 爱站程序员基地
爱站程序员基地Visual Recognition

最简单的视觉识别是根据图片中的物体对图片进行分类,典型的就是判断一张照片是猫还是狗。再进一步不仅要识别图片中物体,还要对它进行定位。
实际工程中,图片一般会同时存在多个物体,面对这种复杂场景需要应用目标检测,同时包含分类和定位。比目标检测更深入的是语义分割,从上图可以看到目标检测只是简单的框出了物体,而语义分析会挖掘出图像中更深层次的信息。
Classification

对分类领域稍有熟悉的朋友可能都知道MNIST(手写数字)数据集,它被称为DeepLearning中的hello world,主流的深度学习框架都会提供该数据集的相应的接口。
上图左边是人眼所看到的图像,在计算机中被转化成了右方这样的矩阵,0表示的是0像素,中间的数字表示颜色由浅到深的过渡。
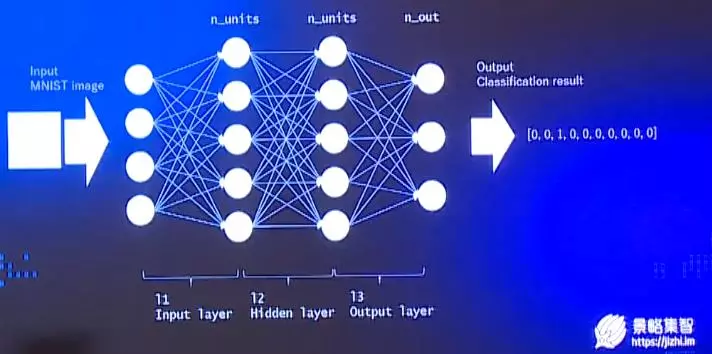
对于上面图片的分类,首先会将图片以像素为单位拆解成特征向量输入到神经网络中,然后输出猜测——长度为10的向量。这种方法是将二维矩阵展开为一维向量,过程中必然会损失一定的信息。所以在深度学习领域更常见的做法是使用卷积神经网络。
CNN
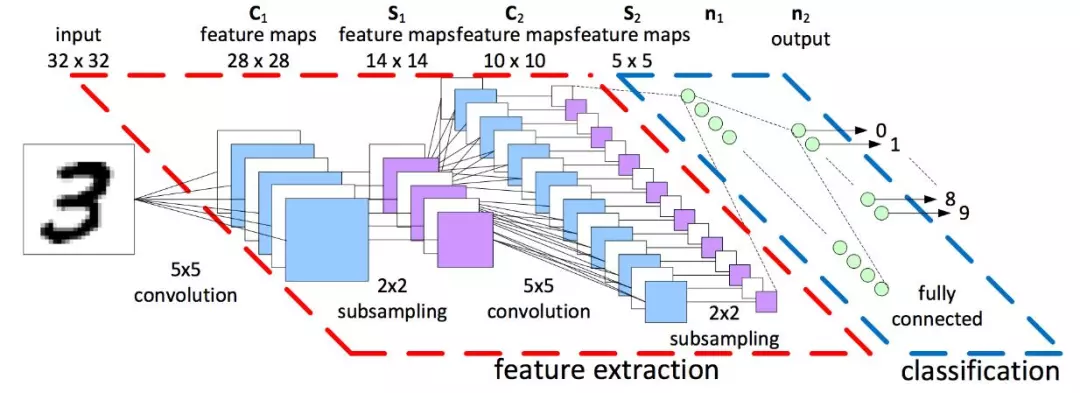
这里输入的同样是数字图片,输出为10维度向量。不过中间部分有些不同,它是由convolution、subsampling、Pooling构成,核心在于convolution(卷积)。
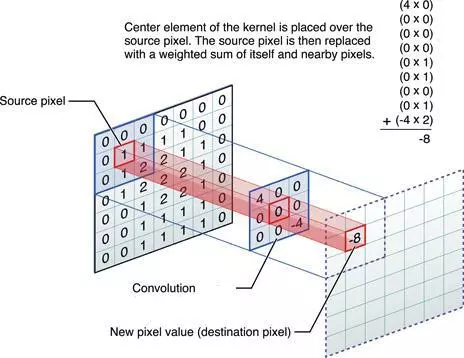
任意的图片都可以被转换为矩阵,图中中间部分的3*3的小矩阵被称为卷积核。我们会将卷积核放到图片矩阵中滑动,重叠部分同样也是一个3*3的矩阵,对他们进行计算后会得到一个结果,计算公式为对应像素位置的值相乘然后求和。
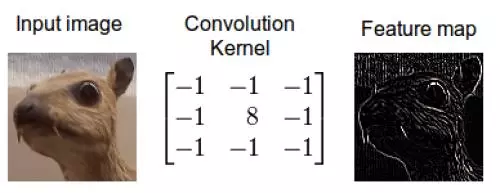
不同的卷积核对应不同的特征,如图中动物图片的卷积核取值,中间是8,周围是-1,这表示一个边缘检测。在经过滑动计算后展现的就是右边的feature map(特征映射),可以看到原图中的边缘区域都被高亮了,整体图片虽然变成了黑白的,但是信息对比更加强烈。
Pooling & ReLu
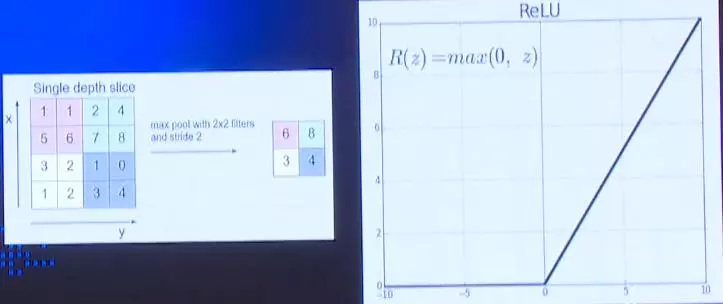
Pooling是在得到特征映射后进一步对信息进行简约化处理,如上图对某个特征映射做2*2的切分,每4个点取一个最大值,减小网络中的计算量只保留最主要的特征信息。ReLu叫做整流线性单元,它是一个激活函数,小于0的时候值一直为0,大于0的时候恢复正常。
VGG16
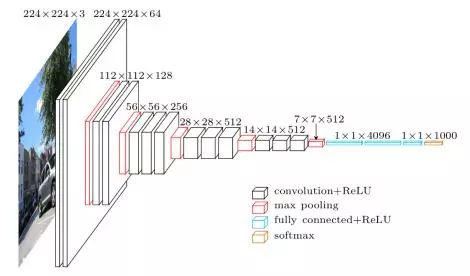
卷积神经网络衍生出过很多不同的版本,VGG16就是其中之一 ,它被很多的目标检测方案用作特征提取。VGG16接收的输入图片尺寸是224*224。图中黑色方块为一个卷积层,后面接着激活函数,红色块是石化层。卷积核得到的特征映射会逐渐缩小,越往后特征映射的点对应的原图区域越大。
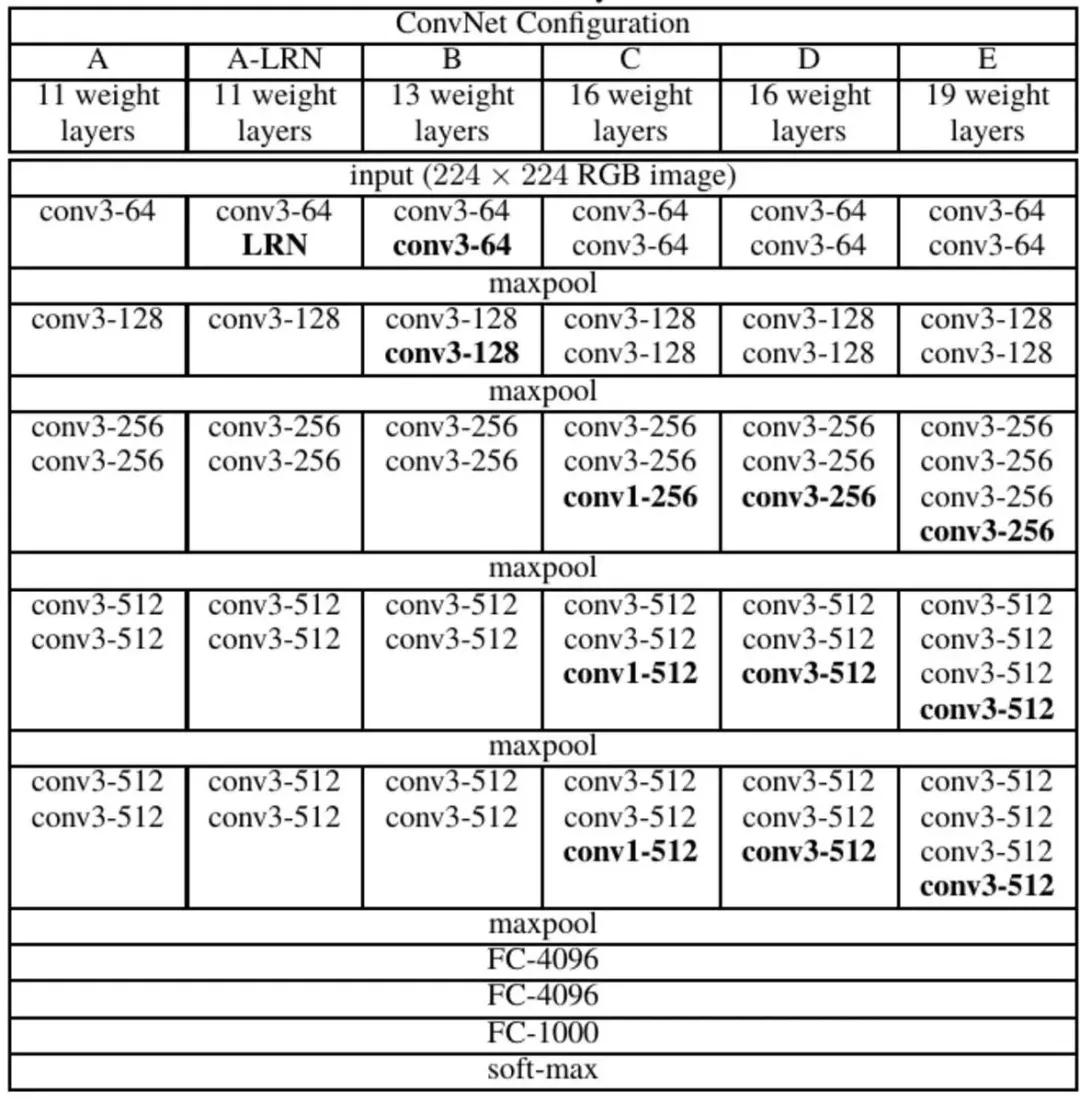
VGG16一共有16个带有权重的层,其中13个卷积层和3个全链接层,我们可以将卷积核、激活函数、石化层视为一个block模块。VGG16的整个网络有138M个参数。
import paddle.v2 as pal
pdl.networks.vgg_16_network(input_image, num_channels,num_classes=1000)
这样庞大的网络,使用上图的方法是最简单的。这是一段python代码,通过导入pdI模块使用VGG16网络,仅用输入3个参数,输入的图片、通道数、分类数。不过仅用这种方式肯定是无法满足大多数情况。
import paddle.v2 as pal
def vgg16(input):
def conv_block(ipc, num_filter, groups, dropouts, num_channels=None):
return pdl.networks.img_conv_group(input=ipt, num_channels=num_channels,
pool_type=pdl.pooling.Max(), pool_size=2, pool_stride=2,
conv_num_filter=[num_filter]*groups, conv_filter_size=3,
conv_act=pdl.activation.Rolu(), conv_with_batchnorm=True,
conv_batchnorm_drop_rate=dropouts)
conv1 = conv_block(input, 64, 2, [0.3, 0], 3)
conv2 = conv_block(input, 128, 2, [0.4, 0])
conv3 = conv_block(input, 256, 3, [0.4, 0])
conv4 = conv_block(input, 512, 3, [0.4, 0.4, 0])
conv5 = conv_block(input, 512, 3, [0.4, 0.4, 0])
fc1 = pdl.layer.fc(input=conv5, size=4096, act=pdl.activation.Linear())
fc2 = pdl.layer.fc(input=fc1, size=4096, act=pdl.activation.Linear())
fc3 = pdl.layer.fc(input=fc2, size=1000, act=pdl.activation.Linear())
这是另一种稍显复杂的写法,下方定义了5个卷积层和3个全链接层。它的好处在于整个模块都是我们自定义的,可以随时进行修改。

前面提到过VGG16网络有138M个参数,如果每个视觉分类的任务都需要重新训练,整个任务规模还是非常大的。所以常用的做法是基于ImageNet数据集,它有1000类,共1400万张图片。一般我们会使用数据集中那些已经被训练好参数来做。
Object Detection
PASCAL VOC
Object Detection目标检测需要用到PASCAL VOC数据集,它只有20个类别,虽然相对ImageNet要少很多,但是每张图片的信息更为丰富。
实现目标检测最简单暴力的方法是使用滑动窗口,如上图让绿色窗口在图片上不断滑动。不过由于无法确定窗口的大小是否匹配要检测的物体,所以要不断的缩放图片来进行匹配,同时线框的形状也要进行调整,这无疑增大了复杂度。
Region Proposal——selective search
Region Proposal会帮我们限制图像搜索的空间。它首先假设图上的每个点为独立集团,然后根据颜色、纹理、尺寸、包含关系等进行合并。

比如这张图,最初有非常多的点,之后随着不断合并形成了几个大的集团,下方的线框也就仅剩几个了,最后再进行分类。这样的话计算性能有了很大的提升。
Region – based CNN
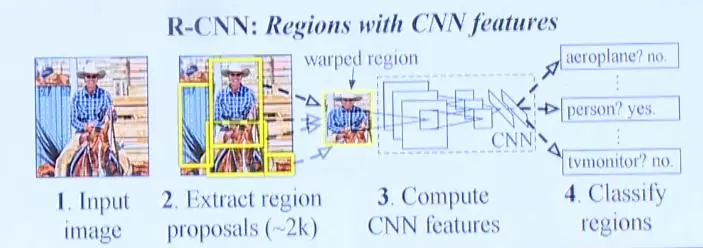
在通过提名方式大致猜测出图片中物体种类后,接下来要做的就是对这些块进行分类。这要用到卷积神经网络,更具体的是Region based CNN。输入图片后提取出region proposals,然后将这些region proposals图片缩放成统一大小的正方形输入到CNN中,最后CNN会给出分类结果。
R-CNN Training
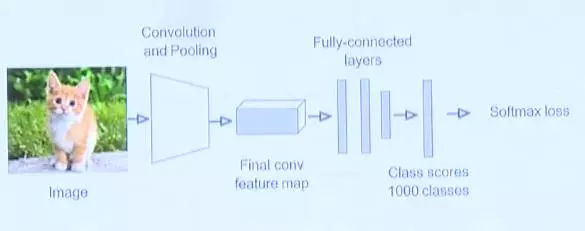
R-CNN训练过程中,首先会在ImageNet上训练卷积部分提取物体特征的能力,在嫁接到PASCAL之前还要对网络进行改造,让它只输入21类,多出的1类为背景。这种对神经网络的改造,用到就是前面展示的相对复杂的代码。
Fast R-CNN
R-CNN针对每张图片可能会提取出2000多个region proposals,而对这些region proposals都需要做一遍卷积操作,计算量无形中增大了2000倍,显然会拖慢运行效率。
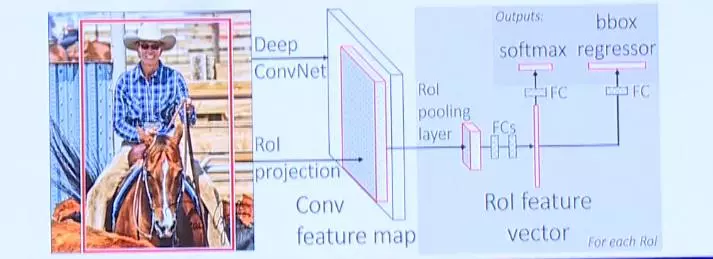
为此现在又提出了Fast R-CNN。我们知道图片经过卷积之后得到的特征映射,虽然信息量降低了,但是保留下了分类相关的信息。因此region proposals就完全可以不在原图上进行,而在特征映射上完成。原先要将图片切成多份,每份单独进行一次卷积提取特征。现在只需要先整体进行一次提取,然后在特征映射上做若干个区域提名。
Faster RCNN
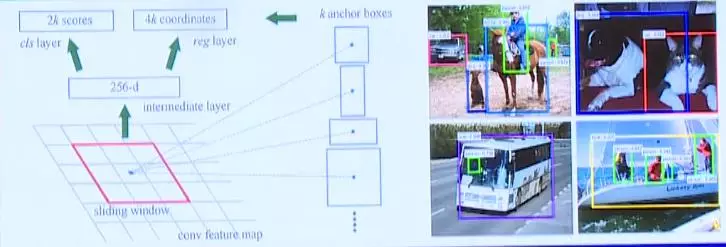
Fast RCNN相对普通的RCNN速度虽有所提升,不过还可以进一步提高。我们可以将生成Proposal的过程也通过神经网络完成,相当于神经网络中又嵌套着一层神经网络,使整个过程全部通过GPU加速,这种方式被称为Faster RCNN。
You Only Look Once(YOLO)
Faster RCNN整个流程分为两个分支,一部分是区域提名,另一部分是特征提取以及位置分类的计算,一次任务要走两步。因此虽然在静态图片识别上Faster RCNN能很好的完成任务,但是还不满足在视频领域实时图像的识别。
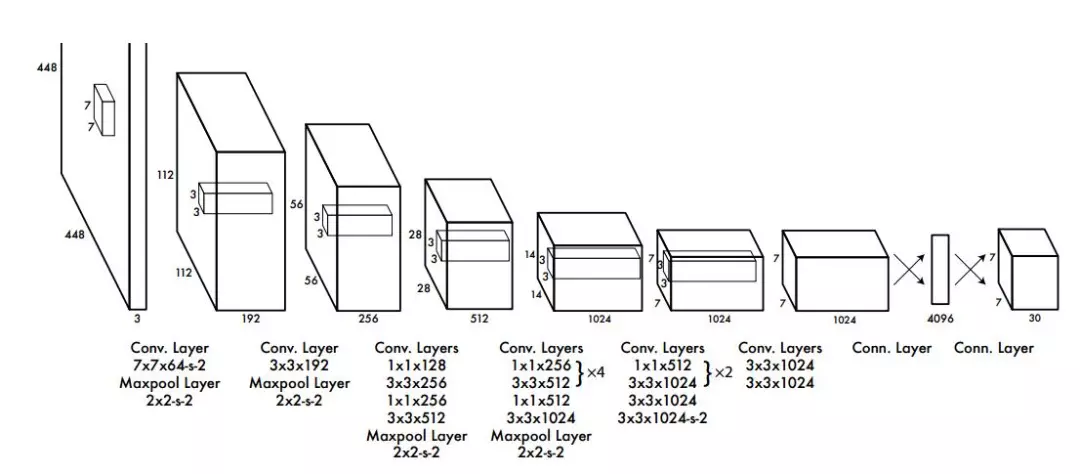

所以又出现了一种新的方法——You Only Look Once。它先对图片做固定数量切分,在此基础上进行各种猜测,然后对这些猜测框进行分类以及四个角的回归,使回归和分类就融合到同一个神经网络中,实现端到端的训练。
Single Shot Multi-box Detector(SSD)
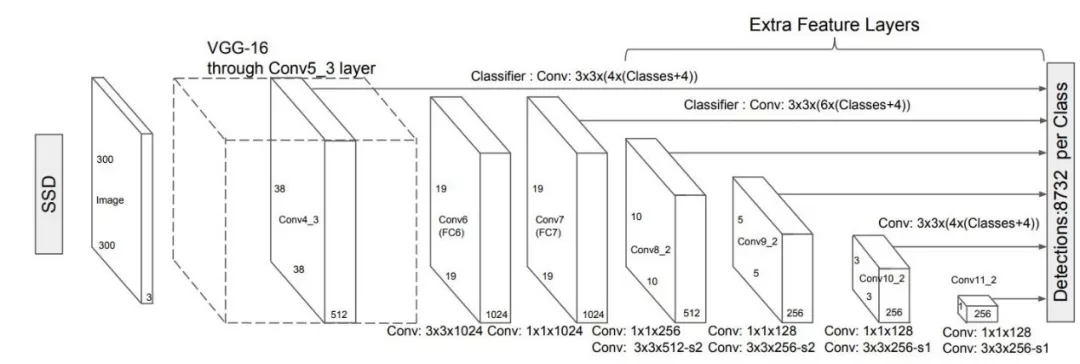
这类将区域提名以及位置和分类合并到一起的方法被称为single shot,上图是Single Shot的另一种方式multi-box detector的结构图。multi-box detector也用到了VGG16,不过仅有前三个conv_block,剔除了全链接层,原先的FC6、FC7又添加了新的卷积。可以看到其中有若干个卷积块连接到了最后的detections,也就是在不同尺度的特征映射上都进行一次物体猜测,这样精度会稍有提高,对于尺度变化较大的物体也能起到较好的效果。
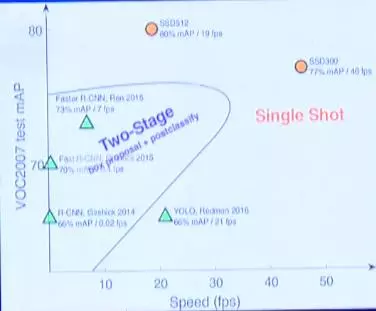
前面提到的这些方法其本质都是在效率和功率上寻找折中,上图是对一些经典方法的总结,横轴是速度,纵轴是MVP。可以看到single shot类的方法明显要更快一些,不过它的实时性是基于牺牲一定的精度。

![[翻译] Backpressure explained — the resisted flow of data through software-爱站程序员基地](https://aiznh.com/wp-content/uploads/2021/05/5-220x150.jpeg)

