 爱站程序员基地
爱站程序员基地索引的作用
索引是用来高效的获取数据的 排好序 的 数据结构,如果没有索引,可能会导致查询某一条记录的时候遍历整张表;所以适当的索引可以大大的提升检索速度;
索引的数据结构
- 二叉树
假如说我们有一列数据是0-6,我们使用的是二叉树进行存储的话,此时我们可以看到二叉树的存储方式为下图:

- 我们可以看到二叉树如同链表的形式存储了完整的数据,这时我们假设要查值为6的数据,我们就需要七次IO操作才能拿到数据结果;试想假如我们数据过多这时候查询数据就会非常的慢,就相当于全表扫描;
- 所以我们的mysql数据库,肯定是不会用这种数据结构来存储数据;
- 红黑树

- 同样是的存储数据0-6,这时我们会发现红黑树在每次存储的时候,都会动一下;目的就是为了平衡,本质上和二叉树是一样的这里只是多了一步平衡操作,所以红黑树又称平衡二叉树;
- 在查询上我们也可以看到,相比于二叉树来说它做了平衡,树层级相对来说会变小,在我们查找数据的时候IO操作也相对来说少些了;
- mysql也没用这种数据结构,其实我们也应该想的到,一方面数据多了节点一直往下分散还是可能会很多;另一个方面每变动一个节点的时候树都会做平衡花销不可估量;
- hash表
hash 我们知道查找数据的复杂度为O(1)
- 对索引的key进行一次hash计算就可以定位出数据的存储位置;
- 很多时候hsah比b+tree更高效,因为只要hash到对应的key值就能拿到元素;
- 只能满足 "=", "in" 不能范围查找;
- 会存在hash冲突问题(如上图key=2的数据,同一个key存储了两个值,在拿数据的时候会定位到2的数据,然后一次比对拿符合条件的数据);因为本质的复杂度为O(1)特性速度一般会很快,但是我们工作中一般用的不是很多,最根本也是最重要的原因是不支持范围查找,还存在hash冲突的问题;
- b-tree
- 通过上边你的二叉树红黑树我们可以发现都有个共同的问题,就是数据多了层级都会很深查数据都会很慢;这里b-tree就做了一个改进,每个节点可以横向扩展存更多的数据,这时树的层级就会明显变少,减少磁盘IO操作;如下图:
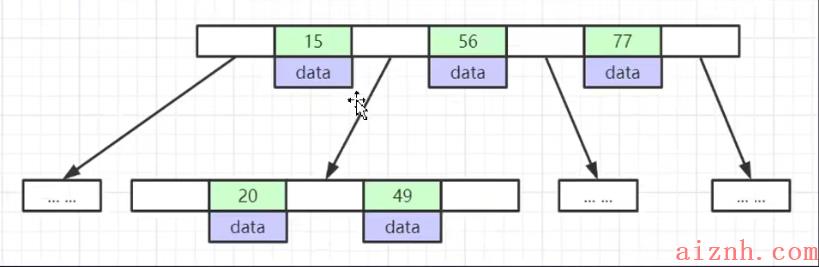
- 上图我们可以看到,节点横向扩展可以存储更多的节点数据, 也就是说一次IO操作我们可以那倒更多的数据,如果不存在时我们就进行下一个节点查询; 我们也可以看到每个索引元素都同时存储了data数据, 也就是说当我们找到索引是可以马上拿到data的; 节点中的数据索引从左到右依次递增;
- mysql也不是用的这种数据结构,毕竟还是存在一些弊端如:

- 每个索引节点都存储了data数据,每个节点的存储空间有限,这时层级也会存在深的情况;
- 没有相邻的双向指针,当范围查找时都需要节点挨个筛选,不利于范围查询;
- 当我们发生修改删除数据时,也会伴随着树节点的变动,从而造成性能上的损耗;
- b+tree
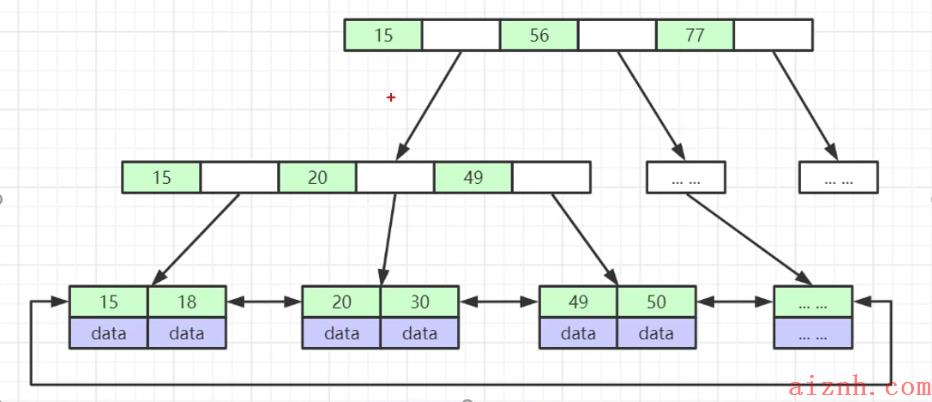
mysql用的就是这种数据结构, 其实b+tree是b-tree的一个变种大概还是一样做了些改进:
- 非叶子节点不存储data数据, 只存储索引,相比于b-tree可以放更多的索引;
- 叶子节点存有data和所有节点的索引字段;
- 叶子节点之间用指针相连接,提升了区间访问的性能;
- 节点中的索引从左到右依次递增;
- 删除数据时只删除叶子节点,非叶子节点不变,不影响整个树的结构;

补充 树中每个节点可以存储16Kb的数据可以用下方sql查询
show GLOBAL STATUS like \'Innodb_page_size\'
那我们来计算下每个节点大概能存储多少数据:
假设我们用bigInt类型当自增主键的话,bigInt也就是上图的索引元素占8个字节,磁盘地址指针mysql默认分配6个字节;也就是说我们一个节点可以存储16Kb/(8+6)B约等于1170个元素;叶子节点因为要存储data元素所以元素个数可能会相对其他节点少,我们假设只存储了15个元素,那么我们一个三阶的树就可以存储 1170117015 约 两千万条数据,也就是说两千万的数据我们只需要三次IO就能拿到值(mysql本身也有做优化非叶子节点会被加载到内存中,也就是说我们取值可能就一次IO就能拿到值,速度会大大提升);
MyISAM 存储引擎
MyISAM 存储引擎中数据存储分三个文件存储分别为 .frm结构 .MYD数据 .MYI索引 三个文件,即为非聚集索引; 上图我们可以看到索引和数据存在不同的文件中,当我们检索数据的时候是先找MYI文件定位到引用地址,再去MYD中拿数据的;
上图我们可以看到索引和数据存在不同的文件中,当我们检索数据的时候是先找MYI文件定位到引用地址,再去MYD中拿数据的;
InnoDB 存储引擎
InnoDB 存储引擎中数据和索引是放在同一个文件中分别为 .frm结构 .idb 两个文件,即为 聚集索引;
- InnoDB 中每个叶子节点存储整条数据的所有字段(如叶子节点索引18,存储的是数据 77 Alice);
- 表文件本身就是一个b+tree树组织的索引结构文件;
- 由于主键和数据都在同一个文件中,所以InnoDB必须要有一个主键,并且建议为自增主键(如果不设主键则mysql会自动的在你的列表中找到一个符合条件的唯一索引字段,如果没有mysql将添加一个类似 ROW_Id 充当主键);
- 非主键索引结构的叶子节点存储的是主键值,是为了实现一致性,节省存储空间;
聚集索引和非聚集索引哪个效率更高
非聚集索引查询到索引值之后,只是拿到了索引所在行的磁盘文件地址,需要通过这个地址再进行一次I/O操作;聚集索引读取到叶子节点索引值之后,即那到了索引所在行的完整的数据内容,不需要额外的I/O操作;
工具辅助
动图树模拟地址:https://www.cs.usfca.edu/~galles/visualization/BST.html;动图制作工具:GifCam工具;



