 爱站程序员基地
爱站程序员基地[toc]
1、Python的变量
(1)Python变量不能独立存在
- 比如在
C++
等语言中,变量的声明和赋值是可以分开的。
int a;a=343;
- 而在Python中却不行,在声明Python变量的同时必须进行赋值操作,否则会报错。
Python Console: starting.Python 3.7.7>>> aTraceback (most recent call last):File "<input>", line 1, in <module>NameError: name \'a\' is not defined>>> a = 343>>> a343
如果你直接使用一个不存在的变量,就会发生错误:
NameError: name \'a\' is not defined
。
(2)变量是内存中数据的引用
a = 343
这样代码被执行时,首先要在内存中创建出
343
这个对象,然后让
a
指向它,这便是引用。
此后,我们在程序中使用变量
a
时,其实都是在使用
343
,Python可以通过
a
找到
343
这个值,这是对引用最通俗的解释。
如下图所示:

(3)注意点
赋值语句执行过程中,有一点极容易被忽略掉,那就是这个过程中,在内存中创建了新的数据的问题。
a = [1]b = [1]print(a == b)Trueprint(a is b)False
两行赋值语句,分别将列表
[1]
赋值给
a
和
b
,表达式
a==b
的结果是
Ture
,因为他们的内容的确相同,但表达式
a is b
的结果是
False
,因为这两行赋值语句执行过程中,一共创建了两个列表,他们只是内容相同而已,但内存地址绝对不相同,下图是这两个变量的内存描述示意图。

2、了解变量的引用
在Python中,变量的值是靠引用来传递来的。
我们可以用
id()
函数来判断两个变量是否引用的同一个值。
id()
函数返回对象的唯一标识符,标识符是一个整数,是对象的内存地址。如果两个变量的内存地址相同,说明两个变量引用的是同一个地址。
看下面综合示例:
# 1. int类型"""声明变量保存整型数据,把这个数据赋值到另一个变量;id()检测两个变量的id值(内存的十进制值)"""a = 1b = aprint(b) # 打印变量b的值为1# id(a):返回a变量在内存中的十进制地址# 变量a和变量b的内存地址一样,说明ab引用的是同一数据。print(id(a)) # 140708464157520print(id(b)) # 140708464157520# 将变量a重新赋值a = 2print(b) # 打印变量b的值为1# 因为修改了a的数据,内存要开辟另外一份内存取存储2,# id检测a和b的地址不同print(id(a)) # 140708464157552,此时得到是的数据2的内存地址print(id(b)) # 140708464157520# 2. 列表(可变数据类型)aa = [10, 20]bb = aa# 发现a和b的id值相同的,说明引用的是同一个内存地址print(id(aa)) # 2325297783432print(id(bb)) # 2325297783432# 变量aa添加数据aa.append(30)print(bb) # 变量bb的值为[10, 20, 30], 列表为可变类型# 打印结果print(id(aa)) # 2325297783432print(id(bb)) # 2325297783432# 继续操作bb = bb + [666]print(aa) # [10, 20, 30]print(bb) # [10, 20, 30, 666]print(id(aa)) # 30233096print(id(bb)) # 40054280# 这时我们会发现可变类型变量的引用也会发生改变,# 这是为什么呢?这里就不解释了,下面一点进行详细说明。
3、Python的参数传递(重点)
Python的参数传递也就是Python变量的引用。
在Python中,所有的变量都是指向某一个地址,变量本身不保存数据,而数据是保存在内存中的一个地址上。
通俗的来说,在
Python
中,变量的名字类似于把便签纸贴在数据上。
我看网上很多文章说:
- Python基本的参数传递机制有两种:值传递和引用传递。
- 不可变参数是值传递,可变参数是引用传递。
这样理解也是可以的,但我认为都是引用的传递,下面我用示例说明一下。
先来说明一个知识点,在Python中,不可变数据类型和可变数据类型是如何分配内存地址的。
如下所示:
inta = 10086intb = 10086lista = [10,20,30]listb = [10,20,30]print(\'inta的内存地址\',id(inta))print(\'intb的内存地址\',id(intb))print(\'lista的内存地址\',id(lista))print(\'listb的内存地址\',id(listb))"""运行结果如下:inta的内存地址 37930032intb的内存地址 37930032lista的内存地址 30233096listb的内存地址 30233608"""
我们可以看到:
- 对于不可变数据类型变量,相同的值是共用内存地址的。(这一点很重要)
- 对于可变数据类型变量,如上面的
lista
和
listb
,即使内容一样,Python也会给它们分配不同的内存地址。
(1)示例
下面来看一下示例:
提示:对不可变数据类型,
+
和
+=
都会创建新对象,对可变数据类型来说,
+=
不会创建新对象。
1)可变数据类型变量示例
我们通过示例来看看可变数据类型变量的引用是如何传递的。
def ChangeParam(paramList):paramList.append([1, 2, 3, 4])print("函数内paramList状态1,取值: ", paramList)print(\'函数内paramList状态1的内存地址:\', id(paramList))paramList += [888]print("函数内paramList状态2,取值: ", paramList)print(\'函数内paramList状态2的内存地址:\', id(paramList))paramList = paramList + [888]print("函数内paramList状态3,取值: ", paramList)print(\'函数内paramList状态3的内存地址:\', id(paramList))returnmylist = [10, 20, 30]print(\'mylist函数外的内存地址(前):\', id(mylist))ChangeParam(mylist)print("函数外取值: ", mylist)print(\'mylist函数外的内存地址(后):\', id(mylist))"""mylist函数外的内存地址(前): 32264712函数内paramList状态1,取值: [10, 20, 30, [1, 2, 3, 4]]函数内paramList状态1的内存地址: 32264712函数内paramList状态2,取值: [10, 20, 30, [1, 2, 3, 4], 888]函数内paramList状态2的内存地址: 32264712函数内paramList状态3,取值: [10, 20, 30, [1, 2, 3, 4], 888, 888]函数内paramList状态3的内存地址: 42905160函数外取值: [10, 20, 30, [1, 2, 3, 4], 888]mylist函数外的内存地址(后): 32264712"""
2)不可变数据类型变量示例
我们通过示例来看看不可变数据类型变量的引用是否是值传递。
示例如下:
def NoChangeParam(prarmInt):print(\'函数中变量prarmInt的初始状态,prarmInt变量的值\', prarmInt)print(\'函数中变量prarmInt的初始状态,prarmInt的内存地址\', id(prarmInt))prarmInt += prarmIntprint(\'函数中状态1,此时prarmInt的值:\', prarmInt)print(\'函数中状态1,prarmInt的内存地址:\', id(prarmInt))# 1.定义变量aa = 1000print(\'执行函数前,变量a的内存地址:\', id(a))# 2.调用函数NoChangeParam(a)# 3.打印执行函数后,a变量的值和指向内存地址print(\'执行函数后,a变量的值。a =\', a)print(\'执行函数后,a的内存地址:\', id(a))"""执行函数前,变量a的内存地址: 32817968函数中变量prarmInt的初始状态,prarmInt变量的值 1000函数中变量prarmInt的初始状态,prarmInt的内存地址 32817968函数中状态1,此时prarmInt的值: 2000函数中状态1,prarmInt的内存地址: 32818224执行函数后,a变量的值。a = 1000执行函数后,a的内存地址: 32817968"""
(2)结论
通过上面示例我们可以看到:
- 在函数执行前后,不可变数据类型变量和可变数据类型变量的所指向的地址都没有发生改变。只不过不可变数据类型变量的值没有改变,而可变数据类型变量的值发生了改变。
- 不可变数据类型变量和可变数据类型变量,在传入函数的最开始的状态,都和原变量一致,说明函数的参数传递是地址传递。
- 不可变数据类型变量和可变数据类型变量,在函数中只要产生了新对象,内存引用地址都会发生改变。也就是说:对于不可变数据类型变量来说,只有改变了变量的值,就会产生一个新对象,内存地址的引用就会发生改变。(因为前边的结论,对于不可变数据类型变量,相同的值是共用内存地址的)
- 对于可变数据类型变量来说,因为是可变的,所以改变变量的值,内存地址的引用不会发生改变。只有产生了新对象,如
mylist = mylist + [888]
,内存地址的引用才会发生改变。
(3)总结
通过上面的内容,我们可以知道:
- 对于不可变类型变量而言:因为不可变类型变量特性,修改变量需要新创建一个对象,形参的标签转而指向新对象,而实参没有变。
- 对于可变类型变量而言,因为可变类型变量特性,直接在原对象上修改,因为此时形参和实参都是指向同一个对象,所以实参指向的对象自然就被修改了。而如果可变类型变量在函数内的操作创建了新的对象,内存地址的引用也会发生改变,但仅限于在函数内。
(4)补充(重点)
感觉以上的话很啰嗦,在最后整理一下。
看下面例子:
# 交换函数def swap(a, b):# 下面代码实现a、b变量的值交换a, b = b, aprint("swap函数里,a的值是", a, ";b的值是", b)a = 777b = 999print("swap函数里第二次打印,a的值是", a, ";b的值是", b)a = 666b = 888swap(a, b)print("函数交换结束后,变量a的值是", a, ";变量b的值是", b)"""swap函数里,a的值是 888 ;b的值是 666swap函数里第二次打印,a的值是 777 ;b的值是 999函数交换结束后,变量a的值是 666 ;变量b的值是 888"""
1)第一步,执行
swap(a, b)
函数
- 变量a把自己指向的内存地址传递给了函数的形参a,变量b把自己指向的内存地址传递给了函数的形参b。
- 这样变量a和
swap
函数的形参a,都指向了同一个内存地址。变量b和形参b同理。
- 这也说明了上面(1)示例中,变量进入函数的初始索引地址没有变化的原因。
如下图所示:

2)第二步,
swap(a, b)
函数内进行了形参a和形参b的值交换。
也就时执行了
a, b = b, a
命令。
- 形参a和形参b的值进行了交换,因为内存中就有这两个值,所以只是内存地址的引用交互了一下。
- 之后就执行了打印命令,显示"swap函数里,a的值是 888 ;b的值是 666"
如下图所示:
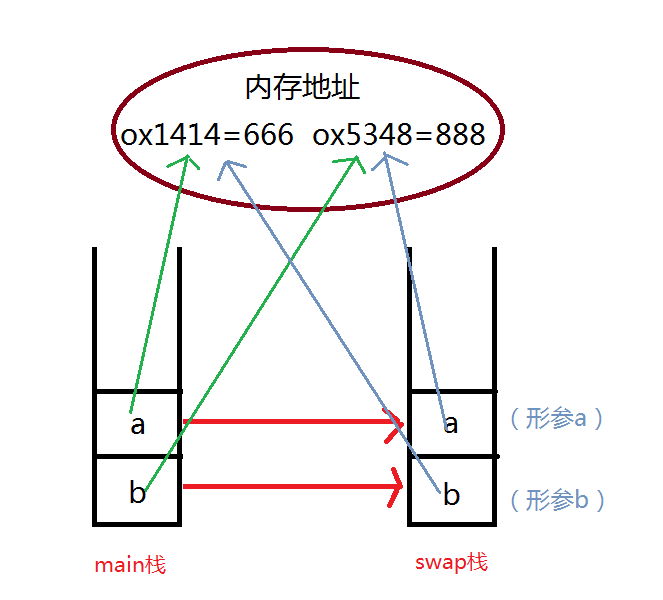
提示:形参a和b就时给函数内的变量起一个名,用于区分。这里说明一下,因为我这样的描述不是很准确。
3)第三步,继续给形参a和b赋予新的值。
- 也就是模拟产生新的对象,并指引到新对象的内存地址上。
- 执行了
a = 777
和
b = 999
,打印结果为“swap函数里第二次打印,a的值是 777 ;b的值是 999”。
如下图所示:
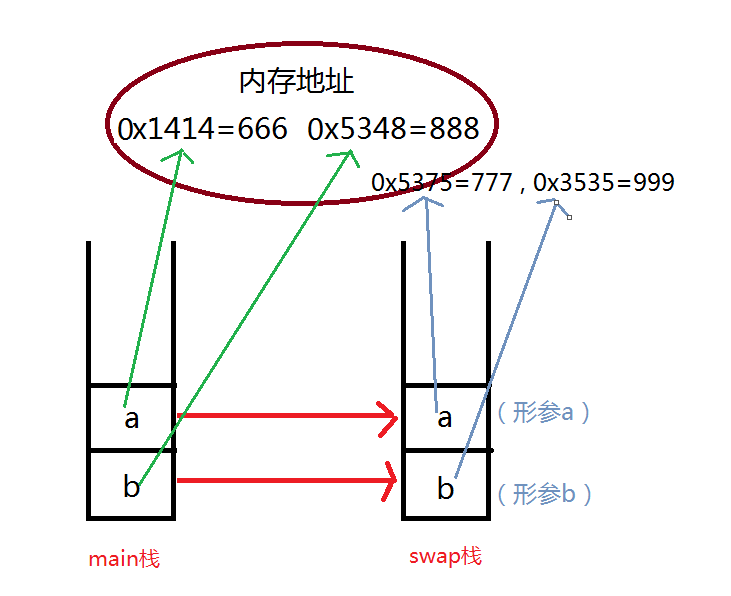
4)第四步,
swap(a, b)
函数执行完毕。
-
swap(a, b)
函数执行完毕,形参a和b的生命周期也就结束了。
- 所以变量a和b在函数结束后的打印结果还是初始的状态,“函数交换结束后,变量a的值是 666 ;变量b的值是 888”。
如下图所示:

5)总结:
所以对于不可变数据类型变量的参数传递,执行外表上看,好像只传递了数值,其实通过上面的例子弹道,也进行了引用地址的传递。
上面使用了不可变数据类型变量进行了示例,可变数据类型变量是一样的,只不过修改变量的内容,地址是不发生改变的。但产生了新的对象,内存地址的引用会到新的对象上,和不可变数据类型变量是一样的。
最后我觉得到现在再来讨论Python中参数的传递是值传递还是引用传递,就会发现在Python里讨论这个确实是没有意义。
参考:http://c.biancheng.net/view/2258.html


