 爱站程序员基地
爱站程序员基地AI课堂开讲,就差你了!
很多人说,看了再多的文章,可是没有人手把手地教授,还是很难真正地入门AI。为了将AI知识体系以最简单的方式呈现给你,从这个星期开始,芯君邀请AI专业人士开设“周末学习课堂”——每周就AI学习中的一个重点问题进行深度分析,课程会分为理论篇和代码篇,理论与实操,一个都不能少!
来,退出让你废寝忘食的游戏页面,取消只有胡吃海塞的周末聚会吧。未来你与同龄人的差异,也许就从每周末的这堂AI课开启了!

本周,我们继续讨论上次在课堂结尾时提出的问题。

数学准备
• 贝叶斯定理: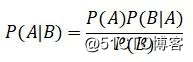 ,它的意义是,在B发生的情况下,A发生的概率。在贝叶斯框架下,P(A)叫做先验概率,P(B|A)叫做似然,P(B)是证据因子,P(A|B)叫做后验概率。
,它的意义是,在B发生的情况下,A发生的概率。在贝叶斯框架下,P(A)叫做先验概率,P(B|A)叫做似然,P(B)是证据因子,P(A|B)叫做后验概率。
• 朴素贝叶斯:基于贝叶斯定理的分类器,需要估计类先验概率P(l)和属性的类条件概率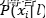 ,为计算联合概率,引入了属性独立性假设。
,为计算联合概率,引入了属性独立性假设。
• 共轭先验:如果先验分布与后验分布属于同一类型的分布,那么我们将先验分布称为似然函数的共轭先验。比如,高斯分布对于高斯类型的似然函数是其自身的共轭先验,也就是说如果先验是高斯,似然函数也是高斯,那么后验也会是高斯。

传统朴素贝叶斯的局限
在上一篇《基于贝叶斯推断的分类模型》中,我们详细讨论了朴素贝叶斯的细节,但拓展时会出现两个问题:
• 属性值由离散变为连续,属性的类条件概率将变得无法计算(因为每个属性值可能只出现一次)。
• 由分类问题变为回归问题,target也由离散变得连续,类先验概率也变得无法计算(因为每个目标值可能只出现一次),更重要的是,我们无法像分类问题一样计算类后验概率。
第一个问题的实质在于:属性的取值一旦由离散变得连续,我们就不能用频率来估计概率。但是我们可以用一个概率密度函数来指定属性的类条件概率的估计,比如我们可以令条件概率为一个高斯分布:
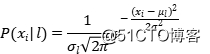
高斯分布由两个参数(均值和标准差)唯一确定,我们在训练分类器的过程,其实就是对每个属性的每个类条件概率的参数进行估计,这里面所用的方法就是极大似然估计。

极大似然估计(Maximum Likelihood Estimation)
似然,也就是条件概率P(A|B),是给定条件B后,事件A发生的概率。如果模型携带参数,那么条件概率的意思就是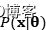 就是给定参数,数据出现的概率,极大似然法选择最大化条件概率
就是给定参数,数据出现的概率,极大似然法选择最大化条件概率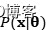 ,本质意义上是我们在很多参数中选择一个能使数据出现概率最大的参数。
,本质意义上是我们在很多参数中选择一个能使数据出现概率最大的参数。
如果我们假设数据独立同分布,那么样本同时出现的概率就可以写成每个样本出现概率的乘积,条件概率就可以写成连乘:
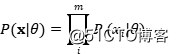
因为大量小的概率连乘可能会造成下溢:实际上,我们更容易最大化似然的自然对数,而不是其本身,我们就会得到对数似然:
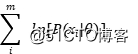
我们会看到,很多携带参数的模型的优化函数都可以从最大似然估计推导而来。
Example:简单线性模型并不简单
我们在《过拟合问题》中,曾经提到过简单线性模型的最小二乘估计,并且给出了它的优化目标,也就是均方误差,对于固定容量的样本,我们就有:
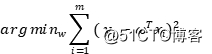
事实上,简单线性模型假设我们的目标值图片服从高斯分布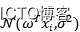 ,它的均值为
,它的均值为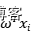 ,标准差未知但固定,最大化对数似然就是最大化高斯分布:
,标准差未知但固定,最大化对数似然就是最大化高斯分布:
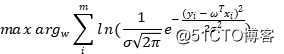
利用对数的性质,就可以将其拆开:
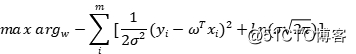
其中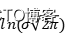 是常数,最大化对数似然相当于最小化其负值,所以,我们有:
是常数,最大化对数似然相当于最小化其负值,所以,我们有:
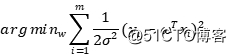
其中标准差图片是一个固定的数,不参与优化。这样,我们通过极大似然估计就可以推导出简单线性模型的优化函数。

最大后验估计(Maximum A Posteriori Estimation)
极大似然估计(MLE)只考虑了似然函数的最大化,本质意义上是我们在很多参数中选择一个能使数据出现概率最大的参数。
然而根据贝叶斯定理,最大化后验概率具有根本不同的意义,因为在极大似然估计仍然把潜在的参数看作定值,我们需要做的只是去寻找这个定值。而最大后验估计却是将参数值看作随机变量,它本身就是一个分布,而不是定值。
贝叶斯定理的分母,是一个关于数据x的边缘概率,而参数只是作为积分变量,在优化中不会起作用。所以,后验概率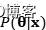 表示的是似然
表示的是似然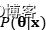 与先验
与先验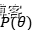 的乘积,而我们只需要把最大似然估计中的目标改为:
的乘积,而我们只需要把最大似然估计中的目标改为:
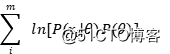
就得到了我们最大化后验概率的形式。
Example:简单线性模型的正则化
在《过拟合问题》中,同样提到了简单线性模型的正则化,比如说我们的岭回归(Ridge Regression),它的优化函数为:
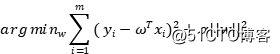
我们在前面说,简单线性模型假设我们的目标值图片服从高斯分布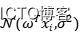 ,事实上,
,事实上,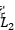 正则化则对应着参数的高斯先验分布:我们的参数服从高斯分布
正则化则对应着参数的高斯先验分布:我们的参数服从高斯分布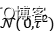 。根据贝叶斯定理,我们用最大化后验概率来估计参数,实际上只是在对数似然上添加了先验的对数:
。根据贝叶斯定理,我们用最大化后验概率来估计参数,实际上只是在对数似然上添加了先验的对数:
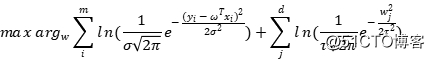
我们继续将其展开:
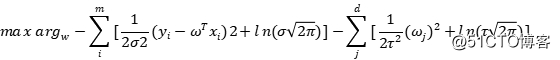
最大化对数似然就是最小化其负值,同时省略其中的常数项,我们就会得到:
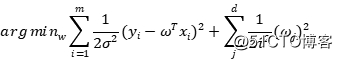
标准差图片是常数,不参与优化。这样,我们就得到了岭回归的优化函数。

贝叶斯线性回归(Bayesian Linear Regression)
我们已经看到,简单线性模型假设我们的目标值图片服从高斯分布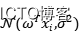 ,接下来就是极大似然法来估计参数,一旦得到参数,整个学习就结束了。贝叶斯线性回归也是估计参数,但是应用了贝叶斯定理,我们不仅要考虑似然,还要考虑先验以及证据因子:
,接下来就是极大似然法来估计参数,一旦得到参数,整个学习就结束了。贝叶斯线性回归也是估计参数,但是应用了贝叶斯定理,我们不仅要考虑似然,还要考虑先验以及证据因子:
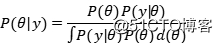
其中,参数图片只是一个向量,用来表示分布的参数。最重要的地方在于,所谓的后验概率是结果出现之后对概率的修正,从贝叶斯的视角看待整个数据集,我们会把样本的每个点进行增量计算,对于初始点,我们假设先验和似然,计算出它的后验,然后将初始点的后验估计当作下一次(两个样本点)估计的先验,如此反复,直到计算完毕整个数据集。可以想象到,随着样本的增加,我们的估计会越来越准确。
出于解析的目的,我们选取自共轭先验,我们假设似然函数服从高斯分布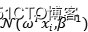 ,参数会变成
,参数会变成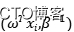 ;如果我们继续假设先验分布服从高斯分布图
;如果我们继续假设先验分布服从高斯分布图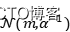 ,由于高斯分布的自共轭的性质,我们的后验分布也会是一个高斯分布,我们可以通过贝叶斯定理将后验高斯分布的参数用其余参数来表示:
,由于高斯分布的自共轭的性质,我们的后验分布也会是一个高斯分布,我们可以通过贝叶斯定理将后验高斯分布的参数用其余参数来表示:
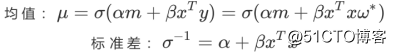
这里,我们要注意三点:
•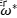 是我们对似然函数进行极大似然估计的参数值,对似然参数的估计可以独立进行。
是我们对似然函数进行极大似然估计的参数值,对似然参数的估计可以独立进行。
• 后验分布的均值由两部分组成,一部分是先验的参数,另一部分是似然的参数,先验的精度越高(标准差越小),其对后验均值的影响就越大(体现为权重越大)。
• 贝叶斯回归的过程是一个样本点逐步增加到学习器的过程,前一个样本点的后验会被下一次估计当作先验。我们当然可以说,贝叶斯学习在逐步的更新先验,但要注意,先验的更新实际上是通过更新极大似然估计参数和样本点来进行迭代的,而非改变初始先验的形式。
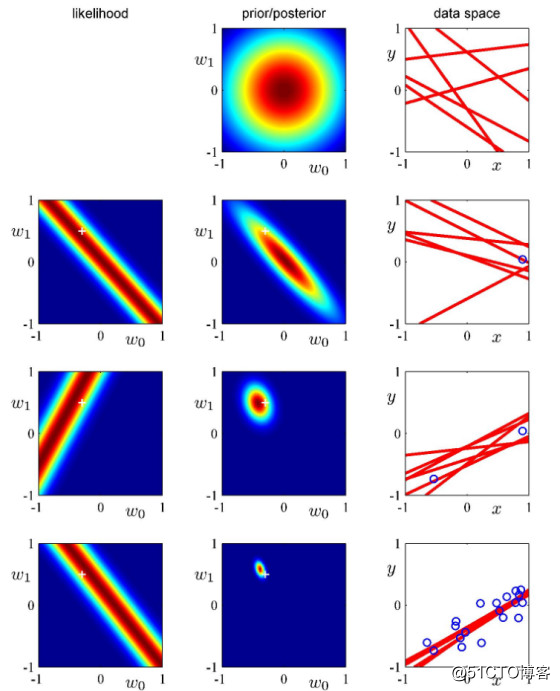
如图,从上到下,我们依次增加样本点。中间的列是我们的每次迭代的后验概率,并且将上一轮的后验作为本次的先验,逐渐更新的先验contour越来越小,表明参数的可选区间越来越小,样本对模型的约束越来越好,最后一列是我们的样本空间,可以看出随着样本点的增加,直线变得越来越近,也说明参数的可选空间越来越小。
我们在极大后验估计中提到了岭回归实际上是加了均值为零的高斯先验。在这里,我们同样可以令先验的均值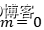 ,然后利用最大后验估计,忽略常数项得到:
,然后利用最大后验估计,忽略常数项得到:
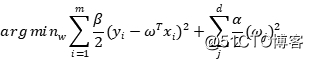
这样的回归方式叫做贝叶斯岭回归(Bayesian Ridge regression)。它与普通岭回归的区别在于,它采用了贝叶斯逐步更新先验的策略,普通的岭回归允许参数图片为零,因为这样就退化到了线性回归,但贝叶斯估计不能这样做,因为高斯分布的标准差不能无穷大。同时,贝叶斯回归会给出参数的置信区间,这是一个参数的可选范围,本质意义上是一个协方差矩阵。

读芯君开扒
课堂TIPS
• MLE和MAP的区别看起来只有先验分布的包括与否,实则是频率学派和贝叶斯学派分歧的一种体现。贝叶斯学派会把参数当作一个分布,虽然看起来MLE和MAP进行的都是点估计,MAP其实对后验概率最大化的方式给出的是参数分布的众数。
• 大多数情况下,计算贝叶斯的后验概率是一件非常困难的事情,我们选取共轭先验使得计算变得非常简单,其他的常见的方法有Laplace approximation,Monte Carlo积分(我们几乎都要用Markov Chain的平稳分布去逼近后验分布),Variational approximation。
• 贝叶斯的线性估计能够充分的利用数据,如果我们有N个样本,那么初始样本将会被计算N次,而最后一个样本只会被计算一次,我们一般会进行多轮计算。但在数据量太大的时候并不适用,因为贝叶斯线性估计的计算代价太大。

留言 点赞 发个朋友圈
我们一起探讨AI落地的最后一公里
作者:唐僧不用海飞丝如需转载,请后台留言,遵守转载规范
推荐文章阅读
【周末AI课堂 | 第十二讲】基于贝叶斯推断的分类模型(代码篇)【周末AI课堂 | 第十一讲】基于贝叶斯推断的分类模型(理论篇)【周末AI课堂 | 第十讲】核技巧(代码篇)【周末AI课堂 | 第九讲】核技巧(理论篇)【周末AI课堂 | 第八讲】非线性降维方法(代码篇)【周末AI课堂 | 第七讲】非线性降维方法(理论篇)【周末AI课堂 | 第六讲】线性降维方法(代码篇)【周末AI课堂 | 第五讲】线性降维方法(理论篇)【周末AI课堂 | 第四讲】如何进行特征选择(代码篇)【周末AI课堂 | 第三讲】如何进行特征选择(理论篇)【周末AI课堂 | 第二讲】过拟合问题(代码篇)【周末AI课堂 | 第一讲】过拟合问题(理论篇)
长按识别二维码可添加关注
读芯君爱你


![[翻译] Backpressure explained — the resisted flow of data through software-爱站程序员基地](https://aiznh.com/wp-content/uploads/2021/05/9-220x150.jpeg)

