 爱站程序员基地
爱站程序员基地飞桨PaddlePaddle百度架构师手把手带你零基础实践深度学习——第一周实践作业理解
- 对飞桨的理解
- 第一周实践作业
对飞桨的理解
以前自己也学习和实践过DL,但不够系统,掌握DL知识都是比较零散。通过上一周学习毕然老师讲解的课程,对DL有了更清晰的理解,发现用飞桨去实现DL项目确实是比较简单。
-
可以流程化来构建神经网络模型 ,通过下面的步骤,调用各种API,可以很方便的搭建神经网络模型;
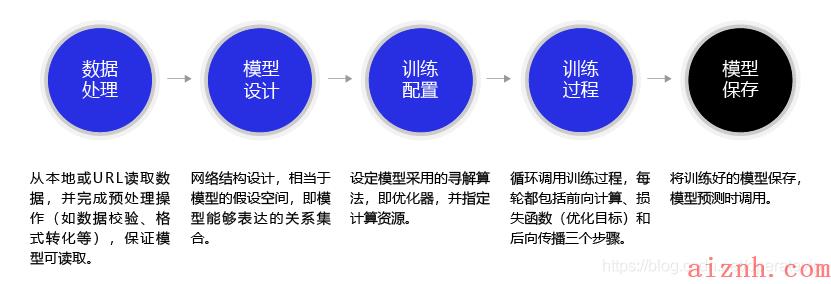
-
“横纵式”教学法使得大家可以轻松掌握构建复杂神经网络模型的方法,当然少不了毕然老师的讲解;
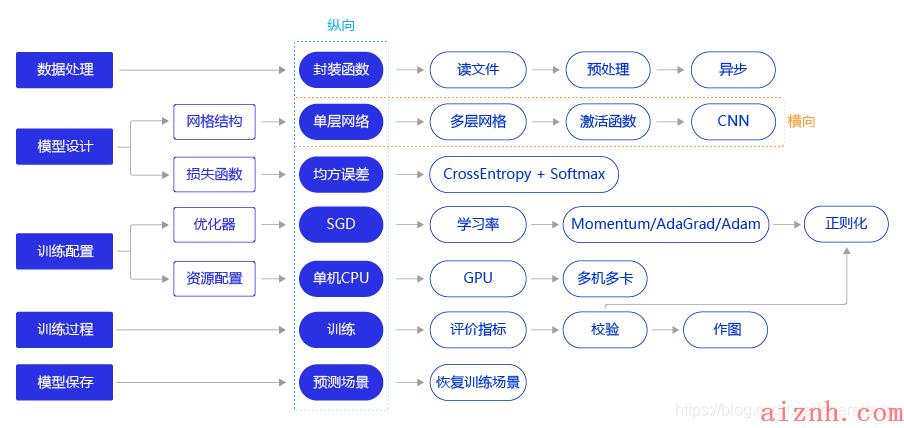
总而言之,飞桨平台确实能够轻松实现DL项目。闲话少说,下面分享第一周实践作业。


第一周实践作业
作业任务:
从原始mnist数据集中,『随机抽取』100张图片,测试模型的分类准确率。
作业实现:
通过完成这个作业,让我掌握了数据处理(读入数据、划分数据集、生成批次数据、训练样本集乱序、校验数据有效性)、网络结构设计、训练配置、学习率设置、前向计算、调用损失函数、后向传播,还有模型保存、恢复以及图表显示loss变化,最后使用训练好的模型测试,准确率>99%,效果还是不错的
import osimport randomimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linearimport numpy as npfrom PIL import Imageimport gzipimport json# 定义数据集读取器def load_data(mode=\'train\'):# 数据文件datafile = \'./data/data49109/mnist.json.gz\'print(\'loading mnist dataset from {} ......\'.format(datafile))data = json.load(gzip.open(datafile))train_set, val_set, eval_set = data# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLSIMG_ROWS = 28IMG_COLS = 28if mode == \'train\':imgs = train_set[0]labels = train_set[1]elif mode == \'valid\':imgs = val_set[0]labels = val_set[1]elif mode == \'eval\':imgs = eval_set[0]labels = eval_set[1]imgs_length = len(imgs)assert len(imgs) == len(labels), \\\"length of train_imgs({}) should be the same as train_labels({})\".format(len(imgs), len(labels))index_list = list(range(imgs_length))# 读入数据时用到的batchsizeBATCHSIZE = 100# 定义数据生成器def data_generator():#训练集打乱顺序#if mode == \'train\':#根据作业要求,『随机抽取』图片测试模型的分类准确率,因此,测试集数据也要打乱顺序if mode == \'train\' or mode == \'eval\':random.shuffle(index_list)imgs_list = []labels_list = []for i in index_list:img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype(\'float32\')label = np.reshape(labels[i], [1]).astype(\'int64\')imgs_list.append(img)labels_list.append(label)if len(imgs_list) == BATCHSIZE:yield np.array(imgs_list), np.array(labels_list)imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator#调用加载数据的函数train_loader = load_data(\'train\')# 定义模型结构class MNIST(fluid.dygraph.Layer):def __init__(self):super(MNIST, self).__init__()# 定义一个卷积层,使用relu激活函数self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act=\'relu\')# 定义一个池化层,池化核为2,步长为2,使用最大池化方式self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type=\'max\')# 定义一个卷积层,使用relu激活函数self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act=\'relu\')# 定义一个池化层,池化核为2,步长为2,使用最大池化方式self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type=\'max\')# 定义一个全连接层,输出节点数为10self.fc = Linear(input_dim=980, output_dim=10, act=\'softmax\')# 定义网络的前向计算过程def forward(self, inputs, label):x = self.conv1(inputs)x = self.pool1(x)x = self.conv2(x)x = self.pool2(x)x = fluid.layers.reshape(x, [x.shape[0], 980])x = self.fc(x)if label is not None:acc = fluid.layers.accuracy(input=x, label=label)return x, accelse:return x#训练了五轮(epoch)。在每轮结束时,均保存了模型参数和优化器相关的参数。#在使用GPU机器时,可以将use_gpu变量设置成Trueuse_gpu = Falseplace = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()#引入matplotlib库#使用Matplotlib库绘制损失随训练下降的曲线图#将训练的批次编号作为X轴坐标,该批次的训练损失作为Y轴坐标。import matplotlib.pyplot as pltwith fluid.dygraph.guard(place):model = MNIST()model.train()#训练开始前,声明两个列表变量存储对应的批次编号(iters=[])和训练损失(losses=[])。iter=0iters=[]losses=[]EPOCH_NUM = 5BATCH_SIZE = 100# 定义学习率,并加载优化器参数到模型中total_steps = (int(60000//BATCH_SIZE) + 1) * EPOCH_NUMlr = fluid.dygraph.PolynomialDecay(0.01, total_steps, 0.001)# 使用Adam优化器optimizer = fluid.optimizer.AdamOptimizer(learning_rate=lr, parameter_list=model.parameters())#四种优化算法的设置方案,可以逐一尝试效果#optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())#optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=0.01, momentum=0.9, parameter_list=model.parameters())#optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.01, parameter_list=model.parameters())#optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01, parameter_list=model.parameters())for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁image_data, label_data = dataimage = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)#前向计算的过程,同时拿到模型输出值和分类准确率predict, acc = model(image, label)avg_acc = fluid.layers.mean(acc)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.cross_entropy(predict, label)avg_loss = fluid.layers.mean(loss)#每训练了200批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print(\"epoch: {}, batch: {}, loss is: {}, acc is {}\".format(epoch_id, batch_id, avg_loss.numpy(),avg_acc.numpy()))#随着训练的进行,将iter和losses两个列表填满。iters.append(iter)losses.append(avg_loss.numpy())iter = iter + 100#后向传播,更新参数的过程avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()# 保存模型参数和优化器的参数fluid.save_dygraph(model.state_dict(), \'./checkpoint/mnist_epoch{}\'.format(epoch_id))fluid.save_dygraph(optimizer.state_dict(), \'./checkpoint/mnist_epoch{}\'.format(epoch_id))#保存模型参数fluid.save_dygraph(model.state_dict(), \'mnist\')#定义一个train_again()训练函数,加载模型参数并从第一个epoch开始训练,以便读者可以校验恢复训练后的损失变化。def train_again():params_path = \"./checkpoint/mnist_epoch0\"#在使用GPU机器时,可以将use_gpu变量设置成Trueuse_gpu = Falseplace = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()with fluid.dygraph.guard(place):# 加载模型参数到模型中params_dict, opt_dict = fluid.load_dygraph(params_path)model = MNIST()model.load_dict(params_dict)EPOCH_NUM = 5BATCH_SIZE = 100# 定义学习率,并加载优化器参数到模型中total_steps = (int(60000//BATCH_SIZE) + 1) * EPOCH_NUMlr = fluid.dygraph.PolynomialDecay(0.01, total_steps, 0.001)# 使用Adam优化器optimizer = fluid.optimizer.AdamOptimizer(learning_rate=lr, parameter_list=model.parameters())optimizer.set_dict(opt_dict)for epoch_id in range(1, EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁image_data, label_data = dataimage = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)#前向计算的过程,同时拿到模型输出值和分类准确率predict, acc = model(image, label)avg_acc = fluid.layers.mean(acc)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.cross_entropy(predict, label)avg_loss = fluid.layers.mean(loss)#每训练了200批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print(\"epoch: {}, batch: {}, loss is: {}, acc is {}\".format(epoch_id, batch_id, avg_loss.numpy(),avg_acc.numpy()))#后向传播,更新参数的过程avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()#测试训练恢复功能#train_again()#训练结束后,将两份数据以参数形式导入PLT的横纵坐标。画出训练过程中Loss的变化曲线plt.figure()plt.title(\"train loss\", fontsize=24)plt.xlabel(\"iter\", fontsize=14)plt.ylabel(\"loss\", fontsize=14)plt.plot(iters, losses,color=\'red\',label=\'train loss\')plt.grid()plt.show()#从测试的效果来看,模型在整个测试集上有99%的准确率,随机抽取100张图片的准确率为100%,证明它是有预测效果的。with fluid.dygraph.guard():print(\'start evaluation .......\')#加载模型参数model = MNIST()model_state_dict, _ = fluid.load_dygraph(\'mnist\')model.load_dict(model_state_dict)model.eval()eval_loader = load_data(\'eval\')acc_set = []avg_loss_set = []for batch_id, data in enumerate(eval_loader()):x_data, y_data = dataimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)prediction, acc = model(img, label)loss = fluid.layers.cross_entropy(input=prediction, label=label)avg_loss = fluid.layers.mean(loss)acc_set.append(float(acc.numpy()))avg_loss_set.append(float(avg_loss.numpy()))#『随机抽取』100张图片,测试模型的分类准确率,BATCHSIZE为100break#计算多个batch的平均损失和准确率acc_val_mean = np.array(acc_set).mean()avg_loss_val_mean = np.array(avg_loss_set).mean()print(\'loss={}, acc={}\'.format(avg_loss_val_mean, acc_val_mean))
下面是运算结果,准确率达到99%以上,甚至100%,效果很不错:


期待本周的课程!!!



