www.jd.com\'rqq = requests.get(url)print(\'响应码:\', rqq.status_code)print(\'编码:\', rqq.encoding)print(\'请求头:\', rqq.headers)# print(\'实体:\', rqq.text)print(\'实体:\', rqq.content.decode(\'utf-8\'))

- rqq.text 和 rqq.content两者的区别
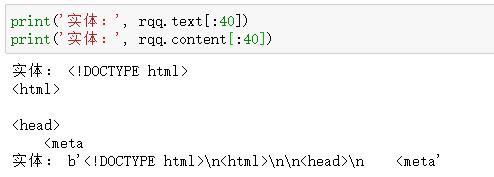
- 变成utf-8

import requestsurl = \'http://www.jd.com\'rqq = requests.get(url)rqq.encoding = \'utf-8\'print(\'实体:\', rqq.text)
print(\'实体:\', rqq.content.decode(\'utf-8\'))
2. 查看状态码与编码
需要注意的是,当requests库猜测错时,需要手动指定encoding编码,避免返回的网页内容解析出现乱码。
手动指定的方法并不灵活,无法自适应对应爬取过程中不同网页的编码,而使用chardet库比较简便灵活,chardet库是一个非常优秀的字符串∕文件编码检测模块。
chardet库使用detect方法检测给定字符串的编码,detect方法常用的参数及其说明如下。
import chardetchardet.detect(rqq.content)
3. 请求头与响应头处理
requests库中对请求头的处理与urllib3库类似,也使用headers参数在GET请求中上传参数,参数形式为字典。使用headers属性即可查看服务器返回的响应头,通常响应头返回的结果会与上传的请求参数对应。
4. Timeout设置
为避免因等待服务器响应造成程序永久失去响应,通常需要给程序设置一个时间作为限制,超过该时间后程序将会自动停止等待。在requests库中通过设置timeout这个参数实现,超过该参数设定的秒数后,程序会停止等待。
5. 生成完整HTTP请求
使用requests库的request方法向网站“http://www.tipdm.com/tipdm/index.html”发送一个完整的GET请求,该请求包含链接、请求头、响应头、超时时间和状态码,并且编码应正确设置。
import requestsimport chardeturl = \'http://www.jd.com\'head = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko\'}rqq = requests.get(url, headers=head, timeout=2.0)# rqq.encoding = \'utf-8\'rqq.encoding = chardet.detect(rqq.content)[\'encoding\']rqq.text