 爱站程序员基地
爱站程序员基地学习意味着通过学习或经验获得知识或技能。基于此,我们可以定义机器学习(ML)如下 –
它可以被定义为计算机科学领域,更具体地说是人工智能的应用,其为计算机系统提供了学习数据和从经验改进而无需明确编程的能力。
基本上,机器学习的主要焦点是允许计算机自动学习而无需人为干预。现在问题是如何开始和完成这种学习?它可以从数据的观察开始。数据可以是一些示例,指令或一些直接经验。然后在此输入的基础上,通过查找数据中的某些模式,机器可以做出更好的决策。
机器学习类型(ML)
机器学习算法帮助计算机系统学习而无需明确编程。这些算法分为监督或无监督。现在让我们看一些算法 –
监督机器学习算法
这是最常用的机器学习算法。它被称为监督,因为从训练数据集学习算法的过程可以被认为是监督学习过程的教师。在这种ML算法中,可能的结果是已知的,训练数据也标有正确的答案。可以理解如下
假设我们有输入变量 x 和输出变量 y ,我们应用算法来学习从输入到输出的映射函数,例如
Y = f(x)
现在,主要目标是近似映射函数,以便当我们有新的输入数据(x)时,我们可以预测该数据的输出变量(Y)。
主要监督学习倾向问题可分为以下两类问题 –
-
分类 – 当我们有“黑色”,“教学”,“非教学”等分类输出时,一个问题被称为分类问题。
-
回归 – 当我们有“距离”,“千克”等实际值输出时,问题称为回归问题。
决策树,随机森林,knn,逻辑回归是监督机器学习算法的例子。
无监督机器学习算法
顾名思义,这些机器学习算法没有任何主管提供任何形式的指导。这就是为什么无监督的机器学习算法与一些人称之为真正的人工智能的方法紧密结合的原因 可以理解如下
假设我们输入变量x,那么在监督学习算法中就没有相应的输出变量。
简单来说,我们可以说在无监督学习中,没有正确的答案,也没有教师可以提供指导。算法有助于发现数据中有趣的模式。
无监督学习问题可分为以下两种问题
-
聚类 – 在聚类问题中,我们需要发现数据中的固有分组。 例如,按客户的购买行为对客户进行分组。
-
关联 – 一个问题被称为关联问题,因为这类问题需要发现描述大部分数据的规则。 例如,找到同时购买 x 和 y 的客户。
用于聚类的K均值,用于关联的Apriori算法是无监督机器学习算法的示例。
加固机器学习算法
这些机器学习算法的使用非常少。这些算法训练系统做出具体决策。基本上,机器暴露在一个环境中,在那里它使用试错法连续训练自己。这些算法从过去的经验中学习,并尝试捕获最佳可能的知识,以做出准确的决策。马尔可夫决策过程是增强机器学习算法的一个例子。
最常见的机器学习算法
在本节中,我们将了解最常见的机器学习算法。算法如下所述 –
线性回归
它是统计学和机器学习中最着名的算法之一。
基本概念 – 主要是线性回归是一种线性模型,它假设输入变量x和单个输出变量y之间的线性关系。换句话说,我们可以说y可以从输入变量x的线性组合计算。变量之间的关系可以通过拟合最佳线来建立。
线性回归的类型
线性回归有以下两种类型 –
-
简单线性回归 – 线性回归算法如果只有一个自变量,则称为简单线性回归。
-
多元线性回归 – 线性回归算法如果具有多个自变量,则称为多元线性回归。
线性回归主要用于基于连续变量估计实际值。例如,可以通过线性回归来估计基于实际值的一天中商店的总销售额。
Logistic回归
它是一种分类算法,也称为 logit 回归。
主要逻辑回归是一种分类算法,用于根据给定的一组自变量估计离散值,如0或1,真或假,是或否。基本上,它预测概率,因此其输出介于0和1之间。
决策树
决策树是一种监督学习算法,主要用于分类问题。
基本上它是一个分类器,表示为基于自变量的递归分区。决策树具有形成有根树的节点。生根树是一个带有名为“root”的节点的有向树。Root没有任何传入边缘,所有其他节点都有一个传入边缘。这些节点称为叶子或决策节点。例如,考虑以下决策树以查看某人是否合适。

支持向量机(SVM)
它用于分类和回归问题。但主要是用于分类问题。SVM的主要概念是将每个数据项绘制为n维空间中的点,每个特征的值是特定坐标的值。这里将是我们将拥有的功能。以下是一个简单的图形表示来理解SVM的概念
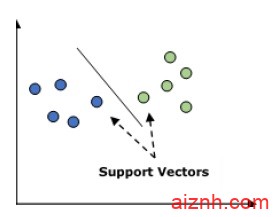
在上图中,我们有两个特征,因此我们首先需要在二维空间中绘制这两个变量,其中每个点有两个坐标,称为支持向量。该行将数据拆分为两个不同的分类组。这一行是分类器。
朴素贝叶斯
它也是一种分类技术。这种分类技术背后的逻辑是使用贝叶斯定理来构建分类器。假设预测变量是独立的。简单来说,它假定类中特定特征的存在与任何其他特征的存在无关。下面是贝叶斯定理的等式
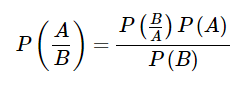
NaïveBayes模型易于构建,特别适用于大型数据集。
K-Nearest Neighbors(KNN)
它用于问题的分类和回归。它被广泛用于解决分类问题。该算法的主要概念是它用于存储所有可用的案例,并通过其k个邻居的多数票来对新案例进行分类。然后将该情况分配给在其K-
最近邻居中最常见的类,通过距离函数测量。距离函数可以是欧几里德,闵可夫斯基和汉明距离。考虑以下使用KNN
-
计算KNN比用于分类问题的其他算法昂贵。
-
变量的标准化需要更高范围的变量,否则可能会对其产生偏差。
-
在KNN中,我们需要处理像噪声消除这样的预处理阶段。
K-Means聚类
顾名思义,它用于解决聚类问题。它基本上是一种无监督学习。K-Means聚类算法的主要逻辑是通过许多聚类对数据集进行分类。按照以下步骤通过K- means形成集群
-
K-means为称为质心的每个簇选择k个点。
-
现在每个数据点形成具有最接近的质心的簇,即k个簇。
-
现在,它将根据现有的集群成员找到每个集群的质心。
-
我们需要重复这些步骤,直到收敛发生。
随机森林
它是一种监督分类算法。随机森林算法的优点是它可以用于分类和回归类问题。基本上它是决策树(即森林)的集合,或者你可以说决策树的集合。随机森林的基本概念是每棵树都给出一个分类,森林从中选择最佳分类。以下是随机森林算法的优点
-
随机森林分类器可用于分类和回归任务。
-
他们可以处理缺失的值。
-
即使我们在森林中有更多的树木,它也不会过度适应模型。

![[翻译] Backpressure explained — the resisted flow of data through software-爱站程序员基地](https://aiznh.com/wp-content/uploads/2021/05/2-220x150.jpeg)

