 爱站程序员基地
爱站程序员基地前言
1.代价函数(Cost Function)2.反向传播算法(Backpropagation Algorithm)3.直观理解(Backpropagation Intuition)
神经网络学习
(一)代价函数(Cost Function)
之前我们学习了神经网络模型的前向传播过程,就是输入特征求得输出结果的过程。反向传播算法目的就是优化模型参数,也就是每个神经元上的权值。要想优化参数,第一步就是求出代价函数的表达式,通过最小化代价函数来求得最优参数。在给出神经网络模型的代价函数之前我们先规定一些标记方法,便于讨论。
- m:m:m:神经网络的训练样本
- xxx 和 y:y:y:一组输入和一组输出信号
- L:L:L:神经网络层数
- Sl:S_l:Sl:每层神经元个数,SLS_LSL代表最后一层中处理单元的个数
将神经网络的分类定义为两种情况:二类分类和多类分类
- 二类分类:SL=0,y=0or1S_L=0, y=0 or 1SL=0,y=0or1表示哪一类;
- KKK类分类:SL=k,yi=1S_L=k, y_i = 1SL=k,yi=1表示分到第iii类;(k>2)(k>2)(k>2)
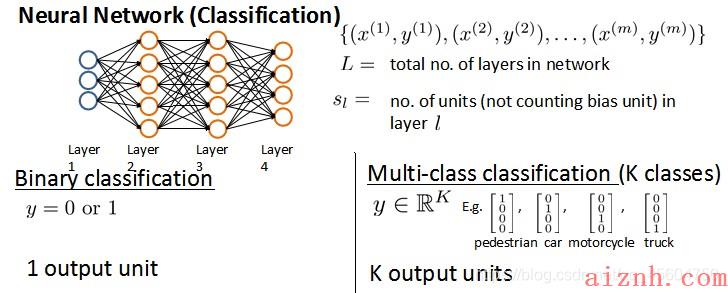
例如,上图神经网络模型是一个4分类, LLL=4,S1S_1S1=3, S2S_2S2= S3S_3S3=5, S4S_4S4=4,它的输出yyy也是相应的向量形式。
我们开始引入代价函数。之前我们学习的逻辑回归的代价函数是这样的: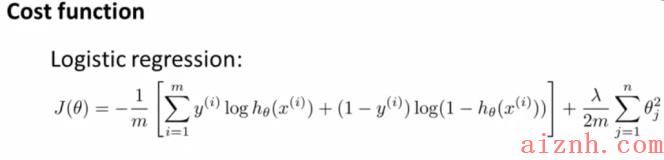
逻辑回归解决的是二元分类(虽然可以解决多元分类,但也是转化为二元分类来解决的),所以最后的输出层只有一个输出变量,y=0y=0y=0或者y=1y=1y=1,而对于神经网络模型,有很多输出变量,我们的hθ(x)h_\\theta(x)hθ(x)是一个维度为KKK的向量,代价函数要将输出层的所有结果累加起来,对于KKK类分类就要累加KKK个结果,进行正则化的时候也要对所有的参数进行正则化(下标不为0的,也就是除去bias项),所以改造后的代价函数如下: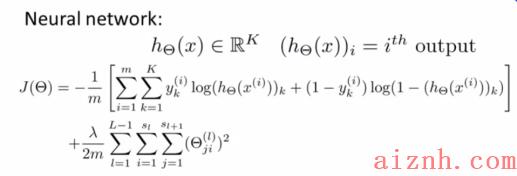
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出KKK个预测,然后在KKK个预测中选择可能性最高的一个,将其与yyy中的实际数据进行比较。
最后的正则化项看起来比较复杂,它是逐层累加模型参数的,最外层控制层数,里面两层控制下标。

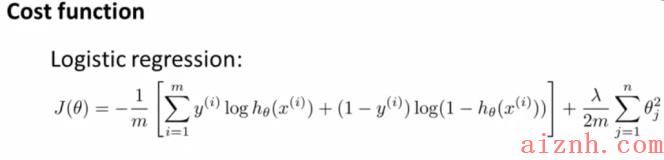
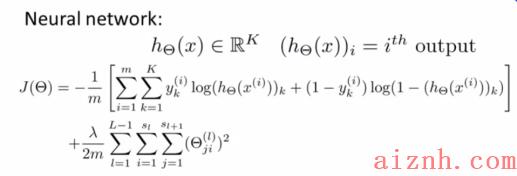
(二)反向传播算法(Backpropagation Algorithm)

我们得到了代价函数,下一步就是最小化代价函数。如果想利用高级优化算法除了代价函数还需要求得每个参数的偏导表达式,反向传播求的就是∂∂Θij(l)J(Θ)\\frac{\\partial}{\\partial\\Theta_{ij}^{(l)}}J(\\Theta)∂Θij(l)∂J(Θ)。我们逐步推导反向传播是如何进行操作的。为了方便,我们假设样本数只有一个,神经网络模型如下:
首先,进行前向传播,过程如下:
反向传播算法的第一步就是计算除输入层的各激活单元的误差,首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。误差是每个激活单元的预测(a(i){a^{(i)}}a(i))与实际值(y(i)y^{(i)}y(i))之间的误差,我们用δ\\deltaδ来表示。对于最后一层,误差可以表示为δ(4)=a(4)−y\\delta^{(4)}=a^{(4)}-yδ(4)=a(4)−y ,这些变量都是4维的。对于前一层的误差是根据最后一层的误差推导来的:δ(3)=(Θ(3))Tδ(4)∗g′(z(3))\\delta^{(3)}=\\left({\\Theta^{(3)}}\\right)^{T}\\delta^{(4)}\\ast g\’\\left(z^{(3)}\\right)δ(3)=(Θ(3))Tδ(4)∗g′(z(3)) 其中 g′(z(3))g\'(z^{(3)})g′(z(3))是导数;再往前一层的误差又可以通过这一层的误差得到:δ(2)=(Θ(2))Tδ(3)∗g′(z(2))\\delta^{(2)}=\\left({\\Theta^{(2)}}\\right)^{T}\\delta^{(3)}\\ast g\’\\left(z^{(2)}\\right)δ(2)=(Θ(2))Tδ(3)∗g′(z(2))。第一层是输入变量,不存在误差,不用计算。其中,可以证明,g′(z(3))=a(3)∗(1−a(3))g\'(z^{(3)})=a^{(3)}\\ast(1-a^{(3)})g′(z(3))=a(3)∗(1−a(3)),g′(z(2))=a(2)∗(1−a(2))g\'(z^{(2)})=a^{(2)}\\ast(1-a^{(2)})g′(z(2))=a(2)∗(1−a(2))。
那么,误差和偏导数有什么关系呢?在没有进行正则化的时候,∂∂Θij(l)J(Θ)=aj(l)δil+1\\frac{\\partial}{\\partial\\Theta_{ij}^{(l)}}J(\\Theta)=a_{j}^{(l)} \\delta_{i}^{l+1}∂Θij(l)∂J(Θ)=aj(l)δil+1。解释一下这些上下标的含义:
-
lll 代表目前所计算的是第几层。
-
jjj 代表目前计算层中的激活单元的下标,也将是下一层的第jjj个输入变量的下标。
-
iii 代表下一层中误差单元的下标,是受到权重矩阵中第iii行影响的下一层中的误差单元的下标。
现在,我们将样本数增加到mmm个,并加上正则化,我们定义一个误差矩阵Δij(l)\\Delta^{(l)}_{ij}Δij(l),代表第 lll 层的第 iii 个激活单元受到第 jjj 个参数影响而导致的误差。
算法过程可以表示如下:
最终偏导结果:
Dij(l):=1mΔij(l)+λΘij(l)D_{ij}^ {(l)} :=\\frac{1}{m}\\Delta_{ij}^ {(l)}+\\lambda\\Theta_{ij}^{(l)}Dij(l):=m1Δij(l)+λΘij(l) if;j≠0{if}; j \\neq 0if;j=0
Dij(l):=1mΔij(l)D_{ij}^ {(l)} :=\\frac{1}{m}\\Delta_{ij}^{(l)}Dij(l):=m1Δij(l) if;j=0{if}; j = 0if;j=0
可以大致总结如下:
(三)直观理解(Backpropagation Intuition)
前向传播:
反向传播:
神经网络细节补充
(一)参数展开(Unrolling Parameters)
- 参数展开就是将参数从矩阵展开成向量,以便我们在高级最优化步骤中的使用需要。
假设有Theta1,Theta2,Theta3和Delta1,Delta2,Delta3,用python将它们展开:
import numpy as npthetaVector = np.r_[Theta1.reshape(-1,1), Theta2.reshape(-1,1), Theta3.reshape(-1,1)]deltaVector = np.r_[ D1.reshape(-1,1), D2.reshape(-1,1), D3.reshape(-1,1) ]
假设:
将它们还原:
Theta1 = thetaVec[0:110].reshape(10,11)Theta2 = thetaVec[110:220].reshape(10,11)Theta3 = thetaVec[220:231].reshape(1,11)
(二)梯度检验(Gradient Checking)
- 使用梯度的数值检验(Numerical Gradient Checking)检查梯度下降算法时,可能会存在一些不容易察觉的错误。
梯度的数值检验其实就是用数学的方法计算导数,某个点对应导数的就是该点变化很小的值的时候,对应的函数变化的值。例如:
θ\\thetaθ点的导数就可以这样表示,θ\\thetaθ点两端各取一很小的值ε\\varepsilonε ,那θ\\thetaθ点的导数就可以这样表示:∂∂θ=J(θ+ε1)−J(θ−ε1)2ε \\frac{\\partial}{\\partial\\theta}=\\frac{J\\left(\\theta+\\varepsilon_1 \\right)-J \\left( \\theta-\\varepsilon_1 \\right)}{2\\varepsilon} ∂θ∂=2εJ(θ+ε1)−J(θ−ε1)
当ε\\varepsilonε的值无穷小时就是导数的定义,但在编程的时候我们不能取无穷小,一般10-4左右最好。当θ\\thetaθ是一个向量的时候,我们可以这样计算:
具体使用的时候,我们只需要在反向传播过程中,用一个循环判断梯度的结果和数值检验的结果是不是相近的来判断梯度下降是否正确。另外说明很重要的一点,由于使用数值的方法计算导数的代价非常大,所以在验证我们的代码没有问题之后,一定要关闭数值检验。
补充一个课堂上的小问题,答案选第二个
(三) 随机初始化(Random Initialization)
开始学习时,我们都要为参数赋初值。在之前的线性回归和逻辑回归中,我们都为参数赋值为0,这是可行的。但是在神经网络模型中,如果都是赋值为0,这将意味着我们第二层的所有激活单元都会有相同的值,第三层直到最后一层都是相同的结果。在反向传播中,你也会发现所有的误差也是一样的,这样大部分的模型参数就不能发挥作用了,这种现象我们称为“对称现象”。仔细思考,并不是赋值为0才会导致这种现象,赋值为其他相同的数字也会导致这种现象,甚至在某一层使用相同的数字也会导致,所以我们需要对参数进行随机初始化。
我们通常初始参数为正负ε之间的随机值,假设我们要随机初始一个尺寸为10×11的参数矩阵:
Theta1 = rand(10, 11) * (2*eps) – eps
(四)综合起来( Putting It Together)
- 第一步:选择网络结构,即决定选择多少层以及决定每层分别有多少个单元
硬性要求只有两个:第一层的单元数即我们训练集的特征数量;最后一层的单元数是我们训练集的结果的类的数量。如果隐藏层数大于1,尽量使得每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
一般,我们选择只有一层隐藏层的作为默认网络结构。
- 第二步:训练神经网络
参数的随机初始化
利用前向传播方法计算所有的hθ(x)h_{\\theta}(x)hθ(x)
编写计算代价函数 JJJ 的代码
利用反向传播方法计算所有偏导数
利用数值检验方法检验这些偏导数
使用优化算法来最小化代价函数



