爱站程序员基地
爱站程序员基地一. C语言概述
欢迎大家来到c语言的世界,c语言是一种强大的专业化的编程语言。
程序员必备硬核资料,点击下载
1.1 C语言的起源
贝尔实验室的Dennis Ritchie在1972年开发了C,当时他正与ken Thompson一起设计UNIX操作系统,然而,C并不是完全由Ritchie构想出来的。它来自Thompson的B语言。
1.2 使用C语言的理由
在过去的几十年中,c语言已成为最流行和最重要的编程语言之一。它之所以得到发展,是因为人们尝试使用它后都喜欢它。过去很多年中,许多人从c语言转而使用更强大的c++语言,但c有其自身的优势,仍然是一种重要的语言,而且它还是学习c++的必经之路。
-
高效性。c语言是一种高效的语言。c表现出通常只有汇编语言才具有的精细的控制能力(汇编语言是特定cpu设计所采用的一组内部制定的助记符。不同的cpu类型使用不同的汇编语言)。如果愿意,您可以细调程序以获得最大的速度或最大的内存使用率。
-
可移植性。c语言是一种可移植的语言。意味着,在一个系统上编写的c程序经过很少改动或不经过修改就可以在其他的系统上运行。
-
强大的功能和灵活性。c强大而又灵活。比如强大灵活的UNIX操作系统便是用c编写的。其他的语言(Perl、Python、BASIC、Pascal)的许多编译器和解释器也都是用c编写的。结果是当你在一台Unix机器上使用Python时,最终由一个c程序负责生成最后的可执行程序。
1.3 C语言标准
1.3.1 K&R C
起初,C语言没有官方标准。1978年由美国电话电报公司(AT&T)贝尔实验室正式发表了C语言。布莱恩•柯林汉(Brian Kernighan) 和 丹尼斯•里奇(Dennis Ritchie� 出版了一本书,名叫《The C Programming Language》。这本书被 C语言开发者们称为K&R,很多年来被当作 C语言的非正式的标准说明。人们称这个版本的 C语言为K&R C。
K&R C主要介绍了以下特色:结构体(struct)类型;长整数(long int)类型;无符号整数(unsigned int)类型;把运算符=+和=-改为+=和-=。因为=+和=-会使得编译器不知道使用者要处理i = -10还是i =- 10,使得处理上产生混淆。
即使在后来ANSI C标准被提出的许多年后,K&R C仍然是许多编译器的最准要求,许多老旧的编译器仍然运行K&R C的标准。
1.3.2 ANSI C/C89标准
1970到80年代,C语言被广泛应用,从大型主机到小型微机,也衍生了C语言的很多不同版本。1983年,美国国家标准协会(ANSI)成立了一个委员会X3J11,来制定 C语言标准。
1989年,美国国家标准协会(ANSI)通过了C语言标准,被称为ANSI X3.159-1989 "Programming Language C"。因为这个标准是1989年通过的,所以一般简称C89标准。有些人也简称ANSI C,因为这个标准是美国国家标准协会(ANSI)发布的。
1990年,国际标准化组织(ISO)和国际电工委员会(IEC)把C89标准定为C语言的国际标准,命名为ISO/IEC 9899:1990 – Programming languages — C[5] 。因为此标准是在1990年发布的,所以有些人把简称作C90标准。不过大多数人依然称之为C89标准,因为此标准与ANSI C89标准完全等同。
1994年,国际标准化组织(ISO)和国际电工委员会(IEC)发布了C89标准修订版,名叫ISO/IEC 9899:1990/Cor 1:1994[6] ,有些人简称为C94标准。
1995年,国际标准化组织(ISO)和国际电工委员会(IEC)再次发布了C89标准修订版,名叫ISO/IEC 9899:1990/Amd 1:1995 – C Integrity[7] ,有些人简称为C95标准。
1.3.3 C99标准
1999年1月,国际标准化组织(ISO)和国际电工委员会(IEC)发布了C语言的新标准,名叫ISO/IEC 9899:1999 – Programming languages — C ,简称C99标准。这是C语言的第二个官方标准。
例如:
-
增加了新关键字 restrict,inline,_Complex,_Imaginary,_Bool
-
支持 long long,long double _Complex,float _Complex 这样的类型
-
支持了不定长的数组。数组的长度就可以用变量了。声明类型的时候呢,就用 int a[*] 这样的写法。不过考虑到效率和实现,这玩意并不是一个新类型。
二、内存分区
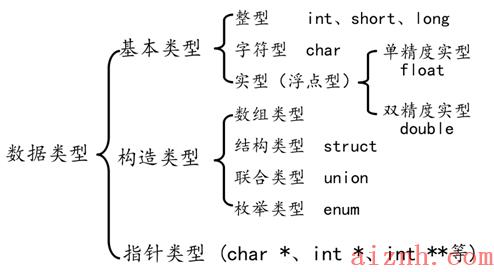
2.1 数据类型
2.1.1 数据类型概念
什么是数据类型?为什么需要数据类型? 数据类型是为了更好进行内存的管理,让编译器能确定分配多少内存。
我们现实生活中,狗是狗,鸟是鸟等等,每一种事物都有自己的类型,那么程序中使用数据类型也是来源于生活。
当我们给狗分配内存的时候,也就相当于给狗建造狗窝,给鸟分配内存的时候,也就是给鸟建造一个鸟窝,我们可以给他们各自建造一个别墅,但是会造成内存的浪费,不能很好的利用内存空间。
我们在想,如果给鸟分配内存,只需要鸟窝大小的空间就够了,如果给狗分配内存,那么也只需要狗窝大小的内存,而不是给鸟和狗都分配一座别墅,造成内存的浪费。
当我们定义一个变量,a = 10,编译器如何分配内存?计算机只是一个机器,它怎么知道用多少内存可以放得下10?
所以说,数据类型非常重要,它可以告诉编译器分配多少内存可以放得下我们的数据。
狗窝里面是狗,鸟窝里面是鸟,如果没有数据类型,你怎么知道冰箱里放得是一头大象!
数据类型基本概念:
-
类型是对数据的抽象;
-
类型相同的数据具有相同的表示形式、存储格式以及相关操作;
-
程序中所有的数据都必定属于某种数据类型;
-
数据类型可以理解为创建变量的模具: 固定大小内存的别名;
2.1.2 数据类型别名

typedef unsigned int u32;typedef struct _PERSON{ char name[64]; int age;}Person;void test(){ u32 val; //相当于 unsigned int val; Person person; //相当于 struct PERSON person;}
2.1.3 void数据类型
void字面意思是”无类型”,void* 无类型指针,无类型指针可以指向任何类型的数据。
void定义变量是没有任何意义的,当你定义void a,编译器会报错。
void真正用在以下两个方面:
-
对函数返回的限定;
-
对函数参数的限定;
//1. void修饰函数参数和函数返回void test01(void){ printf("hello world");}//2. 不能定义void类型变量void test02(){ void val; //报错}//3. void* 可以指向任何类型的数据,被称为万能指针void test03(){ int a = 10; void* p = NULL; p = &a; printf("a:%d\\n",*(int*)p); char c = 'a'; p = &c; printf("c:%c\\n",*(char*)p);}//4. void* 常用于数据类型的封装void test04(){ //void * memcpy(void * _Dst, const void * _Src, size_t _Size);}
2.1.4 sizeof 操作符
sizeof 是 c语言中的一个操作符,类似于++、–等等。sizeof 能够告诉我们编译器为某一特定数据或者某一个类型的数据在内存中分配空间时分配的大小,大小以字节为单位。
基本语法:
sizeof(变量);sizeof 变量;sizeof(类型);
sizeof 注意点:
-
sizeof返回的占用空间大小是为这个变量开辟的大小,而不只是它用到的空间。和现今住房的建筑面积和实用面积的概念差不多。所以对结构体用的时候,大多情况下就得考虑字节对齐的问题了;
-
sizeof返回的数据结果类型是unsigned int;
-
要注意数组名和指针变量的区别。通常情况下,我们总觉得数组名和指针变量差不多,但是在用sizeof的时候差别很大,对数组名用sizeof返回的是整个数组的大小,而对指针变量进行操作的时候返回的则是指针变量本身所占得空间,在32位机的条件下一般都是4。而且当数组名作为函数参数时,在函数内部,形参也就是个指针,所以不再返回数组的大小;
//1. sizeof基本用法void test01(){ int a = 10; printf("len:%d\\n", sizeof(a)); printf("len:%d\\n", sizeof(int)); printf("len:%d\\n", sizeof a);}//2. sizeof 结果类型void test02(){ unsigned int a = 10; if (a - 11 < 0){ printf("结果小于0\\n"); } else{ printf("结果大于0\\n"); } int b = 5; if (sizeof(b) - 10 < 0){ printf("结果小于0\\n"); } else{ printf("结果大于0\\n"); }}//3. sizeof 碰到数组void TestArray(int arr[]){ printf("TestArray arr size:%d\\n",sizeof(arr));}void test03(){ int arr[] = { 10, 20, 30, 40, 50 }; printf("array size: %d\\n",sizeof(arr)); //数组名在某些情况下等价于指针 int* pArr = arr; printf("arr[2]:%d\\n",pArr[2]); printf("array size: %d\\n", sizeof(pArr)); //数组做函数函数参数,将退化为指针,在函数内部不再返回数组大小 TestArray(arr);}
2.1.5 数据类型总结
-
数据类型本质是固定内存大小的别名,是个模具,C语言规定:通过数据类型定义变量;
-
数据类型大小计算(sizeof);
-
可以给已存在的数据类型起别名typedef;
-
数据类型的封装(void 万能类型);
2.2 变量
2.1.1 变量的概念
既能读又能写的内存对象,称为变量;
若一旦初始化后不能修改的对象则称为常量。
变量定义形式: 类型 标识符, 标识符, … , 标识符
2.1.2 变量名的本质
-
变量名的本质:一段连续内存空间的别名;
-
程序通过变量来申请和命名内存空间 int a = 0;
-
通过变量名访问内存空间;
-
不是向变量名读写数据,而是向变量所代表的内存空间中读写数据;
修改变量的两种方式:
void test(){ int a = 10; //1. 直接修改 a = 20; printf("直接修改,a:%d\\n",a); //2. 间接修改 int* p = &a; *p = 30; printf("间接修改,a:%d\\n", a);}
2.3 程序的内存分区模型
2.3.1 内存分区
2.3.1.1 运行之前
我们要想执行我们编写的c程序,那么第一步需要对这个程序进行编译。 1)预处理:宏定义展开、头文件展开、条件编译,这里并不会检查语法
2)编译:检查语法,将预处理后文件编译生成汇编文件
3)汇编:将汇编文件生成目标文件(二进制文件)
4)链接:将目标文件链接为可执行程序
代码区
存放 CPU 执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指t令。另外,代码区还规划了局部变量的相关信息。
全局初始化数据区/静态数据区(data段)
该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和t)和常量数据(如字符串常量)。
未初始化数据区(又叫 bss 区)
存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为 0 或者空(NULL)。
总体来讲说,程序源代码被编译之后主要分成两种段:程序指令(代码区)和程序数据(数据区)。代码段属于程序指令,而数据域段和.bss段属于程序数据。
那为什么把程序的指令和程序数据分开呢?
-
程序被load到内存中之后,可以将数据和代码分别映射到两个内存区域。由于数据区域对进程来说是可读可写的,而指令区域对程序来讲说是只读的,所以分区之后呢,可以将程序指令区域和数据区域分别设置成可读可写或只读。这样可以防止程序的指令有意或者无意被修改;
-
当系统中运行着多个同样的程序的时候,这些程序执行的指令都是一样的,所以只需要内存中保存一份程序的指令就可以了,只是每一个程序运行中数据不一样而已,这样可以节省大量的内存。比如说之前的Windows Internet Explorer 7.0运行起来之后, 它需要占用112 844KB的内存,它的私有部分数据有大概15 944KB,也就是说有96 900KB空间是共享的,如果程序中运行了几百个这样的进程,可以想象共享的方法可以节省大量的内存。
2.3.1.1 运行之后
程序在加载到内存前,代码区和全局区(data和bss)的大小就是固定的,程序运行期间不能改变。然后,运行可执行程序,操作系统把物理硬盘程序load(加载)到内存,除了根据可执行程序的信息分出代码区(text)、数据区(data)和未初始化数据区(bss)之外,还额外增加了栈区、堆区。
代码区(text segment)
加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。
未初始化数据区(BSS)
加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)的生存周期为整个程序运行过程。
全局初始化数据区/静态数据区(data segment)
加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的生存周期为整个程序运行过程。
栈区(stack)
栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
堆区(heap)
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。

2.3.2 分区模型
2.3.2.1 栈区
由系统进行内存的管理。主要存放函数的参数以及局部变量。在函数完成执行,系统自行释放栈区内存,不需要用户管理。
#char* func(){ char p[] = "hello world!"; //在栈区存储 乱码 printf("%s\\n", p); return p;}void test(){ char* p = NULL; p = func(); printf("%s\\n",p); }
2.3.2.2 堆区
由编程人员手动申请,手动释放,若不手动释放,程序结束后由系统回收,生命周期是整个程序运行期间。使用malloc或者new进行堆的申请。
char* func(){ char* str = malloc(100); strcpy(str, "hello world!"); printf("%s\\n",str); return str;}void test01(){ char* p = NULL; p = func(); printf("%s\\n",p);}void allocateSpace(char* p){ p = malloc(100); strcpy(p, "hello world!"); printf("%s\\n", p);}void test02(){ char* p = NULL; allocateSpace(p); printf("%s\\n", p);}

堆分配内存API:
#include <stdlib.h>void *calloc(size_t nmemb, size_t size);
功能:
在内存动态存储区中分配nmemb块长度为size字节的连续区域。calloc自动将分配的内存 置0。
参数:
nmemb:所需内存单元数量 size:每个内存单元的大小(单位:字节)
返回值:
成功:分配空间的起始地址
失败:NULL
#include <stdlib.h>void *realloc(void *ptr, size_t size);
功能:
重新分配用malloc或者calloc函数在堆中分配内存空间的大小。 realloc不会自动清理增加的内存,需要手动清理,如果指定的地址后面有连续的空间,那么就会在已有地址基础上增加内存,如果指定的地址后面没有空间,那么realloc会重新分配新的连续内存,把旧内存的值拷贝到新内存,同时释放旧内存。
参数:
ptr:为之前用malloc或者calloc分配的内存地址,如果此参数等于NULL,那么和realloc与malloc功能一致
size:为重新分配内存的大小, 单位:字节
返回值:
成功:新分配的堆内存地址
失败:NULL
void test01(){ int* p1 = calloc(10,sizeof(int)); if (p1 == NULL){ return; } for (int i = 0; i < 10; i ++){ p1[i] = i + 1; } for (int i = 0; i < 10; i++){ printf("%d ",p1[i]); } printf("\\n"); free(p1);}void test02(){ int* p1 = calloc(10, sizeof(int)); if (p1 == NULL){ return; } for (int i = 0; i < 10; i++){ p1[i] = i + 1; } int* p2 = realloc(p1, 15 * sizeof(int)); if (p2 == NULL){ return; } printf("%d\\n", p1); printf("%d\\n", p2); //打印 for (int i = 0; i < 15; i++){ printf("%d ", p2[i]); } printf("\\n"); //重新赋值 for (int i = 0; i < 15; i++){ p2[i] = i + 1; } //再次打印 for (int i = 0; i < 15; i++){ printf("%d ", p2[i]); } printf("\\n"); free(p2);}
2.3.2.3 全局/静态区
全局静态区内的变量在编译阶段已经分配好内存空间并初始化。这块内存在程序运行期间一直存在,它主要存储全局变量、静态变量和常量。
注意:
(1)这里不区分初始化和未初始化的数据区,是因为静态存储区内的变量若不显示初始化,则编译器会自动以默认的方式进行初始化,即静态存储区内不存在未初始化的变量。
(2)全局静态存储区内的常量分为常变量和字符串常量,一经初始化,不可修改。静态存储内的常变量是全局变量,与局部常变量不同,区别在于局部常变量存放于栈,实际可间接通过指针或者引用进行修改,而全局常变量存放于静态常量区则不可以间接修改。
(3)字符串常量存储在全局/静态存储区的常量区。
int v1 = 10;//全局/静态区const int v2 = 20; //常量,一旦初始化,不可修改static int v3 = 20; //全局/静态区char *p1; //全局/静态区,编译器默认初始化为NULL//那么全局static int 和 全局int变量有什么区别?void test(){ static int v4 = 20; //全局/静态区}
char* func(){ static char arr[] = "hello world!"; //在静态区存储 可读可写 arr[2] = 'c'; char* p = "hello world!"; //全局/静态区-字符串常量区 //p[2] = 'c'; //只读,不可修改 printf("%d\\n",arr); printf("%d\\n",p); printf("%s\\n", arr); return arr;}void test(){ char* p = func(); printf("%s\\n",p);}
2.3.2.4 总结
在理解C/C++内存分区时,常会碰到如下术语:数据区,堆,栈,静态区,常量区,全局区,字符串常量区,文字常量区,代码区等等,初学者被搞得云里雾里。在这里,尝试捋清楚以上分区的关系。
数据区包括:堆,栈,全局/静态存储区。
-
全局/静态存储区包括:常量区,全局区、静态区。
-
常量区包括:字符串常量区、常变量区。
-
代码区:存放程序编译后的二进制代码,不可寻址区。
可以说,C/C++内存分区其实只有两个,即代码区和数据区。
2.3.3 函数调用模型
2.3.3.1 函数调用流程
栈(stack)是现代计算机程序里最为重要的概念之一,几乎每一个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今能见到的所有计算机的语言。在解释为什么栈如此重要之前,我们先了解一下传统的栈的定义:
在经典的计算机科学中,栈被定义为一个特殊的容器,用户可以将数据压入栈中(入栈,push),也可以将压入栈中的数据弹出(出栈,pop),但是栈容器必须遵循一条规则:先入栈的数据最后出栈(First In Last Out,FILO).
在经典的操作系统中,栈总是向下增长的。压栈的操作使得栈顶的地址减小,弹出操作使得栈顶地址增大。
栈在程序运行中具有极其重要的地位。最重要的,栈保存一个函数调用所需要维护的信息,这通常被称为堆栈帧(Stack Frame)或者活动记录(Activate Record).一个函数调用过程所需要的信息一般包括以下几个方面:
-
函数的返回地址;
-
函数的参数;
-
临时变量;
-
保存的上下文:包括在函数调用前后需要保持不变的寄存器。
我们从下面的代码,分析以下函数的调用过程:
int func(int a,int b){ int t_a = a; int t_b = b; return t_a + t_b;}int main(){ int ret = 0; ret = func(10, 20); return EXIT_SUCCESS;}

程序员必备硬核资料,点击下载
2.3.3.2 调用惯例
现在,我们大致了解了函数调用的过程,这期间有一个现象,那就是函数的调用者和被调用者对函数调用有着一致的理解,例如,它们双方都一致的认为函数的参数是按照某个固定的方式压入栈中。如果不这样的话,函数将无法正确运行。
如果函数调用方在传递参数的时候先压入a参数,再压入b参数,而被调用函数则认为先压入的是b,后压入的是a,那么被调用函数在使用a,b值时候,就会颠倒。
因此,函数的调用方和被调用方对于函数是如何调用的必须有一个明确的约定,只有双方都遵循同样的约定,函数才能够被正确的调用,这样的约定被称为”调用惯例(Calling Convention)”.一个调用惯例一般包含以下几个方面:
函数参数的传递顺序和方式
函数的传递有很多种方式,最常见的是通过栈传递。函数的调用方将参数压入栈中,函数自己再从栈中将参数取出。对于有多个参数的函数,调用惯例要规定函数调用方将参数压栈的顺序:从左向右,还是从右向左。有些调用惯例还允许使用寄存器传递参数,以提高性能。
栈的维护方式
在函数将参数压入栈中之后,函数体会被调用,此后需要将被压入栈中的参数全部弹出,以使得栈在函数调用前后保持一致。这个弹出的工作可以由函数的调用方来完成,也可以由函数本身来完成。
为了在链接的时候对调用惯例进行区分,调用惯例要对函数本身的名字进行修饰。不同的调用惯例有不同的名字修饰策略。
事实上,在c语言里,存在着多个调用惯例,而默认的是cdecl.任何一个没有显示指定调用惯例的函数都是默认是cdecl惯例。比如我们上面对于func函数的声明,它的完整写法应该是:
int _cdecl func(int a,int b);
注意: cdecl不是标准的关键字,在不同的编译器里可能有不同的写法,例如gcc里就不存在_cdecl这样的关键字,而是使用__attribute_((cdecl)).

2.3.3.2 函数变量传递分析



程序员必备硬核资料,点击下载
2.3.4 栈的生长方向和内存存放方向

//1. 栈的生长方向void test01(){ int a = 10; int b = 20; int c = 30; int d = 40; printf("a = %d\\n", &a); printf("b = %d\\n", &b); printf("c = %d\\n", &c); printf("d = %d\\n", &d); //a的地址大于b的地址,故而生长方向向下}//2. 内存生长方向(小端模式)void test02(){ //高位字节 -> 地位字节 int num = 0xaabbccdd; unsigned char* p = # //从首地址开始的第一个字节 printf("%x\\n",*p); printf("%x\\n", *(p + 1)); printf("%x\\n", *(p + 2)); printf("%x\\n", *(p + 3));}