爱站程序员基地
爱站程序员基地spark简介
快速、通用、可扩展的大数据分析引擎
(Java, Scala, Python, R and sql)
既可以做离线计算,也可以做实时计算
提供了统一的大数据处理解决方案
可以运行在各种资源调度框架和读写多种数据源
支持的多种部署方案
丰富的数据源支持。
1.MR只能做离线计算,如果实现复杂计算逻辑,一个MR搞不定,就需要将多个MR按照先后顺序连成一串,
一个MR计算完成后会将计算结果写入到HDFS中,下一个MR将上一个MR的输出作为输入,
这样就要频繁读写HDFS,网络IO和磁盘IO会成为性能瓶颈。从而导致效率低下。
2.既可以做离线计算,有可以做实时计算,提供了抽象的数据集(RDD、Dataset、DataFrame、DStream)
有高度封装的API,算子丰富,并且使用了更先进的DAG有向无环图调度思想,
可以对执行计划优化后在执行,并且可以数据可以cache到内存中进行复用。
注意:MR和Spark在Shuffle时数据都落本地磁盘
2020年6月18日发布的spqrk3.0在Python和SQL方面很大扩展改进,特别是易用性上
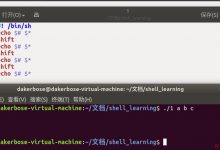
spark体验
/bin/spark_shell
sc.textFile(“file:///root/1.txt”).flatMap(.split(\” \”))
.map((, 1)).reduceByKey(+).sortBy(_._2, false).collect
spark框架体系
Master:是一个Java进程,接受Worker的注册信息和心跳,移除异常超时的Worker,
接受客户端提交的任务,负责资源调度,命令Worker启动Executor.
Worker:是一个Java进程,负责管理当前节点的资源关联,向Master注册并定期发送心跳,
负责启动Executor,并监控Executor的状态.
SparkSubmit:是一个Java进程,负责向Master提交任务.
Driver:是很多类的统称,可以认为SparkContext就是Driver,client模式Driver运行在SparkSubmit进程中,
cluster模式单独运行在一个进程中,负责将用户编写的代码转成Tasks,然后调度到Executor中执行
并监控Task的状态和执行进度。
Executor :是一个Java进程,负责执行Driver端生成的Task,将Task放入线程中运行。
spark安装部署
安装spark3.0时,要求scala版本高于或等于2.12
linux 安装前提 安装好JDK
下载spark安装包 官网
上传spark安装包到Linux服务器上
解压spark安装包
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/apps/
进入到spark按照包目录并将conf目录下的spark-env.sh.template重命名为spark-env.sh
vi spark-env.sh 添加二行代码
export JAVA_HOME=/opt/apps/jdk x.xxx.xx/
export SPARK_MASTER_HOST=node-1.51doit.com
将conf目录下的slaves.template重命名为slaves并修改,指定Worker的所在节点
linux201 linux202 linux203
将配置好的spark拷贝到其他节点
scp -r spark-3.0.0-bin-hadoop3.2 linux202:PWDscp−rspark−3.0.0−bin−hadoop3.2linux203:PWDscp -r spark-3.0.0-bin-hadoop3.2 linux203:PWDscp−rspark−3.0.0−bin−hadoop3.2linux203:PWD
standalone模式是Spark自带的分布式集群模式,不依赖其他的资源调度框架
启动spark
sbin/start-all.sh
sbin/start-all.sh
linux201:7077 spark进程进行rpc通信的端口号
linux201:8080 web管理spark界面
standalone模式参数说明(使用不多,生产模式通常使用 onyarn模式)
conf/spark-env.sh
export SPARK_WORKER_MEMORY=3g 大小
export SPARK_WORKER_CORES=3 核数(并非计算机核数)
Spark-shell的使用
spark-shell是spark中的交互式命令行客户端,可以在spark shell中使用scala编写spark程序
启动后默认创建了SparkContext,别名为sc
启动命令
运行在本地进程
bin/spark-shell
info中master=local[*] (表示运行扎起本地,并未运行在集群上)
运行在集群
前提,启动HDFS /hadoop-3.xxx/sbin/start-dfs.sh(start-all.sh)
先将wordCount放在HDFS的wordCount文件夹下
bin/spark-shell –master spark://linux201:7077
./spark-shell –master spark://linux201:7077 –executor-memory 2g –total-executor-cores 4
./spark-shell –master spark://linux201:7077 –executor-memory 1g –total-executor-cores 7 –dirver-memory 2g
val lines = sc.textFile(\"hdfs://linux201:9000/wordCount\")val words = lines.flatMap(_.split(\" \"))val wordAndOne = words.map((_, 1))val reduced = wordAndOne.reduceByKey(_+_)reduced.sortBy(_._2, false).collectreduced.saveAsTextFile(\"hdfs://linux201:9000/out2\")
使用Scala编写WordCount程序
建Maven项目,导入依赖
<properties><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><scala.version>2.12.11</scala.version><spark.version>3.0.0</spark.version><hadoop.version>3.2.1</hadoop.version><encoding>UTF-8</encoding></properties><dependencies><!-- 导入scala的依赖 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- 导入spark的依赖,core指的是RDD编程API --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version><!-- 剔除重复的包 --></dependency></dependencies><build><pluginManagement><plugins><!-- 编译scala的插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version></plugin><!-- 编译java的插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version></plugin></plugins></pluginManagement><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>scala-test-compile</id><phase>process-test-resources</phase><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><executions><execution><phase>compile</phase><goals><goal>compile</goal></goals></execution></executions></plugin><!-- 打jar插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.4.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters></configuration></execution></executions></plugin></plugins></build>
用scala写程序:
/*** 1创建SparkContext* 2创建RDD* 3调用RDD的Transformation方法* 4调用Action* 5释放资源*/object WordCount {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName(\"WordCount\")//创建SparkContext,使用SparkContext创建RDDval sc: SparkContext = new SparkContext(conf)//spark写spark程序,对RDD编程,调用它封装的API 使用SparkContext创建RDDval lines: RDD[String] = sc.textFile(args(0))//Transformation 开始//切分压平val words: RDD[String] = lines.flatMap(_.split(\" \"))//将单词和1 组合放在元组中val wordsAndOne: RDD[(String, Int)] = words.map((_, 1))//分组聚合.reduceBykey 可以先局部聚合再全局聚合val reduced: RDD[(String, Int)] = wordsAndOne.reduceByKey(_ + _)//排序val sorted: RDD[(String, Int)] = reduced.sortBy(_._2, false)//Tranformation 结束//调用Action将计算结果保存到HDFS中sorted.saveAsTextFile(args(1))//释放资源sc.stop()}}
Maven-Lifecycle-package双击打包以后将包上传到linux
运行jar包
/bin/spark-submit –master spark://linux201:7077
./spark-submit –master spark://linux201:7077 –executor-memory 1g
–total-executor-cores 3 –class WordCount /doit15/doit15-spark-1.0-SNAPSHOT.jar
hdfs://linux201:9000/wordCount/1.txt hdfs://linux201:9000/out
参数说明:
–master 指定masterd地址和端口,协议为spark://,端口是RPC的通信端口
–executor-memory 指定每一个executor的使用的内存大小
–total-executor-cores指定整个application总共使用了cores
–class 指定程序的main方法全类名
jar包路径 args0 args1
用Java写程序
public class JavaWordCount {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName(\"JavaWordCount\");JavaSparkContext jsc = new JavaSparkContext(conf);//创建RDDJavaRDD<String> lines = jsc.textFile(args[0]);//切分压平JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {String[] fields = line.split(\" \");return Arrays.asList(fields).iterator();}});//将单词和1组合在一起.分组聚合JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return Tuple2.apply(word, 1);}});//为了更好地调用ReduceByKey方法,需要将RDD变成PairRDDJavaPairRDD<String, Integer> reduced = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}});//因为排序sortBy只能对key进行排序,无法对value进行排序,所以 这步翻转 方便排序JavaPairRDD<Integer, String> swapped = reduced.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {@Overridepublic Tuple2<Integer, String> call(Tuple2<String, Integer> tp) throws Exception {return tp.swap();}});//调用排序方法JavaPairRDD<Integer, String> sorted = swapped.sortByKey(false);//再次调转顺序JavaPairRDD<String, Integer> result = sorted.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(Tuple2<Integer, String> tp2) throws Exception {return tp2.swap();}});//将数据保存在HDFS中result.saveAsTextFile(args[1]);//释放资源jsc.stop();}}
用JavaLambda表达式写程序
public class JavaLambdaWordCount {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName(\"JavaLambdaWordCount\");JavaSparkContext jsc = new JavaSparkContext(conf);//创建RDDJavaRDD<String> lines = jsc.textFile(args[0]);//切分压平JavaRDD<String> words = lines.flatMap(line -> Arrays.stream(line.split(\" \")).iterator());//将单词和1组合JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(w -> Tuple2.apply(w, 1));//聚合JavaPairRDD<String, Integer> reduced = wordAndOne.reduceByKey((a, b) -> a + b);//颠倒顺序JavaPairRDD<Integer, String> swappd = reduced.mapToPair(tp -> tp.swap());//排序JavaPairRDD<Integer, String> sorted = swappd.sortByKey(false);//颠倒排序JavaPairRDD<String, Integer> result = sorted.mapToPair(sp -> sp.swap());//将数据保存到HDFS中result.saveAsTextFile(args(1));//释放资源jsc.stop();}}
Debug 本地模式运行,就是一个Java进程,程序不会提交到集群中执行
在conf后加setMaster(“local[*]”) 在本地 多线程运行 模拟集群 用当前机器可用逻辑核数量
在程序中打断点来debug,找到问题所在处
/*** 1创建SparkContext* 2创建RDD* 3调用RDD的Transformation方法* 4调用Action* 5释放资源*/object WordCountLocalDebug {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName(\"WordCount\").setMaster(\"local[*]\")//创建SparkContext,使用SparkContext创建RDDval sc: SparkContext = new SparkContext(conf)//spark写spark程序,对RDD编程,调用它封装的API 使用SparkContext创建RDDval lines: RDD[String] = sc.textFile(args(0))//Transformation 开始//切分压平val words: RDD[String] = lines.flatMap(line =>{val arr = line.split(\" \")//打点arr})//将单词和1 组合放在元组中val wordsAndOne: RDD[(String, Int)] = words.map(w => {(w, 1)//打点})//分组聚合.reduceBykey 可以先局部聚合再全局聚合val reduced: RDD[(String, Int)] = wordsAndOne.reduceByKey(_ + _)//排序val sorted: RDD[(String, Int)] = reduced.sortBy(_._2, false)//Tranformation 结束//调用Action将计算结果保存到HDFS中sorted.saveAsTextFile(args(1))//释放资源sc.stop()}}
传参 从本地读 本地导出 成功
C:\\Users\\hanke\\Desktop\\words.txt C:\\Users\\hanke\\Desktop\\out
问题待解决: 从HDFS读取 本地导出
传参后出现问题
hdfs://linux201:9000 /wordCount C:\\Users\\hanke\\Desktop\\out
20/07/07 01:38:08 INFO SparkContext: Created broadcast 0 from textFile at WordCountLocalDebug.scala:21
Exception in thread “main” org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://linux201:9000
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:287)