 爱站程序员基地
爱站程序员基地ECCV 2018 北京大学
Abstract
找出完全表征对象的细微特征并不简单(细粒度分类的挑战性)
文章提出新颖的自监督(self-supervision)机制,无需bbox和part annotations,即可有效定位信息区域。
模型:NTS-Net( Navigator-Teacher-Scrutinizer Network)== Navigator agent,Teacher agent和Scrutinizer agent组成
考虑到informativeness of the regions与ground-truth class概率之间的内在一致性,设计了一种新颖的训练机制,使Navigator能够在Teacher的指导下检测大部分信息区域(informative regions)。之后,Scrutinizer仔细检查Navigator中建议区域(proposed regions)并进行预测。
1 Introduction
细粒度分类的挑战来源于信息区域(informative regions)和提取其中的判别区域(discriminative features)。深度学习的兴起
总结最近的工作
- 监督学习:需要bbox和part annotation人工注释,但是代价昂贵,在实际生活中不常用
- 无监督学习:learning scheme to localize informative regions,缺点是缺乏保证模型聚焦于正确区域的机制,这通常会导致精度降低。
NTS-Net工作机制
- Navigator关注最具信息性的区域:对于图像中的每个区域,Navigator预测区域的信息量,并使用预测来提出(propose)信息量最大的区域。
- Teacher评估Navigator建议的区域并提供反馈:对于每个建议区域(proposed region),Teacher评估其属于ground-truth class的概率;置信度评估(confidence evaluation)指导Navigator用其提出的排序一致(ordering-consistent)损失函数来提出更多信息区域。
- Scrutinizer仔细检查Navigator中建议区域并完成细粒度分类:每个建议区域被resize到相同的大小,并且Scrutinizer提取其中的特征;区域特征和整个图像的特征被联合处理,以完成细粒度分类。
该方法可以看作是强化学习中的actor-critic机制,其中Navigator是actor,Teacher是critic。通过Teacher提供的更精确的监督,Navigator将定位更多信息区域,这反过来将有利于Teacher。因此,agents共同进步并最终得到一个模型,该模型提供准确的细粒度分类预测以及更大的信息区域。
2 Related Work
2.1 Fine-grained classification ~
2.2 Object detection ~
2.3 Learning to rank
$X = KaTeX parse error: Expected \’}\’, got \’EOF\’ at end of input: {X_1,X_2,…,X_n$} denote the objects to rank
$Y = KaTeX parse error: Expected \’}\’, got \’EOF\’ at end of input: {Y_1,Y_2,…,Y_n$} the indexing of the objects, where Yi≥YjY_i≥Y_jYi≥Yj means XiX_iXi should be ranked before XjX_jXj
FFF :ranking function that minimize a certain loss function.(就是给定一个X到Y的映射函数F,loss最小)
ranking methods:
- point-wise approach
给每个数据assign一个数值,然后就可以转化为回归问题,如:

- pair-wise approach
假定F(Xi,Xj)F(X_i,X_j)F(Xi,Xj)只有两种取值{0,1},F(Xi,Xj)=0F(X_i,X_j) = 0F(Xi,Xj)=0 means XiX_iXi ranked before XjX_jXj.(排序正确)
the goal is to find an optimal F to minimize the average number of pairs with wrong order.

- list-wise approach
直接优化整个列表,F(X,Y)F(X,Y)F(X,Y) is the ranking function

该论文中navigator loss function 使用的是multi-rating pair-wise ranking loss(多等级两两排序损失)
3 Methods
模型框架

一一介绍:navigator、teacher、scrutinizer
3.1 Approach Overview
假设:信息区域(information regions)可以更好的表征对象,所以融合信息区域和全图像的特征可以获得更好的性能
目标:localize the most informative regions。
假设所有的区域都是矩形
符号说明:
-
A :给定图像中所有的区域集合
-
information function III:给定区域 R∈AR∈AR∈A,评价其所含信息多少,即 A—>(−∞,∞)A —>(-∞,∞)A—>(−∞,∞)
-
confidence function CCC:A—>[0,1]A —>[0,1]A—>[0,1],表示区域属于ground-truth class的置信度
more informative regions should have higher confidence,
使用Navigator网络来近似information function III 和Teacher网络来近似 confidence function CCC.
Navigator网络评估其informativeness I(Ri)I(R_i)I(Ri),Teacher网络评估其confidence C(Ri)C(R_i)C(Ri)。
为了满足Condition1,优化Navigator网络使 { $ I(R_1),I(R_2),…,I(R_M) $}和 { $ C(R_1),C(R_2),…,C(R_M) $}具有相同的顺序。
随着Navigator网络根据Teacher网络的改进,它将产生更多信息区域,以帮助Scrutinizer网络产生更好的细粒度分类结果。
3.2 Navigator and Teacher
受到anchor的启发,对于输入的图像,得到一组矩形区域 {R1′,R2′,…,RA′R_1\’,R_2\’,…,R_A\’R1′,R2′,…,RA′},其中每个anchor都有一个信息量分数。
input image size=448, scales = {48,96,192}, ratios={1:1,2:3,3:2},对所有anchors进行信息量排序
其中,A表示anchors数量,I(Ri)I(R_i)I(Ri)表示信息排序列表中第i个元素。
使用NMS减少冗余的区域,将信息排序列表中的前M个区域 {R1,R2,…,RMR_1,R_2,…,R_MR1,R2,…,RM}输入到teacher网络中来获得其置信度为{C(R1),C(R2),…,C(RM)C(R_1),C(R_2),…,C(R_M)C(R1),C(R2),…,C(RM)},其中M是个超参数
优化navigator网络的目标:优化navigator网络使得{I(R1),I(R2),…,I(RM)I(R_1),I(R_2),…,I(R_M)I(R1),I(R2),…,I(RM)}和{C(R1),C(R2),…,C(RM)C(R_1),C(R_2),…,C(R_M)C(R1),C(R2),…,C(RM)}具有相同的顺序。
优化teacher网络的目标:最小化ground-truth class和predicted confidence之间的交叉熵损失。
3.3 Scrutinizer
随着Navigator network逐渐收敛,它将产生信息性的对象特征区域,以帮助Scrutinizer network做出决策。 我们使用前K个信息区域与完整图像相结合作为输入来训练Scrutinizer network。 即那些K个区域用于促进细粒度识别。

[25]表明使用信息区域能减少类内差异,并可能在正确的标签上产生更高的置信度。通过对比实验表明,添加信息区域可以显著地改善大部分数据集的细粒度分类结果,包括cub200 -2001、FGVC Aircraft and Stanford Cars.
3.4 Network architecture
feture extractor:在ILSVRC2012数据集上pretrain好的ResNet-50
符号说明:
- W:feature extractor中的参数
- X:input iamge
- X ⨂\\bigotimes⨂ W: extracted deep representations 提取到的深层特征表示
Navigator network
类似于Feature Pyramid Networks(FPN)结构,在不同尺度Feature maps上生成多个候选框,(较大feature map的anchors对应较小的区域),这样不同尺度下的feature map中的anchors就能产生不同大小的informative regions。
settings:
- feature map size:{14×14,7×7,4×4} corresponding to regions of scale {48×48,96×96,192×192}
- navigator网络中的参数:WIW_IWI (包括在feature extrator中的共享参数)
每个候选框的坐标与预先设计好的Anchors相对应。Navigator做的就是给每一个候选区域的“信息量”打分,信息量大的区域分数高。
Teacher network.
作用: C:A→[0,1]C:A \\rightarrow [0,1]C:A→[0,1]
输入:M个来自navigator网络的scale-normalized(224×224)个信息区域{R1,R2,…,RMR_1,R_2,…,R_MR1,R2,…,RM}
输出confidence score:判断区域属于target label的概率
结构:Feature Extractor + FC(2048) + softmax
- WCW_CWC:teacher网络的参数
Scrutinizer network
输入:在navigator网络中选取的top-K个信息区域,resize成预定义好的size(该论文使用224×224)
然后送到feature extractor中,生成K个区域特征向量,each with length=2048
然后将这k个特征向量+原图feature进行concatenate成(K+1)*2048送入FC
符号说明:
- S:transformation的组合
- WSW_SWS:Scrutinizer网络的参数
3.5 Loss function and Optimization
Navigation loss.
R = {R1,R2,…,RMR_1,R_2,…,R_MR1,R2,…,RM}:表示由navigator预测的前M个最有信息量的区域,I = {I1,I2,…,IMI_1,I_2,…,I_MI1,I2,…,IM}:表示其信息量
C = {C1,C2,…,CMC_1,C_2,…,C_MC1,C2,…,CM}:表示由teacher网络预测的confidence
navigator loss:
 \”>
\”>
其中 Ii=I(Ri)I_i = I(R_i)Ii=I(Ri)
函数 f:hinge loss function
反向传播:


**Teaching loss **
The first term in Eq. 7 is the sum of cross entropy loss of all regions, the second term is the cross entropy loss of full image.

**Scrutinizing loss. **
navigator网络得到K个最有信息量的regions {R1,R2,…,RKR_1,R_2,…,R_KR1,R2,…,RK}
Scrutinizer网络做出细粒度分类结果 P=S(X,R1,R2,…,RK)P = S(X,R_1,R_2,…,R_K)P=S(X,R1,R2,…,RK)
loss为交叉熵损失:

total loss
λ\\lambdaλ和μ\\muμ是超参数,作者设置为λ=μ=1\\lambda = \\mu = 1λ=μ=1
优化器SGD
流程图:

4 Experiments
4.1 Dataset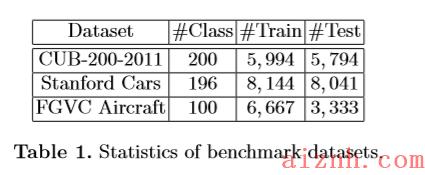

4.2 Implementation Details
preprocess image:resize 448×448
M=6
feature extractor:ResNet-50
Momentum SGD :initial lr =0.001,60个epoch后衰减为原来的0.1,weight decay=1e-4
NMS阈值=0.25
4.3 Quantitative Results
ResNet-50 is a strong baseline, which by itself achieves 84.5% accuracy, while our proposed NTS-Net outperforms it by a clear margin 3.0%.(ResNet-50实现84.5%的准确率是在CUB数据集上吗?)
与同样使用ResNet-50作为特征提取器的[26]相比,我们获得了1.5%的改进。值得注意的是,当我们只使用完整的图像(即令K = 0)作为输入到Scrutinizer,我们实现了85.3%的准确性,这也高于ResNet-50。


HBP使用caffe的acc为87.1%,backbone为vgg,那采用ResNet-50的acc应该会有提升,但是现在HBP pytorch的acc为83.9%,NTS-Net的acc为 87.5%,还是有明显的提升
4.4 Ablation Study
table 4.
-
NS-Net表示没有使用Teacher network,acc从87.5%下降为83.3%,原因:因为navigator没有受到teacher的监督,会提出随机的区域,作者认为这不利于分类。
-
对于超参K,K=2——>K=4时,acc上升0.2%,但是feature维度几乎加倍,但是K=0——>K=2,acc上升2%表明multi-agent的优势。
4.5 Qualitative Results

可视化部分:To analyze where Navigator network navigates the model。
选择前4个信息量最多的部分,red>orange>yellow>green
Fig.5第一行,对应前两个信息量最多的区域,即K=2,从第二张图片可以看出,鸟跟背景相似也可以做出比价好的定位
从该图可以看出,信息量最多的地方为 头部、翅膀、身体,这跟人的认知是一样的。

![[翻译] Backpressure explained — the resisted flow of data through software-爱站程序员基地](https://aiznh.com/wp-content/uploads/2021/05/1-220x150.jpeg)

