爱站程序员基地
爱站程序员基地拉链法的 unordered_map 和你想象中的不一样
根据数组+拉链法的描述,我们很快能想到下面这样的拉链法实现的哈希表,但真的是这样吗?一起看下源码里的实现是怎么样的。

深入STL源码
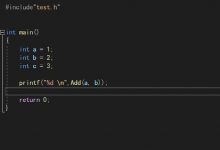
代码不会骗人的,可以写一个简单的代码研究一下实现,然后通过gdb跟踪执行:
#include <vector>#include <unordered_map>int main() {std::unordered_map<int, int> hashmap;hashmap[26] = 26;}
编译和打开gdbgui:
g++ -g hashmap.cc -std=c++11 -o hashmap_testgdbgui -r -p 8000 ./hashmap_test
gdb 跟进发现代码会走到 hashtable_policy.h 的
operator[]
函数中,代码我做了一些简化,只提取了关键代码:
auto operator[](const key_type& __k) -> mapped_type&{__hashtable* __h = static_cast<__hashtable*>(this);// 根据 key 获得 hashcode__hash_code __code = __h->_M_hash_code(__k);// 根据 key 和 hashcode 获得 bucket 的 index:nstd::size_t __n = __h->_M_bucket_index(__k, __code);// 在 bucket n 内尝试找到节点key为k的节点__node_type* __p = __h->_M_find_node(__n, __k, __code);if (!__p){// 如果找到的节点为 nullptr,那么就重新分配一个节点并且将新节点插入到 hash 表中。__p = __h->_M_allocate_node(k);return __h->_M_insert_unique_node(__n, __code, __p)->second;}return __p->_M_v().second;}
operator[]
函数的功能是计算key的hash值,再通过hash值找到对应的
bucket n
,最后在这个bucket内查找是不是有一个
key=k
的节点,如果没有找到需要的节点,就会新分配并且插入一个新的节点。
那么这个节点如何插入的呢?跟进下插入函数
_h->_M_insert_unique_node(__n, __code, __p)
:
auto _M_insert_unique_node(__bkt, __code, __node, size_type __n_elt = 1) -> iterator{// 判断是否需要 rehashconst __rehash_state& __saved_state = _M_rehash_policy._M_state();std::pair<bool, std::size_t> __do_rehash= _M_rehash_policy._M_need_rehash(_M_bucket_count, _M_element_count,__n_elt);if (__do_rehash.first){_M_rehash(__do_rehash.second, __saved_state);__bkt = _M_bucket_index(this->_M_extract()(__node->_M_v()), __code);}this->_M_store_code(__node, __code);// Always insert at the beginning of the bucket.// 将节点插入到 bucket 的开始位置_M_insert_bucket_begin(__bkt, __node);++_M_element_count;return iterator(__node);}
_M_insert_unique_node()
这个插入函数主要作用是判断如果新插入节点,这个hash表的负载会不会过高?需不需要重新扩容,完成扩容后通过
_M_insert_bucket_begin()
再插入到 bucket 的 begin 的位置,这里 rehash 的过程我们暂时不关注,先看下
_M_insert_bucket_begin()
这个函数是怎么实现的:
_M_insert_bucket_begin(size_type __bkt, __node_type* __node){// 判断bucket n 是否为空if (_M_buckets[__bkt]){// Bucket is not empty, we just need to insert the new node// after the bucket before begin.// 如果 bucket 不为空,用头插法将节点插入到开头__node->_M_nxt = _M_buckets[__bkt]->_M_nxt;_M_buckets[__bkt]->_M_nxt = __node;}else{// The bucket is empty, the new node is inserted at the// beginning of the singly-linked list and the bucket will// contain _M_before_begin pointer.// 如果节点不为空,__node->_M_nxt = _M_before_begin._M_nxt;_M_before_begin._M_nxt = __node;if (__node->_M_nxt)// 如果 __node->_M_nxt 也就是原来的 _M_before_begin._M_nxt 不为空,// 那么就要就要把 _M_before_begin._M_nxt 指向新的 node__。// We must update former begin bucket that is pointing to// _M_before_begin._M_buckets[_M_bucket_index(__node->_M_next())] = __node;// 将 _M_before_begin 赋值给 bucket n。_M_buckets[__bkt] = &_M_before_begin;}}
现在就到了插入节点的精彩部分了,当前 bucket 是否为空将函数划分成了两个部分,接下来将用图例的方式来展示整个插入过程。
插入第一个节点
首先先看为空的情况:

在进入函数前,有:
- 预先创建好的(hashmap 构造函数) buckets
- 一个成员变量
_M_before_begin
- 一个新分配出来的插入节点
__p
当前插入的值为26,做完哈希计算
n = 26 % 7 = 5
,那么就会在
bucket[5]
做插入:

当
bucket[5]
为空的插入代码为:
__node->_M_nxt = _M_before_begin._M_nxt; // ①_M_before_begin._M_nxt = __node; // ②if (__node->_M_nxt)_M_buckets[_M_bucket_index(__node->_M_next())] = __node;_M_buckets[__bkt] = &_M_before_begin; // ③
- ①、②两步就是经典链表的头插法,插入到两个节点中间。
- 因为这里
__node->_M_nxt
是指向
nullptr
的,具体的逻辑先跳过。
- 然后第③步将
_M_before_begin
的地址赋值给
bucket
于是得到了一个头插法后的链表:

插入同bucket的第二个节点
如果尝试在同一个 bucket 插入一个新的值,因为当前 bucket 有值,代码就会走到
_M_insert_bucket_begin()
这个函数的前半部分:
if (_M_buckets[__bkt]){// Bucket is not empty, we just need to insert the new node// after the bucket before begin.// 如果 bucket 不为空,用头插法将节点插入到开头__node->_M_nxt = _M_buckets[__bkt]->_M_nxt;_M_buckets[__bkt]->_M_nxt = __node;}

简化得到:

到目前为止和想象中的哈希表还是差不多的,不断的插入到一个 bucket 中,并且用链表连在一起,现在尝试插入一个节点到别的 bucket 中:
在不同的bucket插入一个节点

先会运行 bucket 为空的前两行,仍然是头插法后的结果:
__node->_M_nxt = _M_before_begin._M_nxt;_M_before_begin._M_nxt = __node;

继续运行接下来的语句:
if (__node->_M_nxt)// We must update former begin bucket that is pointing to// _M_before_begin._M_buckets[_M_bucket_index(__node->_M_next())] = __node;_M_buckets[__bkt] = &_M_before_begin;

此时,因为
_M_before_begin._M_nxt
不为空,并且赋值到了新节点
__node
的
_M_nxt
上,此时就会执行逻辑:
_M_buckets[_M_bucket_index(__node->_M_next())] = __node;
__node->_M_next()
也就是 key 为 12 的那个节点,其
bucket_index
应该是5,所以
bucket[5]
的指针将会指向新插入的这个节点。
最后再将
bucket[1]
指向
_M_before_begin
,得到:

继续简化一下,最终其实会形成一个带哨兵节点的单链表,而每个 bucket 只存有一个指向该链表相应位置的指针,其中
_M_before_begin
就是这个哨兵节点:

最终结构
- 在bucket有值的时候,都是通过前一个指针和头插法插入到对应的 bucket 内。
- 如果 bucket 没有值,就会把哨兵节点切换到新的 bucket 中。如:

这么复杂,有什么好处呢?遍历的时间复杂度。
假设在这种实现下,遍历整个 hashmap 只需要从
head
指针不断的像
head->next
移动至
nullptr
,如果总共有 n 个元素,k个bucket,时间复杂度也只有
O(n)
。
如果是最开始那种实现呢?每个bucket一个链表,需要判断所有 bucket 是否为空,并且遍历每个 bucket 内的链表,时间复杂度会到达
O(n + k)
,而且哈希表为了避免哈希冲突,通常会有一个比较大的数组,表达式中的 k 的影响还是挺大的。
验证
插入的代码已经理解了,验证一下理解的结构是不是真的是这样,再看下
hashmap.find(key)
的代码,find 的过程其实在
hashmap.operator[]
中已经有了,插入前判断是不是已经有节点了:
auto operator[](const key_type& __k) -> mapped_type&{__hashtable* __h = static_cast<__hashtable*>(this);// 根据 key 获得 hashcode__hash_code __code = __h->_M_hash_code(__k);// 根据 key 和 hashcode 获得 bucket 的 index:nstd::size_t __n = __h->_M_bucket_index(__k, __code);// 在 bucket n 内尝试找到节点key为k的节点__node_type* __p = __h->_M_find_node(__n, __k, __code);if (!__p){// ... Do allocate and insert}return __p->_M_v().second;}
跟踪下函数
__h->_M_find_node(__n, __k, __code)
,会调用
_M_find_before_node(__n, __k, __code)
:
auto _M_find_before_node(size_type __n, const key_type& __k, __hash_code __code) const -> __node_base*{// _M_buckets[__n] 存储了该 bucket 的 prev,如果不存在,那么这个 bucket 就是空的__node_base* __prev_p = _M_buckets[__n];if (!__prev_p)return nullptr;// 从 prev->next 开始,循环到 prev->next 为nullptr 或者 prev->next 的bucket号不是当前bucket 为止。for (__node_type* __p = __prev_p->_M_nxt; ; __p = __p->_M_next()){if (this->_M_equals(__k, __code, __p))return __prev_p;// 循环结束判断if (!__p->_M_nxt || _M_bucket_index(__p->_M_next()) != __n)break;__prev_p = __p;}return nullptr;}
现在判断当前
bucket
是否有值,如果有值,就开始从
prev->next
开始遍历到 nullptr,或者 bucket 号不是当前bucket的节点。
比如,找一个
bucket[2]
内的节点的开始和结束:
总结
标准库内的 STL 的实现还是非常 Amazing 的,它的实现关键词有三个,数组、单链表和哨兵节点,在支持分桶的情况下,还支持了
O(n)
的遍历复杂度。
另外附上我的参考连接:
- 帮助我理解了
_M_before_begin
节点的作用 https://szza.github.io/2021/03/01/C++/2_/