 爱站程序员基地
爱站程序员基地最近在做公司项目的自动化接口测试,在现有几个小框架的基础上,反复研究和实践,搭建了新的测试框架。利用业余时间,把框架总结了下来。
AIM框架介绍
AIM,是Automatic Interface Monitoring的简称,即自动化接口监测。是一种基于python unittest的自动化接口测试框架。
设计思想
框架根据python语言的特点,结合了面向对象和面向函数编程。
以高效编程为主要目的,避免为了封装而封装。轻配置,重编码。
接口测试的主要处理对象是参数。如果完全进行数据与代码的分离,就会造成变量,传参的冗余,降低编程效率。
于是从不做数据与代码分离出发,对于需要复用的参数,提取到类之外,视需要进行数据与代码的分离。
做到有的放矢。兼顾效率和复用性,迭代分离,更具实用性。
目录结构
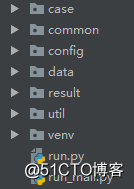
case:测试用例
common:公共函数,全局变量
config:配置路径等
data:数据文件
result:测试结果
util:工具类
run.py:用例执行入口
run_mail.py:执行后自动发送邮件入口
case
BaseCase
所有Case的基类。
封装了requests库的post和get函数req,用于发送请求。
调用assertEqual等方法,封装了用例的断言。比如检查接口返回flag,检查接口状态200,检查值相等。
项目Case
测试系统的用例。按模块分别建立文件编写脚本。
Env.py:环境配置,包括url处理,登录对象login实例(用户名、密码),数据库对象dao实例(数据库连接)。
Public.py:公共模块。存放本系统公共的变量、函数、用例等。
common
Func.py:公共函数,比如获取时间日期,获取随机数,处理参数。
Login.py:登录模块,属于各系统通用,故放于此目录下。包括密码加密,验证码处理,强制登录。
Var.py:全局变量。比如token。
config
RelativePath.py:配置目录、文件的相对路径。
data
echarts数据存储csv文件,项目接口清单等。
result
log:日志。logging实现。支持输出到文件和打印控制台。文件暂时使用较少,主要打印控制台便于调试。
接口调用记录:输出每个测试方法调用接口的记录,包括参数、响应、耗时等。
自动化测试报告:HTMLTestRunner.py实现的html页面报告。
util
AutoCode.py:自动生成结构化测试代码。
CSV.py:csv相关函数封装。比如输出接口调用记录。
Excel.py:读取和存储excel文件。
Format.py:格式化。比如把浏览器复制的参数格式化为代码中带有缩进的json。
HTMLTestRunner.py:用于输出自动化测试报告。
Log.py:封装日志方法。
Mysql.py:数据库相关操作。
Parewise.py:结对测试。一种测试技术,后文详述。
Request.py:核心工具,封装接口发送请求。
Mail.py:发送邮件。
run.py
执行测试用例入口,可以选择执行一个或多个系统,也可以执行一个系统中一个或多个模块。
核心模块
BaseCase.req
通过requests封装的发送接口请求的方法。
定义在BaseCase类的内部。
| 参数 | 说明 |
|---|---|
| p | 将url、headers、body、method统一封装到一个json里面进行处理。 |
| method=\’post\’ | 默认为post方法。接口以post居多。 |
| jsondata=\’json\’ | 默认json参数。post方法的json或data,纯json使用json参数即可。对于receive_json这种dict,采用data参数。 |
| loglevel=3 | 默认为3。日志级别,输出请求、响应信息到控制台或接口调用记录.csv。 |
| rtext=None | 一些get请求会返回html或pdf,在控制台或csv文件中影响显示,可以指定文本进行替换。 |
发送请求,并计算耗时:
start = time.clock()if method == \'post\': # 关闭SSL认证if jsondata == \'json\':r = self.timeoutTry(\"requests.post(p[\'url\'], headers=p[\'headers\'], json=p[\'body\'], verify=False)\", p)elif jsondata == \'data\':r = self.timeoutTry(\"requests.post(p[\'url\'], headers=p[\'headers\'], data=p[\'body\'], verify=False)\", p)else:print(\'jsondata错误\')elif method == \'get\':r = self.timeoutTry(\"requests.get(p[\'url\'], headers=p[\'headers\'], params=p[\'body\'])\", p)else:print(\'method错误\')end = time.clock()elapsed = decimal.Decimal(\"%.2f\" % float(end - start))
其中的self.timeoutTry是为了处理响应超时,会在后续博文中介绍。
Parewise
结对测试。接口参数一般是多个,于是比较适合采用parewise进行用例设计。
parewaise的概念可以百度一下。
大概意思就是,大多数的bug都是条件的两两组合造成的,parewise就是针对两两组合的情况,设计测试用例。
算法为,如果某一组用例的组合结果,在其他组合中均出现,就删除该组用例,从而精简用例。
windows下有微软的PICT,txt文件录入参数后,命名行执行,就出来结果了。
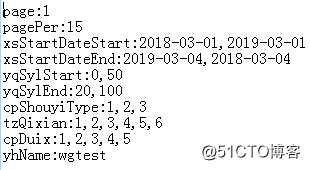
比如参数
执行后结果,只有31条,精简了很多。
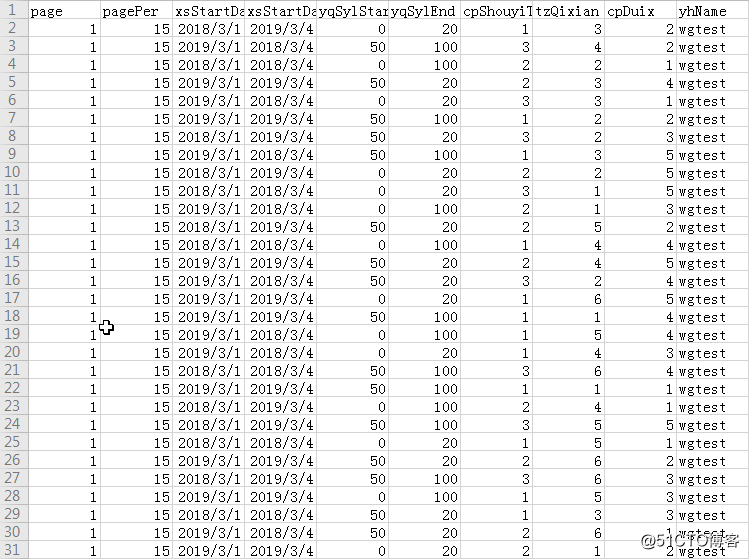
这个基本上一秒就出来结果了。
我自己参考网上算法写的,就要慢的多。
估计后面有时间了再看看能不能调优。
parewise算法:
cp = [] # 笛卡尔积s = [] # 两两拆分for x in eval(\'itertools.product\' + str(tuple(param_list))):cp.append(x)s.append([i for i in itertools.combinations(x, 2)])del_row = []s2 = copy.deepcopy(s)for i in range(len(s)): # 对每个进行匹配t = 0for j in range(len(s[i])): # 判断所有同时都存在其他中 且位置相同for i2 in [x for x in range(len(s2)) if s2[x] != s[i]]: # 其他 只比对有效flag = Falsefor j2 in range(len(s2[i2])):if s[i][j] == s2[i2][j2] and j == j2:t = t + 1flag = Truebreakif flag:breakif t == len(s[i]):del_row.append(i)s2.remove(s[i])return [cp[i] for i in range(len(cp)) if i not in del_row]
网上的例子是用的index函数。在我写过程中,发现这里有个坑。比如list中存在相同元素,就始终返回前一个匹配的索引,结果就会有问题。我就完全避免了index函数。不知道哪个是对的,目前满足使用需要,将就着用了。有点小尴尬。
Case
BaseCase断言:
def checkFlag(self, p, r):\"\"\"预期,实际\"\"\"err = str([p[\'url\'], p[\'body\'], r.text])try:b = Falseif (r.json()[\'flag\'] in [1, \'1\', \'\', None, \'statistic_by_result\', 0,\"0\", \'struct_product\', \'v_select_jz_single\']or r.json()[\'message\'] in (\"暂无数据\", \"未查询到数据\")):b = Trueself.assertEqual(True, b, msg=err)except (json.JSONDecodeError, KeyError): # 1.返回的不是json,比如下载、404 2.无flagself.assertEqual(200, r.status_code, msg=err)
最简单的一个测试用例:
from case.PyPlatform2_0_2.Public import *class Home(BaseCase):\"\"\"首页\"\"\"def setUp(self):log(testname(self.__repr__()) + \'\\n\')record([testname(self.__repr__())])def test(self):\"\"\"xxx\"\"\"self.req({\"url\": full_url(\"xxx\"),\"body\": {}})
setup,输出日志。
Token
因为公司登陆用的token,跟cookie类似,保留登陆状态,避免重复登陆。
如何处理token也是框架设计的一个要点。
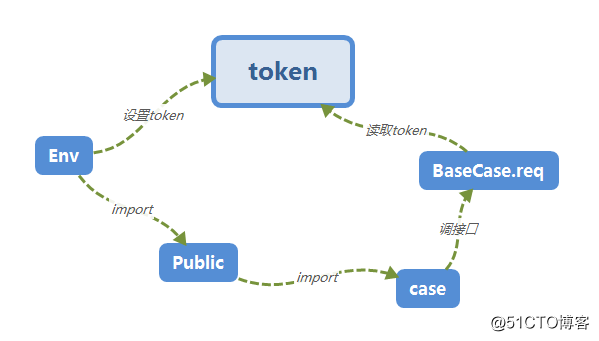
Env设置token,因为每个系统的登陆参数值都不一样。
Var.token = login.get_token()
BaseCase.req在每次请求时获取token,从而免登录。
if \"headers\" not in p.keys():p[\'headers\'] = {\'token\': \'\'}p[\'headers\'][\'token\'] = Var.token
CSV
写文件:
if not os.path.exists(path):f = open(path, \'a\', newline=\'\')a = csv.writer(f)a.writerow(title)f.close()f = open(path, \'a\', newline=\'\')a = csv.writer(f)try:a.writerow(d)except UnicodeEncodeError:d[4] = \"Unicode隐藏\" # responsea.writerow(d)f.close()if get_file_size(path) >= 50 * 1024 * 1024: # 超过50M删除文件os.remove(path)record(title)
traceback自动生成文件名:
def _sys_name():t = str(traceback.extract_stack())b = Truefor x in os.listdir(case_dir):if x not in [\"BaseCase.py\", \"__pycache__\"]:if x in t:return x + \"接口调用记录\" + current_date() + \".csv\"if b:print(\"request找不到sysname\")print(t)
HTMLTestRunner
根据通用的版本,也是参考网上一些现有的美化代码,综合了一下,根据自己需求做了改造。
近20交易日测试通过率
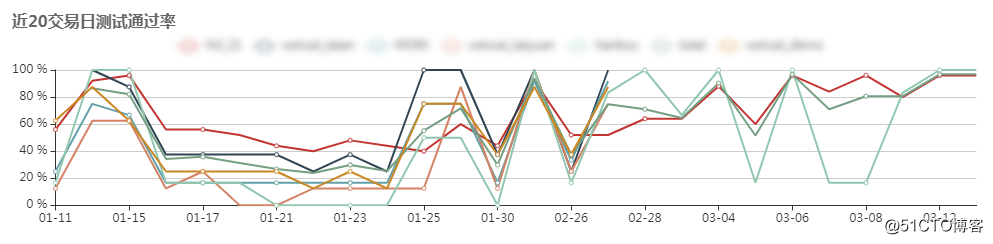
加了一个echarts,把最近20交易日的测试通过率,通过折线走势图的方式展示出来。监测系统稳定性。
数据存放和读取在data目录的csv文件中。
统计表格
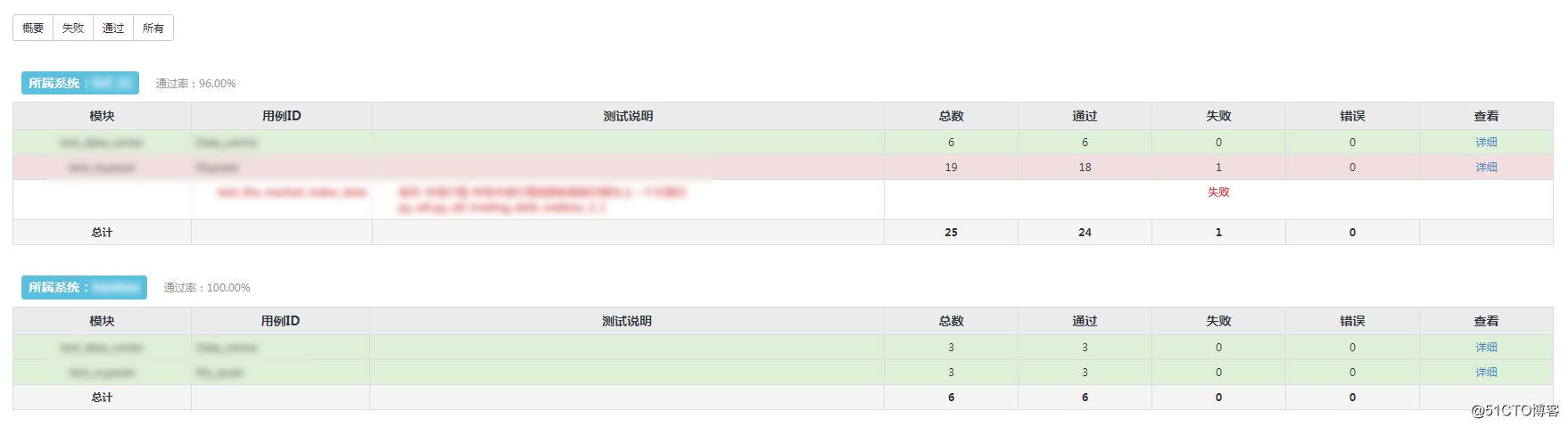
按项目进行分组统计,增加测试说明一列,按颜色区别测试结果状态,可点击查看详细描述和错误信息。
同时优化了整体的样式效果。
排序:
# 按照通过率从小到大排序pa***ate_value = []for key in pa***ate:if key != \'total\':pa***ate_value.append(float(pa***ate[key].replace(\'%\', \'\')))pa***ate_value.sort()
保存折线图数据:
today = datetime.datetime.now().strftime(\'%Y-%m-%d\')if \'--\' not in names: # 跑单个系统不存if dao_is_trade_date(today): # 非交易日不存with open(self.rct20_path, \"r\") as f: # 读取数据lines = csv.reader(f)lines = list(lines)for lin in lines:lin[0] = lin[0].replace(\'月\', \'-\')lin[0] = lin[0].replace(\'日\', \'\')rct_data = lines# print(rct_data)nowdate = datetime.datetime.now().strftime(\'%m-%d\')# 如果有重复日期,先删l = len(rct_data)while l != 0 and nowdate == rct_data[l - 1][0]:rct_data.pop(l - 1)l = len(rct_data)for pt in self.pa***ate_tl:n = pt[0]v = pt[1]row = []row.append(str(nowdate))row.append(str(n))row.append(str(v).replace(\'%\', \'\'))rct_data.append(row)# 只存近20条row_20 = len(names) * 20if len(rct_data) > row_20: # 超过20条for i in range(0, len(names)):rct_data.pop(0)with open(self.rct20_path, \'w\', newline=\'\') as f:writer = csv.writer(f)writer.writerows(rct_data)
拼接折线图数据用于展示:
while ri < len(rct_data): # 遍历 ->s_datascan = []while ri < len(rct_data) and rct_data[ri][0] == trade_date[di]:s_data[rct_data[ri][1]].append(rct_data[ri][2])scan.append(rct_data[ri][1])ri += 1chg = list(set(names) ^ set(scan)) # 差集for c in chg:s_data[c].append(\'--\') # 增加/减少的项目,为\'--\'di += 1series = [] # 系列序列s_names = s_data.keys()for k in s_names:s = {} # 单个系列s[\'name\'] = ks[\'type\'] = \'line\'if s_data != {}:s[\'data\'] = s_data[k]series.append(s)
这部分代码是很久之前写的了,代码应该是不够简洁、高效、规范滴,是可以优化滴。偷了懒没有重构了。
用例设计
| 测试类型 | 描述 |
|---|---|
| 冒烟测试 | 所有接口写单独的test,确保调用正常。 |
| 全选测试 | 将所有参数尽可能多的全选上,调用接口。 一定程序上可以弥补结对测试的不足。 |
| 结对测试 | 如前文所述,关注两两组合的情况。 |
参数值,部分采用随机数。也视需求,从数据库或其他接口获取数据。
结束语
第一次写技术博客。
马上工作5年。
算是一个尝试吧。

![[翻译] Backpressure explained — the resisted flow of data through software-爱站程序员基地](https://aiznh.com/wp-content/uploads/2021/05/1-220x150.jpeg)

