 爱站程序员基地
爱站程序员基地union执行
为了便于分析,使用一下sql来进行举例
CREATE TABLE t1 ( id INT PRIMARY KEY, a INT, b INT, INDEX ( a ) );delimiter ;;CREATE PROCEDURE idata ( ) BEGINDECLAREi INT;SET i = 1;WHILE( i <= 1000 ) DOINSERT INTO t1VALUES( i, i, i );SET i = i + 1;END WHILE;END;;delimiter ;CALL idata ( );
然后我们执行以下sql
(select 1000 as f) union (select id from t1 order by id desc limit 2);
这段sql的语义是,取两个子查询的的并集,并且去重
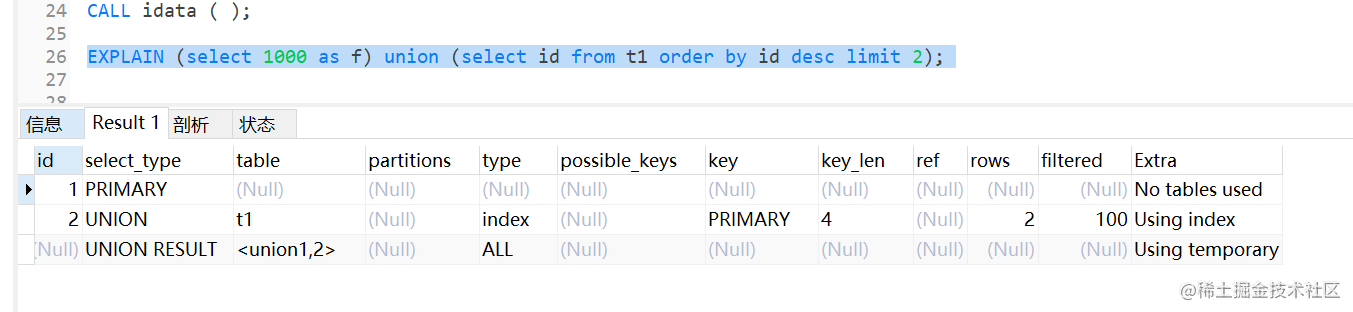
可以看到,第二行的key是primary,说明第二个子查询使用索引id。第三行的Extra字段,表示在子查询union的时候,使用了临时表(Using temporary)。
这个语句的执行流程是这样的:
1)创建一个内存临时表,这个临时表只有一个整形字段f,并且f是主键字段
2)执行第一个子查询,将1000存在临时表
3)执行第二个子查询,拿到第一行id=1000,并试图插入到临时表,但是由于1000这个值已经存在临时表了,违法了唯一性约束,所以插入失败,接着取到第二行数据999,插入临时表成功
4)从临时表中按行取出数据,返回结果,并删除临时表,结果中包含两条数据就是1000和999
可以看到,临时表起到了暂存数据的作用,而且存在唯一性约束,实现了union去重的语义
group by
另外一个常见的使用临时表的例子就是group by,我们看一下以下sql
select id%10 as m, count(*) as c from t1 group by m;
这个语句就是根据t1表的数据,根据id%10进行分组,并按照m的结果排序后输出
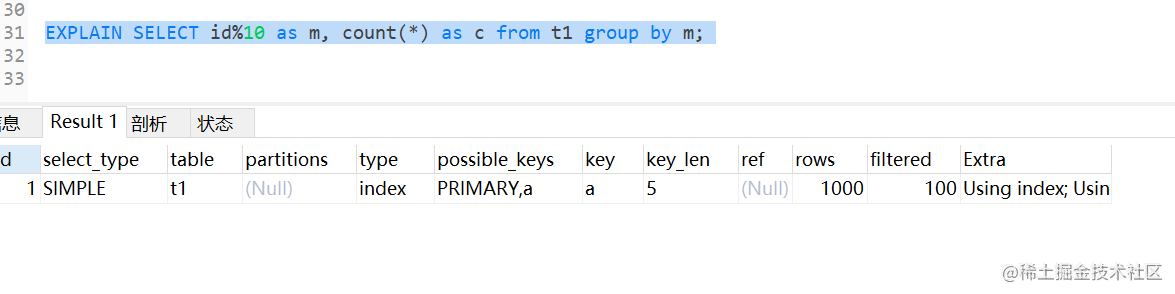
在Extra字段中,我们看到了三个信息:
1)Using index,表示这个语句使用了覆盖索引,选择了索引 a;
2)Using temporary,表示使用了临时表;
3)Using filesort,表示需要排序;
这个语句的执行流程是这样的:
1)创建内存临时表,表里有字段m和c,主键是m;
2)扫描表t1的索引a,依次取出叶子节点上面的id值,计算id%10的结果,记为x;
- 如果临时表没有主键x,就插入一个记录(x,1);
- 如果表中有主键x的行,就将x这一行的c值加1;
3)遍历完成之后,再根据字段m做排序,得到结果
内存临时表的大小是有限制的,参数tmp_table_size就是控制这个内存大小的,默认是16M,如果内存临时表大小达到了上线,这时候就会把内存临时表转成磁盘临时表,磁盘临时表的默认引擎是InnoDB,如果表的数据量很大,很可能查询就会占用大量的磁盘空间
到此这篇关于浅谈Mysql在什么情况下会使用内部临时表的文章就介绍到这了,更多相关Mysql 内部临时表内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
- MySQL常用分库分表方案汇总
- MySQL分区表实现按月份归类
- MySQL对数据表已有表进行分区表的实现
- mysql分表之后如何平滑上线详解
- MySQL系列多表连接查询92及99语法示例详解教程
- MySQL内部临时表的具体使用
- 通过Python收集汇聚MySQL 表信息的实例详解
- MYSQL 表的总结


