爱站程序员基地
爱站程序员基地SudokuSolver 2.1 程序实现
在 2.0 版的基础上,2.1 版在输出信息上做了一些改进,并增加了 runtil <steps> 命令,方便做实例分析。
CQuizDealer 类声明部分的修改
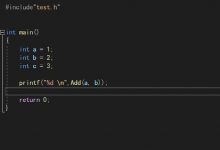
class CQuizDealer{public:...
void run(ulong tilsteps = 0);...
private:...
enum {RET_PENDING, RET_WRONG, RET_SHRUNKEN, RET_OK};...inline void incSteps() {++m_steps;}void parse();
...
run 接口增加了参数 ulong tilsteps,用于实现 runtil <steps> 命令;增加了常数 RET_SHRUNKEN 定义;增加了 ++m_steps; 语句的包装接口 incSteps,代码中统一使用 incSteps 接口给 m_steps 做加一操作。
输出信息增加 m_steps 输出
以 guess 接口为例:
void CQuizDealer::guess(u8 guessIdx){incSteps();++m_guessLevel;m_guessPos = guessIdx;m_guessValPos = 1;pushIn(guessIdx, 1);printf(\"%u) Guess [%d,%d] level %d at 1 out of %d\\n\", m_steps, (int)(guessIdx / 9 + 1), (int)(guessIdx % 9 + 1), (int)m_guessLevel, (int)m_seqCell[guessIdx].candidates[0]);if (!shift(guessIdx, 1))nextGuess();}
showQuiz 输出信息优化
void CQuizDealer::showQuiz(){...
u8 foremost = 0;u8 least = 0;for (...) {...
if (least == 0 || (least != 1 && pVals[0] < least)) {foremost = pos;least = pVals[0];}...
}...
if (foremost != 0)printf(\"The foremost cell with %d candidate(s) at [%d,%d]\\n\", (int)least, (int)(foremost / 9 + 1), (int)(foremost % 9 + 1));...
}
run 接口修改
void CQuizDealer::run(ulong tilsteps){...
while (m_state == STA_VALID && (tilsteps == 0 || m_steps < tilsteps))...}
shrinkCandidates 接口修改
u8 CQuizDealer::shrinkCandidates(u8 cellPos, u8* pVals){...
bool shrunken = false;if (vals[0] != m_seqCell[cellPos].candidates[0]) {shrunken = true;printCandidatesChange(cellPos, m_seqCell[cellPos].candidates, vals);...}return (shrunken ? RET_SHRUNKEN : RET_PENDING);}
新增 printCandidatesChange 函数
void printCandidatesChange(u8 pos, u8* pOld, u8* pNew){u8 sum = pOld[0];printf(\"[%d,%d]:\", (int)(pos / 9 + 1), (int)(pos % 9 + 1));for (u8 idx = 0; idx < sum; ++idx)printf(\" %d\", (int)pOld[idx + 1]);printf(\" shrunken to \");sum = pNew[0];for (u8 idx = 0; idx < sum; ++idx)printf(\" %d\", (int)pNew[idx + 1]);}
shrinkRowCandidatesP1 接口修改
u8 CQuizDealer::shrinkRowCandidatesP1(u8* pBlk, u8* pRow, u8 zeroSum, u8 row, u8 colBase){...
for (u8 col = colBase; col < colBase + 3; ++col) {...ret = shrinkCandidates(rowBase + col, pBlk);if (ret == RET_WRONG) {...}if (ret != RET_PENDING) {printf(\" worked by row-ply1.\\n\");if (ret == RET_OK)shrunken = true;else if (ret == RET_SHRUNKEN)ret = RET_PENDING;}}...}
shrinkRowCandidatesP2、shrinkColCandidatesP1 以及 shrinkColCandidatesP2 接口做类似修改。
showOrderList 和 dealOrder 函数修改
// 1.0 2021/9/20// 2.0 2021/10/2#define STR_VER \"Sudoku Solver 2.1 2021/10/4 by readalps\\n\\n\"void showOrderList(){...printf(\"runtil <steps>: run till certain steps run\\n\");printf(\"bye: quit\\n\");}void dealOrder(std::string& strOrder){...
else if (matchPrefixEx(strOrder, \"runtil \", strEx)) {ulong tilsteps = strtoul(strEx.c_str(), 0, 10);CQuizDealer::instance()->run(tilsteps);}elseshowOrderList();}
实例分析
以下以SudokuSolver 1.0:用C++实现的数独解题程序 【二】里试验过的“最难”数独题为例,做一些分析。
H:\\Read\\num\\Release>sudoku.exeOrder please:load-quiz h:\\s.txtQuiz loaded.Order please:show800 000 000003 600 000070 090 200050 007 000000 045 700000 100 030001 000 068008 500 010090 000 400Order please:run3) Guess [8,7] level 1 at 1 out of 25) Guess [7,7] level 2 at 1 out of 26) row 6 shrunken by group8) blk 9 shrunken by group[9,1]: 2 3 5 6 7 shrunken to 3 5 6 worked by row-ply2.[9,3]: 2 5 6 7 shrunken to 5 6 worked by row-ply2.[9,4]: 2 3 7 8 shrunken to 3 8 worked by row-ply2.[9,5]: 1 2 3 6 7 8 shrunken to 1 3 6 8 worked by row-ply2.[9,6]: 1 2 3 6 8 shrunken to 1 3 6 8 worked by row-ply2.[6,3]: 2 4 6 7 9 shrunken to 7 worked by col-ply2.10) col 3 shrunken ply-2 by vblk 113) Guess [9,3] level 3 at 1 out of 2...769) Guess [1,5] level 7 at 1 out of 2770) shrinking 8 from [6,6] went wrong771) Forward guess [1,5] level 7 at 2 out of 2773) col 8 shrunken by group776) Guess [1,6] level 8 at 1 out of 2777) row 3 shrunken by group779) row 3 shrunken by group781) row 9 shrunken by group783) col 6 shrunken by group786) col 4 shrunken by group788) col 6 shrunken by group791) Guess [1,8] level 9 at 1 out of 2794) Guess [2,5] level 10 at 1 out of 2797) shrinking 4 from [6,3] went wrong798) Forward guess [2,5] level 10 at 2 out of 2812 753 649943 682 175675 491 283154 237 896369 845 721287 169 534521 974 368438 526 917796 318 452Done [steps:803, solution sum:1].Run time: 430 milliseconds; steps: 803, solution sum: 1.Order please:
第一个 run 命令求得一个解,耗时约 430 毫秒,用了 803 步。
Order please:run804) Upward guess [1,8] level 9 at 2 out of 2807) row 6 shrunken by group809) row 6 shrunken by group811) shrinking 2 from [4,4] went wrong812) Upward guess [1,6] level 8 at 2 out of 2...1778) Upward guess [3,3] level 5 at 2 out of 21779) row 1 shrunken by group[5,1]: 1 2 3 6 9 shrunken to 1 6 worked by row-ply1.[5,2]: 1 2 3 6 8 shrunken to 1 6 worked by row-ply1.[5,4]: 2 3 8 9 shrunken to 3 worked by row-ply2.1781) row 5 shrunken ply-2 by blk 31784) row 4 shrunken by group1786) col 2 shrunken by group1786) shrinking 9 from blk[5,1] went wrong1787) No more solution (solution sum is 1).800 000 306003 600 800076 893 250350 067 180000 345 700080 129 635001 000 568008 500 910090 000 400Invalid quiz [steps:1787] - no more solution (solution sum is 1)Run time: 610 milliseconds; steps: 1787, solution sum: 1.Order please:
第二个 run 命令耗时约 610 毫秒,两次 run 命令共用 1787 步。从完整的输出信息看,求解过程到达的最深猜测级别为 12 级,1.0 版是 21 级。
第二类候选值集合收缩算法实例
如SudokuSolver 2.0:用C++实现的数独解题程序 【一】里所示,2.0 版对心形数独那题的求解过程没有一次猜测(即全程处在猜测级别 0 的状态),而且只用到第一类候选值集合收缩算法,因为从输出信息只有shrunken by group 类信息,如:
row 4 shrunken by grouprow 4 shrunken by grouprow 7 shrunken by grouprow 7 shrunken by group...row 9 shrunken by groupcol 2 shrunken by group
而在上面的“最难”数独题解输出信息,却出现了如下的信息:
[9,1]: 2 3 5 6 7 shrunken to 3 5 6 worked by row-ply2.[9,3]: 2 5 6 7 shrunken to 5 6 worked by row-ply2.[9,4]: 2 3 7 8 shrunken to 3 8 worked by row-ply2.[9,5]: 1 2 3 6 7 8 shrunken to 1 3 6 8 worked by row-ply2.[9,6]: 1 2 3 6 8 shrunken to 1 3 6 8 worked by row-ply2.[6,3]: 2 4 6 7 9 shrunken to 7 worked by col-ply2.10) col 3 shrunken ply-2 by vblk 1
末行打头的 10) 指示这是当时进到第 10 步的处理过程中输出的信息。结合代码,可知这些信息是第二类候选值集合收缩算法输出的。2.0(2.1)版里实现了 4 种第二类收缩算法,分别标识为 row-ply1、row-ply2、col-ply1、col-ply2。
标蓝的信息是说第 9 行有 5 个 0-cell 的候选值集合得到了收缩,比如 [9,1] 的候选值集合从 {2, 3, 5, 6, 7} 收缩到 {3, 5, 6},采用的收缩算法是 row-ply2。
标绿的信息,第一行说明 [6,3] 这个 0-cell 的候选值集合从 {2, 4, 6, 7, 9} 收缩为 {7},采用的收缩算法是 col-ply2;第二行则进一步说明第 3 列收缩到了可以填值的地步(因为 [6,3] 只有一个候选值)。
第 10 步里的收缩过程分析
以下从头开始求解过程,并用 runtil 9 进到第 10 步开始时的上下文深入分析一下:
H:\\Read\\num\\Release>sudoku.exeOrder please:load-quiz h:\\s.txtQuiz loaded.Order please:runtil 93) Guess [8,7] level 1 at 1 out of 25) Guess [7,7] level 2 at 1 out of 26) row 6 shrunken by group8) blk 9 shrunken by group800 000 000003 600 000070 090 200050 007 000000 045 700000 100 035001 000 568008 500 319090 000 400Steps:9Candidates:[1,2]: 1 2 4 6 [1,3]: 2 4 5 6 9 [1,4]: 2 3 4 7[1,5]: 1 2 3 5 7 [1,6]: 1 2 3 4 [1,7]: 1 6 9[1,8]: 4 5 7 9 [1,9]: 1 3 4 6 7 [2,1]: 1 2 4 5 9[2,2]: 1 2 4 [2,5]: 1 2 5 7 8 [2,6]: 1 2 4 8[2,7]: 1 8 9 [2,8]: 4 5 7 8 9 [2,9]: 1 4 7[3,1]: 1 4 5 6 [3,3]: 4 5 6 [3,4]: 3 4 8[3,6]: 1 3 4 8 [3,8]: 4 5 8 [3,9]: 1 3 4 6[4,1]: 1 2 3 4 6 9 [4,3]: 2 4 6 9 [4,4]: 2 3 8 9[4,5]: 2 3 6 8 [4,7]: 1 6 8 9 [4,8]: 2 4 8 9[4,9]: 1 2 4 6 [5,1]: 1 2 3 6 9 [5,2]: 1 2 3 6 8[5,3]: 2 6 9 [5,4]: 2 3 8 9 [5,8]: 2 8 9[5,9]: 1 2 6 [6,1]: 2 4 6 7 9 [6,2]: 2 4 6 8[6,3]: 2 4 6 7 9 [6,5]: 2 6 8 [6,6]: 2 6 8 9[6,7]: 6 8 9 [7,1]: 2 3 4 7 [7,2]: 2 3 4[7,4]: 2 3 4 7 9 [7,5]: 2 3 7 [7,6]: 2 3 4 9[8,1]: 2 4 6 7 [8,2]: 2 4 6 [8,5]: 2 6 7[8,6]: 2 4 6 [9,1]: 2 3 5 6 7 [9,3]: 2 5 6 7[9,4]: 2 3 7 8 [9,5]: 1 2 3 6 7 8 [9,6]: 1 2 3 6 8[9,8]: 2 7 [9,9]: 2 7The foremost cell with 2 candidate(s) at [9,8]At guess level 2 [7,7] 1Run time: 40 milliseconds; steps: 9, solution sum: 0.Order please:
从走完 9 步的信息看,所有 0-cell 的候选值个数均大于 1,下一步不能直接做填空操作,于是会调用filterCandidates 依次尝试第一类和第二类收缩算法。第一类收缩算法有 3 种应用,即 row-grp、col-grp、blk-grp。从前面的输出信息看,第 10 步走到了 row-ply2(收缩了第 9 行)和 col-ply2(收缩了第 3 列)。先具体看一下 row-grp、col-grp 为何没能收缩第 9 行和第 3 列。
第 9 步走完后,第 9 行还有 7 个空位,即:
090 000 400
每个空位的候选值情况为:
[9,1]: 2 3 5 6 7 [9,3]: 2 5 6 7[9,4]: 2 3 7 8 [9,5]: 1 2 3 6 7 8 [9,6]: 1 2 3 6 8[9,8]: 2 7 [9,9]: 2 7
按filterOneGroup 接口里实现的算法,这里的候选值,即 1、2、3、5、6、7、8 全都在两个或更多个空位出现,因而不能对第 9 行实施收缩。但实际上,这个 grp 算法是有改进空间的。当前实现的 grp 算法只检查有没有完全收缩(即收缩到只有一个候选值)的空位,而没有考察不完全收缩的情形。比如这里的例子,2 和 7 都出现在两个空位,且它们的空位集合都是 {[9,8], [9,9]},即交集里的空位数也是 2,这就可以推定 2 和 7 只能填到 [9,8] 和 [9,9] 两个空位上,于是第 9 行的其它空位上的候选值 2 和 7 都可以被剔除掉。这正好对应前文中的如下信息:
[9,1]: 2 3 5 6 7 shrunken to 3 5 6 worked by row-ply2.[9,3]: 2 5 6 7 shrunken to 5 6 worked by row-ply2.[9,4]: 2 3 7 8 shrunken to 3 8 worked by row-ply2.[9,5]: 1 2 3 6 7 8 shrunken to 1 3 6 8 worked by row-ply2.[9,6]: 1 2 3 6 8 shrunken to 1 3 6 8 worked by row-ply2.
就是说,第 9 行的不完全收缩是在 row-ply2 里实施的。
再看第 3 列,为节省空间,用 /030 000 180/ 表示。其 6 个空位的候选值情况为:
[1,3]: 2 4 5 6 9 [3,3]: 4 5 6 [4,3]: 2 4 6 9
[5,3]: 2 6 9 [6,3]: 2 4 6 7 9 [9,3]: 2 5 6 7
这里的候选值,即 2、4、5、6、7、9全都在两个或更多个空位出现,因而不能对第 3 列实施完全收缩。候选值 7 有两个空位,5 有三个,4 和 9 都有四个,2 有五个,6 有六个,也没有不完全收缩的可能性。
执行一次 step 命令,输出信息如下:
Order please:step[9,1]: 2 3 5 6 7 shrunken to 3 5 6 worked by row-ply2.[9,3]: 2 5 6 7 shrunken to 5 6 worked by row-ply2.[9,4]: 2 3 7 8 shrunken to 3 8 worked by row-ply2.[9,5]: 1 2 3 6 7 8 shrunken to 1 3 6 8 worked by row-ply2.[9,6]: 1 2 3 6 8 shrunken to 1 3 6 8 worked by row-ply2.[6,3]: 2 4 6 7 9 shrunken to 7 worked by col-ply2.10) col 3 shrunken ply-2 by vblk 1800 000 000003 600 000070 090 200050 007 000000 045 700007 100 035001 000 568008 500 319090 000 400Steps:11Candidates:[1,2]: 1 2 4 6 [1,3]: 2 4 5 6 9 [1,4]: 2 3 4 7[1,5]: 1 2 3 5 7 [1,6]: 1 2 3 4 [1,7]: 1 6 9[1,8]: 4 5 7 9 [1,9]: 1 3 4 6 7 [2,1]: 1 2 4 5 9[2,2]: 1 2 4 [2,5]: 1 2 5 7 8 [2,6]: 1 2 4 8[2,7]: 1 8 9 [2,8]: 4 5 7 8 9 [2,9]: 1 4 7[3,1]: 1 4 5 6 [3,3]: 4 5 6 [3,4]: 3 4 8[3,6]: 1 3 4 8 [3,8]: 4 5 8 [3,9]: 1 3 4 6[4,1]: 1 2 3 4 6 9 [4,3]: 2 4 6 9 [4,4]: 2 3 8 9[4,5]: 2 3 6 8 [4,7]: 1 6 8 9 [4,8]: 2 4 8 9[4,9]: 1 2 4 6 [5,1]: 1 2 3 6 9 [5,2]: 1 2 3 6 8[5,3]: 2 6 9 [5,4]: 2 3 8 9 [5,8]: 2 8 9[5,9]: 1 2 6 [6,1]: 2 4 6 9 [6,2]: 2 4 6 8[6,5]: 2 6 8 [6,6]: 2 6 8 9 [6,7]: 6 8 9[7,1]: 2 3 4 7 [7,2]: 2 3 4 [7,4]: 2 3 4 7 9[7,5]: 2 3 7 [7,6]: 2 3 4 9 [8,1]: 2 4 6 7[8,2]: 2 4 6 [8,5]: 2 6 7 [8,6]: 2 4 6[9,1]: 3 5 6 [9,3]: 5 6 [9,4]: 3 8[9,5]: 1 3 6 8 [9,6]: 1 3 6 8 [9,8]: 2 7[9,9]: 2 7The foremost cell with 2 candidate(s) at [9,3]At guess level 2 [7,7] 1Order please:
可以看到,第 9 行如期实施了不完全收缩,第 3 列实施了一次完全收缩,即 [6,3] 位置填上了 7。以下分析一下这两次第二类收缩算法(row-ply2 和 col-ply2)具体是如何实施的:
800 000 000003 600 000070 090 200050 007 000000 045 700000 100 035001 000 568008 500 319090 000 400
走完 9 步后,对第 9 行考察 row-ply2。第 9 行横向跨越底部三个宫。先看左下宫,其中有 1 和 8 待填到第 9 行的第二节和第三节,对照当时第 9 行各空位候选值分布情况:
[9,1]: 2 3 5 6 7 [9,3]: 2 5 6 7[9,4]: 2 3 7 8 [9,5]: 1 2 3 6 7 8 [9,6]: 1 2 3 6 8[9,8]: 2 7 [9,9]: 2 7
可知,1 和 8 只能填到第二节的三个空位,且 [9,4] 的候选值集合里没有 1,进一步可知 1 只能填到 [9,5] 或 [9,6]。但凭借这些信息还不能对 [9,5] 或 [9,6] 实施收缩。
接着考察下中宫,其中有 5待填到第 9 行的第一节和第三节的空位,同样根据候选值分布情况可知,5 只能填到 [9,1] 或 [9,3],凭借这个信息还是不能对[9,1] 或 [9,3] 实施收缩。
考察右下宫,其中有 5、6、8、3、1、9 待填到第 9 行的第一节和第二节,9 已经在第一节里,剩余 5 个候选值 {5, 6, 8, 3, 1} 正好填到第一节和第二节的 5 个空位里。
[9,1] 的候选值集合为 {2, 3, 5, 6, 7},{2, 3, 5, 6, 7} ∩{5, 6, 8, 3, 1} = {3, 5, 6},这便是收缩后的[9,1] 的候选值集合。同样:
[9,3]:{2, 5, 6, 7} ∩{5, 6, 8, 3, 1} = {5, 6}
[9,4]:{2, 3, 7, 8} ∩{5, 6, 8, 3, 1} = {3, 8}
[9,5]:{1, 2, 3, 6, 7, 8} ∩{5, 6, 8, 3, 1} = {1, 3, 6, 8}
[9,6]:{1, 2, 3, 6, 8} ∩{5, 6, 8, 3, 1} = {3, 5, 6}
以上就是 row-ply2 对第 9 行的不完全收缩过程分析。接着来看 col-ply2 对第 3 列的完全收缩是如何实施的:
800 000 000003 600 000070 090 200050 007 000000 045 700
000 100 035
001 000 568
008 500 319
090 000 400
第 3 列竖着跨越左侧三个宫,先考察左上宫,其中的 8 和 7 待填到第 3 列的第二节和第三节。第三节里已经有 8,于是 7 可填的空位有 [4,3]、[5,3]、[6,3]、[9,3]。这几个空位的候选值集合分别为:
[4,3]: 2 4 6 9 [5,3]: 2 6 9 [6,3]: 2 4 6 7 9 [9,3]: 5 6
于是 7 只能填到 [6,3] 位置上。由上面的分析可知, [9,3] 的候选值集合是在第 10 步过程中通过 row-ply2 才从 {2, 5, 6, 7} 收缩为 {5, 6} 的,而此处正因为 [9,3] 的这次不完全收缩才使得第 3 列通过 col-ply2 发生了一次完全收缩,[6,3] 的候选值集合从 {2, 4, 6, 7, 9} 收缩为 {7},即对应如下的输出信息:
[6,3]: 2 4 6 7 9 shrunken to 7 worked by col-ply2.10) col 3 shrunken ply-2 by vblk 1
第二行里的 vblk 1 是指 vertical block 1,第 3 列竖直跨越三个宫,vblk 1 指竖列的第 1 宫(即左上宫),考察这一宫已经推定会发生完全收缩,便不再继续考察另外两个宫,而是进到下一步(即第 11 步),给单候选值的空位填值并对关联空位的候选值集合做相应调整处理。
程序改进思路
上面的分析过程中,已经有一个程序改进思路,即增强 grp 算法可以处理不完全收缩的情形。而从刚才的两次关联收缩的示例分析可以提炼出另一个改进程序的思路,filterCandidates 接口里有五轮收缩筛查,按顺序分别是 row-grp、col-grp、blk-grp、row-ply、col-ply。刚才的收缩接力得以在一次filterCandidates 调用中实施,也是因为第 9 行的不完全收缩发生在第四轮的 row-ply 筛查阶段,而第 3 列的完全收缩发生在第五轮的 col-ply 筛查阶段。这样的两次关联收缩,倘若第一次不完全收缩发生在第五轮的 col-ply 筛查阶段,就会导致第二次的完全收缩接续不上,进而多加一次猜测行为。这是一个可改进之处。
上面示例中的两次关联收缩中,第二次收缩,即第 2 列的 [6,3] 收缩为 {7},是由 col-ply 算法检测到的,但显然通过更简单的 col-grp 算法一样可以检测到。因此可以推测:grp 算法增强后有可能就不需要使用第二类收缩算法了,这一点后续再做检验。
接着分析一个综合的过程。
第 1778 步之后的过程分析
第二个 run 命令的输出信息的末尾部分有如下信息:
1779) row 1 shrunken by group[5,1]: 1 2 3 6 9 shrunken to 1 6 worked by row-ply1.[5,2]: 1 2 3 6 8 shrunken to 1 6 worked by row-ply1.[5,4]: 2 3 8 9 shrunken to 3 worked by row-ply2.1781) row 5 shrunken ply-2 by blk 31784) row 4 shrunken by group1786) col 2 shrunken by group1786) shrinking 9 from blk[5,1] went wrong1787) No more solution (solution sum is 1).
从头开始求解过程,并用 runtil 1778 进到第 1779 步开始时的上下文:
H:\\Read\\num\\Release>sudoku.exeOrder please:load-quiz h:\\s.txtQuiz loaded.Order please:runtil 17783) Guess [8,7] level 1 at 1 out of 25) Guess [7,7] level 2 at 1 out of 2
...
Done [steps:803, solution sum:1]. Run time: 460 milliseconds; steps: 803, solution sum: 1.
Order please:
runtil 1778
...
800 000 300
003 600 800
076 090 250
050 067 100
000 045 700
000 100 635
001 000 568
008 500 910
090 000 400
Steps:1778
Candidates:
[1,2]: 1 2 4 [1,3]: 2 4 5 9 [1,4]: 2 4 7
[1,5]: 1 2 5 7 [1,6]: 1 2 4 [1,8]: 4 7 9
[1,9]: 1 4 6 7 9 [2,1]: 1 2 4 5 9 [2,2]: 1 2 4
[2,5]: 1 2 5 7 [2,6]: 1 2 4 [2,8]: 4 7 9
[2,9]: 1 4 7 9 [3,1]: 1 4 [3,4]: 3 8
[3,6]: 3 8 [3,9]: 1 4 [4,1]: 2 3 4 9
[4,3]: 2 4 9 [4,4]: 2 3 8 9 [4,8]: 2 4 8 9
[4,9]: 2 4 9 [5,1]: 1 2 3 6 9 [5,2]: 1 2 3 6 8
[5,3]: 2 9 [5,4]: 2 3 8 9 [5,8]: 2 8 9
[5,9]: 2 9 [6,1]: 2 4 7 9 [6,2]: 2 4 8
[6,3]: 2 4 7 9 [6,5]: 2 8 [6,6]: 2 8 9
[7,1]: 2 3 4 7 [7,2]: 2 3 4 [7,4]: 2 3 4 7 9
[7,5]: 2 3 7 [7,6]: 2 3 4 9 [8,1]: 2 3 4 6 7
[8,2]: 2 3 4 6 [8,5]: 2 3 7 [8,6]: 2 3 4 6
[8,9]: 2 3 7 [9,1]: 2 3 5 6 7 [9,3]: 2 5 7
[9,4]: 2 3 7 8 [9,5]: 1 2 3 7 8 [9,6]: 1 2 3 6 8
[9,8]: 2 7 [9,9]: 2 3 7
The foremost cell with 2 candidate(s) at [3,1]
At guess level 5 [3,3] 2
Run time: 600 milliseconds; steps: 1778, solution sum: 1.
Order please:
可以看到第一次 runtil 1778 命令因为求解成功被中断了,第二次 runtil 1778 命令才继续走到第 1779 步开始时的上下文。由The foremost cell with 2 candidate(s) at [3,1] 可知,当时不能直接做填空操作。先分析如下信息:
1779) row 1 shrunken by group
对应的收缩过程。当时第 1 行为:800 000 300,其中 7 个空位的候选值分布情况为:
[1,2]: 1 2 4 [1,3]: 2 4 5 9 [1,4]: 2 4 7 [1,5]: 1 2 5 7 [1,6]: 1 2 4 [1,8]: 4 7 9 [1,9]: 1 4 6 7 9
由 grp 算法可推定 [1,9] = 6。与如下的 step 命令输出结果相符:
Order please:step1779) row 1 shrunken by group800 000 306003 600 800076 090 250050 067 100000 045 700000 100 635001 000 568008 500 910090 000 400Steps:1780Candidates:[1,2]: 1 2 4 [1,3]: 2 4 5 9 [1,4]: 2 4 7[1,5]: 1 2 5 7 [1,6]: 1 2 4 [1,8]: 4 7 9[2,1]: 1 2 4 5 9 [2,2]: 1 2 4 [2,5]: 1 2 5 7[2,6]: 1 2 4 [2,8]: 4 7 9 [2,9]: 1 4 7 9[3,1]: 1 4 [3,4]: 3 8 [3,6]: 3 8[3,9]: 1 4 [4,1]: 2 3 4 9 [4,3]: 2 4 9[4,4]: 2 3 8 9 [4,8]: 2 4 8 9 [4,9]: 2 4 9[5,1]: 1 2 3 6 9 [5,2]: 1 2 3 6 8 [5,3]: 2 9[5,4]: 2 3 8 9 [5,8]: 2 8 9 [5,9]: 2 9[6,1]: 2 4 7 9 [6,2]: 2 4 8 [6,3]: 2 4 7 9[6,5]: 2 8 [6,6]: 2 8 9 [7,1]: 2 3 4 7[7,2]: 2 3 4 [7,4]: 2 3 4 7 9 [7,5]: 2 3 7[7,6]: 2 3 4 9 [8,1]: 2 3 4 6 7 [8,2]: 2 3 4 6[8,5]: 2 3 7 [8,6]: 2 3 4 6 [8,9]: 2 3 7[9,1]: 2 3 5 6 7 [9,3]: 2 5 7 [9,4]: 2 3 7 8[9,5]: 1 2 3 7 8 [9,6]: 1 2 3 6 8 [9,8]: 2 7[9,9]: 2 3 7The foremost cell with 2 candidate(s) at [3,1]At guess level 5 [3,3] 2Order please:
第 1779 步对第 1 行实施 grp 算法把 [1,9] 的候选值集合收缩为单值集合 {6},第 1780 步把 6 填入 [1,9] 并从关联的空位(第 1 行,第 9 列,第 3 宫)的候选值集合里去掉 6。这里似乎也有一个可改进之处:对一个空位填值,而这个值是唯一推定出来的,就无需对关联的空位的候选值集合做调整处理。
接着分析如下信息:
[5,1]: 1 2 3 6 9 shrunken to 1 6 worked by row-ply1.[5,2]: 1 2 3 6 8 shrunken to 1 6 worked by row-ply1.[5,4]: 2 3 8 9 shrunken to 3 worked by row-ply2.1781) row 5 shrunken ply-2 by blk 3
此时各行填值情况为:
800 000 306003 600 800076 090 250050 067 100000 045 700000 100 635001 000 568008 500 910090 000 400
第 5 行横跨中间三个宫,除去第 5 行,这三个宫的已填数集合分别为 {5}、{6, 7, 1}、{1, 6, 3, 5}。后面两个集合的交集为 {1, 6},即 1 和 6 要填入到第 5 行的第一节里,这一节里的三个空位的候选值分布情况为:
[5,1]: 1 2 3 6 9 [5,2]: 1 2 3 6 8 [5,3]: 2 9
由于 {2, 9} ∩ {1, 6} = {},说明 [5,3] 这个空位上 1 和 6 都不能填,因此 1 和 6 只能填入 [5, 1] 和 []5,2] 两个空位,于是有
[5,1]: {1, 2, 3, 6, 9} ∩ {1, 6} = {1, 6}
[5,2]: {1, 2, 3, 6, 8} ∩ {1, 6} = {1, 6}
上面是 row-ply1 by vlk 1 的考察。继续看row-ply1 by vlk 2 的情形,这时 {5} ∩{1, 6, 3, 5} = {5},且第 5 行的第二节里已经有 5,没有考察价值;row-ply1 by vlk 3 也没有考察价值,因为{5} ∩ {6, 7, 1} = {}。
接着开始 row-ply2 by blk 1 的考察,{5} 里只有 5,待填入第 5 行的第二节和第三节,而第二节里已经有 5,没有考察价值。
row-ply2 by blk 2,{6, 7, 1} 里的这三个数待填入第 5 行的第一节和第三节的 5 个空位里,且 7 已经在第三节里,剔除 7,即 1 和 6 待填入第一节和第三节的 5 个空位里,而这 5 个空位的候选值分布情况为:
[5,1]: 1 6 [5,2]: 1 6 [5,3]: 2 9 [5,8]: 2 8 9 [5,9]: 2 9
后三个的候选值都没有 1 和 6,剔除,这时就是 1 和 6 待填入两个空位:[5,1] 和 [5,2],而这两个空位的候选值集合都已经是 {1, 6},不能做进一步的收缩。
继续看row-ply2 by blk 3,{1, 6, 3, 5} 里的四个数待填入第5 行的第一节和第二节的四个空位里。5 已经在第二节里,即 1、6、3 待填入 4 个空位。这四个空位的候选值分布情况为:
[5,1]: 1 6 [5,2]: 1 6 [5,3]: 2 9 [5,4]: 2 3 8 9
[5,3] 的候选值集合里没有 1、6、3,剔除。这时就是 1、6、3 待填入三个空位:[5,1]、[5,2] 和 [5,4]。取交集易知 [5,4] = 3。与如下的 step 命令输出结果相符:
Order please:step[5,1]: 1 2 3 6 9 shrunken to 1 6 worked by row-ply1.[5,2]: 1 2 3 6 8 shrunken to 1 6 worked by row-ply1.[5,4]: 2 3 8 9 shrunken to 3 worked by row-ply2.1781) row 5 shrunken ply-2 by blk 3800 000 306003 600 800076 090 250050 067 100000 345 700000 100 635001 000 568008 500 910090 000 400Steps:1782Candidates:[1,2]: 1 2 4 [1,3]: 2 4 5 9 [1,4]: 2 4 7[1,5]: 1 2 5 7 [1,6]: 1 2 4 [1,8]: 4 7 9[2,1]: 1 2 4 5 9 [2,2]: 1 2 4 [2,5]: 1 2 5 7[2,6]: 1 2 4 [2,8]: 4 7 9 [2,9]: 1 4 7 9[3,1]: 1 4 [3,4]: 8 [3,6]: 3 8[3,9]: 1 4 [4,1]: 2 3 4 9 [4,3]: 2 4 9[4,4]: 2 8 9 [4,8]: 2 4 8 9 [4,9]: 2 4 9[5,1]: 1 6 [5,2]: 1 6 [5,3]: 2 9[5,8]: 2 8 9 [5,9]: 2 9 [6,1]: 2 4 7 9[6,2]: 2 4 8 [6,3]: 2 4 7 9 [6,5]: 2 8[6,6]: 2 8 9 [7,1]: 2 3 4 7 [7,2]: 2 3 4[7,4]: 2 4 7 9 [7,5]: 2 3 7 [7,6]: 2 3 4 9[8,1]: 2 3 4 6 7 [8,2]: 2 3 4 6 [8,5]: 2 3 7[8,6]: 2 3 4 6 [8,9]: 2 3 7 [9,1]: 2 3 5 6 7[9,3]: 2 5 7 [9,4]: 2 7 8 [9,5]: 1 2 3 7 8[9,6]: 1 2 3 6 8 [9,8]: 2 7 [9,9]: 2 3 7The foremost cell with 1 candidate(s) at [3,4]At guess level 5 [3,3] 2Order please:
走完 1782 步时,[3,4] 的候选值集合成为单值集合 {8},下一步可以直接做填空操作,同时也说明上面那个猜测结论是不对的:对一个空位填值,而这个值是唯一推定出来的,就无需对关联的空位的候选值集合做调整处理。
下一步到走完 1783 步,即:
Order please:step800 000 306003 600 800076 893 250050 067 100000 345 700000 100 635001 000 568008 500 910090 000 400Steps:1783Candidates:[1,2]: 1 2 4 [1,3]: 2 4 5 9 [1,4]: 2 4 7[1,5]: 1 2 5 7 [1,6]: 1 2 4 [1,8]: 4 7 9[2,1]: 1 2 4 5 9 [2,2]: 1 2 4 [2,5]: 1 2 5 7[2,6]: 1 2 4 [2,8]: 4 7 9 [2,9]: 1 4 7 9[3,1]: 1 4 [3,9]: 1 4 [4,1]: 2 3 4 9[4,3]: 2 4 9 [4,4]: 2 9 [4,8]: 2 4 8 9[4,9]: 2 4 9 [5,1]: 1 6 [5,2]: 1 6[5,3]: 2 9 [5,8]: 2 8 9 [5,9]: 2 9[6,1]: 2 4 7 9 [6,2]: 2 4 8 [6,3]: 2 4 7 9[6,5]: 2 8 [6,6]: 2 8 9 [7,1]: 2 3 4 7[7,2]: 2 3 4 [7,4]: 2 4 7 9 [7,5]: 2 3 7[7,6]: 2 4 9 [8,1]: 2 3 4 6 7 [8,2]: 2 3 4 6[8,5]: 2 3 7 [8,6]: 2 4 6 [8,9]: 2 3 7[9,1]: 2 3 5 6 7 [9,3]: 2 5 7 [9,4]: 2 7[9,5]: 1 2 3 7 8 [9,6]: 1 2 6 8 [9,8]: 2 7[9,9]: 2 3 7The foremost cell with 2 candidate(s) at [3,1]At guess level 5 [3,3] 2Order please:
下一个 step 命令的输出:
Order please:step1784) row 4 shrunken by group800 000 306003 600 800076 893 250350 067 180000 345 700000 100 635001 000 568008 500 910090 000 400Steps:1785Candidates:[1,2]: 1 2 4 [1,3]: 2 4 5 9 [1,4]: 2 4 7[1,5]: 1 2 5 7 [1,6]: 1 2 4 [1,8]: 4 7 9[2,1]: 1 2 4 5 9 [2,2]: 1 2 4 [2,5]: 1 2 5 7[2,6]: 1 2 4 [2,8]: 4 7 9 [2,9]: 1 4 7 9[3,1]: 1 4 [3,9]: 1 4 [4,3]: 2 4 9[4,4]: 2 9 [4,9]: 2 4 9 [5,1]: 1 6[5,2]: 1 6 [5,3]: 2 9 [5,8]: 2 9[5,9]: 2 9 [6,1]: 2 4 7 9 [6,2]: 2 4 8[6,3]: 2 4 7 9 [6,5]: 2 8 [6,6]: 2 8 9[7,1]: 2 4 7 [7,2]: 2 3 4 [7,4]: 2 4 7 9[7,5]: 2 3 7 [7,6]: 2 4 9 [8,1]: 2 4 6 7[8,2]: 2 3 4 6 [8,5]: 2 3 7 [8,6]: 2 4 6[8,9]: 2 3 7 [9,1]: 2 5 6 7 [9,3]: 2 5 7[9,4]: 2 7 [9,5]: 1 2 3 7 8 [9,6]: 1 2 6 8[9,8]: 2 7 [9,9]: 2 3 7The foremost cell with 2 candidate(s) at [3,1]At guess level 5 [3,3] 2Order please:
第 4 行由050 067 100 变到了350 067 180
[4,1]: 2 3 4 9[4,3]: 2 4 9 [4,4]: 2 9 [4,8]: 2 4 8 9[4,9]: 2 4 9
再运行一次 step 命令,输出信息为:
Order please:step1786) col 2 shrunken by group1786) shrinking 9 from blk[5,1] went wrong1787) No more solution (solution sum is 1).800 000 306003 600 800076 893 250350 067 180000 345 700080 129 635001 000 568008 500 910090 000 400Invalid quiz [steps:1787] - no more solution (solution sum is 1)Order please:
从输出信息看,先是:
1786) col 2 shrunken by group
第 2 列 从 /007 500 009/ 变到了 /007 508 009/。
第 2 列的空位候选值分布情况:
[1,2]: 1 2 4 [2,2]: 1 2 4 [5,2]: 1 6 [6,2]: 2 4 8 [7,2]: 2 3 4 [8,2]: 2 3 4 6
[6,2] = 8,符合预期。接着的输出信息是:
1786) shrinking 9 from blk[5,1] went wrong1787) No more solution (solution sum is 1).
从 1785 步到 1786 步,第 6 行也从000 100 635 变到了080 129 635。
1785 步时,第 6 行各空位的候选值分布情况为:
[6,1]: 2 4 7 9 [6,2]: 2 4 8[6,3]: 2 4 7 9 [6,5]: 2 8 [6,6]: 2 8 9
因为在 1786 步有 [6,2] = 8,所以第 6 行里剩余空位的候选值应该去除 8,即:
[6,1]: 2 4 7 9[6,3]: 2 4 7 9 [6,5]: 2 [6,6]: 2 9
于是有 [6,5] = 2,[6,6] = 9。第 6 行里剩余空位的候选值分布进一步收缩为:
[6,1]: 4 7 [6,3]: 4 7
接着看第 5 宫的情况:
350 067 180000 345 700080 129 635
该宫里只剩第一个 cell 为空位,即blk[5,1],该空位用行标和列标表示为 [4,4],1785 步时其候选值集合为:
[4,4]: 2 9
1786 步的过程中,2 和 9 依次填入 [6,5] 和 [6,6],这两个 cell 和 [4,4] 同属第 5 宫,于是 2 和 9 依次会从[4,4] 的候选值集合里剔除掉,导致 [4,4] 的候选值集合为空,从而会输出:
1786) shrinking 9 from blk[5,1] went wrong
且当时无法做平级猜测调整或降级猜测调整,于是会输出:
1787) No more solution (solution sum is 1).