爱站程序员基地
爱站程序员基地最近一段时间老板管的比较松,就跟着咸鱼大佬的公众号:Python 爬虫进阶必备 自学了一些JS逆向的知识,再加上自己的摸索得比较勤快,感觉还是有一些进步的,这篇文章算是一点点学以致用吧。
目标网站:
aHR0cHM6Ly94YmVpYmVpeC5jb20vYXBpL2JpbGliaWxpLw==
(看到最后的==,你应该知道这是什么编码了吧)
前段时间对B站视频的下载方法比较感兴趣,一路顺着谷歌→GitHub→微信公众号找到了这篇文章:宝藏B站UP主,视频弹幕尽收囊中!
文章写的特别详细,可惜的就是那个下载的接口失效了,于是我就想自己动手试一试。
抓包和定位
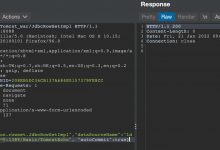
找到提交的表单信息: 表单信息很明显,第一个参数是待解析的B站链接,第二个为是否增强解析的参数,设置为True。预览一下响应内容,可以看到MP4地址这一栏是空着的,那说明这部分内容是动态加载进来的。
表单信息很明显,第一个参数是待解析的B站链接,第二个为是否增强解析的参数,设置为True。预览一下响应内容,可以看到MP4地址这一栏是空着的,那说明这部分内容是动态加载进来的。 预览响应打开开发者模式,映入眼帘的就是一个草泥马,说明这个网站不想让人爬它,但是可惜我还年轻,不讲武德。
预览响应打开开发者模式,映入眼帘的就是一个草泥马,说明这个网站不想让人爬它,但是可惜我还年轻,不讲武德。
破解无限debugger
其实打开开发者模式,第一眼看到的不是草泥马,是一个
debugger
,滑到最上面才看得到草泥马。这个
debugger
会让我们卡在这里,陷入死循环。但是这个其实很好破,右键添加条件断点
Add Conditional breakpoint
,然后条件设为
false
,这个时候无限
debbuger
的反爬就被我们绕过了。 debugger刷新页面,将待解析的b站链接输入文本框并点击“解析视频”,又出现一个
debugger刷新页面,将待解析的b站链接输入文本框并点击“解析视频”,又出现一个
debugger
,用同样的方法解决。
定位加密点
在
hahaha
这里添加一个断点,刷新页面 这时发现MP4地址这里空了,说明这一步是关键的一步。
这时发现MP4地址这里空了,说明这一步是关键的一步。 按
按
F11
进行下一步,发现加密的地方 然后在控制台测试一下,发现这就是我们想要找的MP4下载地址
然后在控制台测试一下,发现这就是我们想要找的MP4下载地址 于是现在我们需要分析一下这个
于是现在我们需要分析一下这个
decrypt
函数。
破解加密策略
点击
decrypt
函数进入他的内部,可以看到所有JS代码都是加了混淆的,代码的可读性变的特别差,例如这样:
function decrypt(_0x55cd15) {
var _0x2b29a5 = CryptoJS[_0x4525(\'0xd\', \'p(J)\')][_0x4525(\'0xe\', \'ZJjv\')][_0x4525(\'0xf\', \'2W(k\')](_0x4525(\'0x10\', \'R!FI\'));
var _0x431fea = CryptoJS[\'enc\'][\'Latin1\'][\'parse\'](_0x4525(\'0x11\', \'N6Ge\'));
var _0x28806e = CryptoJS[_0x4525(\'0x12\', \'U[)g\')][_0x4525(\'0x13\', \'u4yX\')](_0x55cd15, _0x2b29a5, {
\'iv\': _0x431fea,
\'mode\': CryptoJS[\'mode\'][_0x4525(\'0x14\', \'R!FI\')],
\'adding\': CryptoJS[_0x4525(\'0x15\', \'KvSw\')][_0x4525(\'0x16\', \'eITC\')]
})[_0x4525(\'0x17\', \'o*r^\')](CryptoJS[_0x4525(\'0x18\', \'ZH@&\')][_0x4525(\'0x19\', \'o(Cg\')]);
return _0x28806e;
}
于是放弃复现,而是把所有用到的JS代码全部扣出来,然后用Python的
execjs
库来运行这些JS代码。注意这里它用了
CryptoJS
库,这个库可以用
npm install crypto-js
安装到本地后,再用
require
来导入即可。
const CryptoJS = require(\"crypto.js\");
代码实现
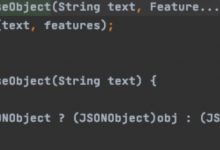
首先定义调用JS代码的Python函数:
def get_js_function(js_path, func_name, *args):
\'\'\'
获取指定目录下的js代码, 并且指定js代码中函数的名字以及函数的参数。
:param js_path: js代码的位置
:param func_name: js代码中函数的名字
:args: js代码中函数的参数
:return: 返回调用js函数的结果
\'\'\'
with open(js_path, encoding=\'utf-8\') as fp:
js = fp.read()
ctx = execjs.compile(js)
return ctx.call(func_name, *args)
然后用正则表达式获取密文
hahaha
,并完成解密,这里的
r.text
是获取到的响应的文本形式。
hahaha = re.search(\"hahaha = \'(.*?)\';\", r.text).group(1)
download_url = get_js_function(\'bilibili.js\', \'decrypt\', hahaha)
需要注意的是,获取得到的下载链接只是一个临时链接,2个小时后就会失效,所以是不能长期用来在线观看的。 url中包含deadline这么一个参数
url中包含deadline这么一个参数