 爱站程序员基地
爱站程序员基地Sputnik:Airbnb基于Spark构建的数据开发框架
过往记忆大数据 过往记忆大数据
本文来自 Airbnb 的工程师 Egor Pakhomov 在 Spark Summit North America 2020 的 《Sputnik: Airbnb’s Apache Spark Framework for Data Engineering》议题的分享。相关 PPT 可以到 你要的 Spark AI Summit 2020 PPT 我已经给你整理好了 里面获取。
一个典型的 Spark 作业包括读取外部的数据然后使用 Spark 去处理相关逻辑,处理完之后再写到外部存储中去,比如 Hive 表、对象存储中。
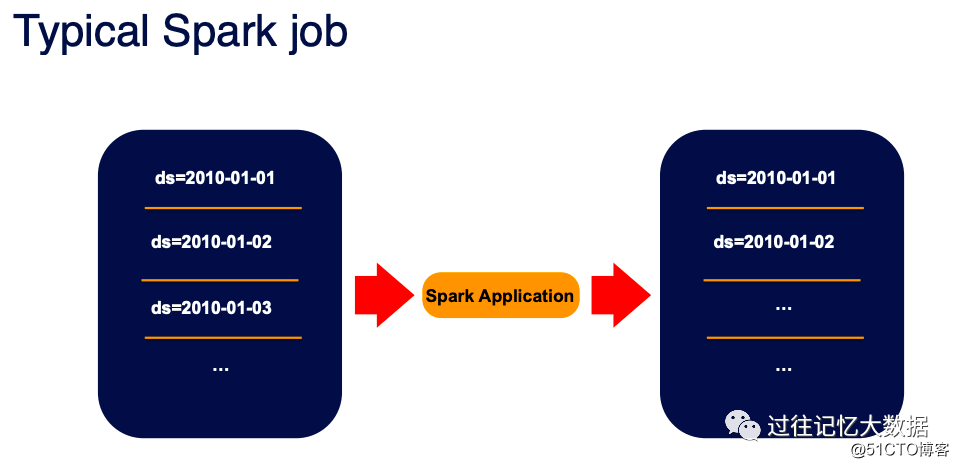
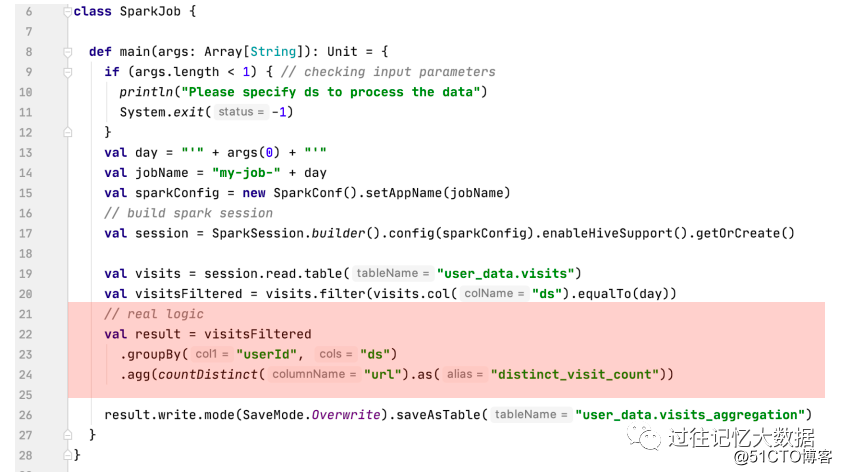
如果使用代表表示的话,主要框架如上面所示。可以看到,这个程序里面有大部分的逻辑在处理参数的解析、SparkSession 的创建、表的输入数据处理以及结果的保存;只有红色的部分才是真正的业务部分。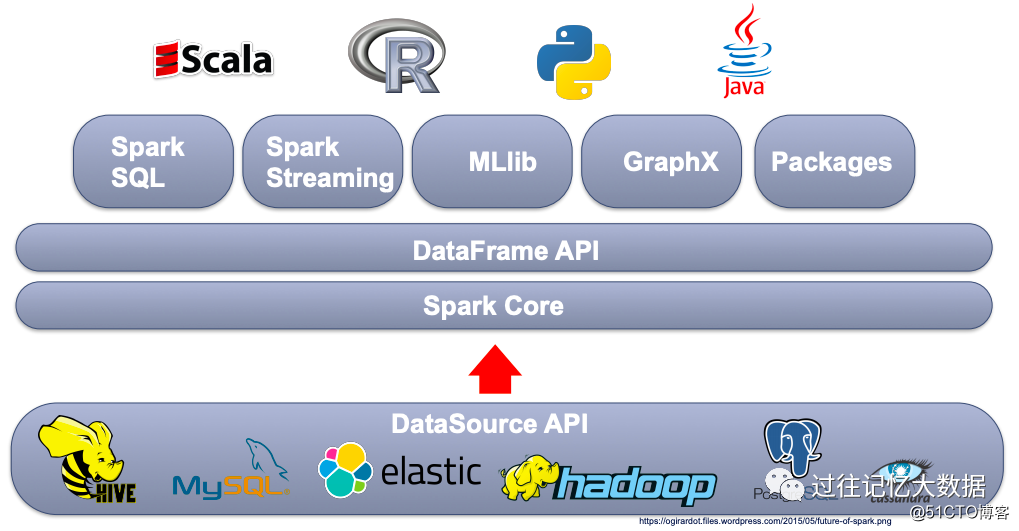
另一方面,Spark 是一个很不错的通用计算逻辑,使用 DataSource API 可以读取多种数据源里面的数据,然后 Spark 给我们提供了多种编程模式,比如 Spark Core、DataFrame API、Spark SQL、Spark Streamig等,同时提供了 Scala、R、Python 以及 Java 来实现各种业务逻辑。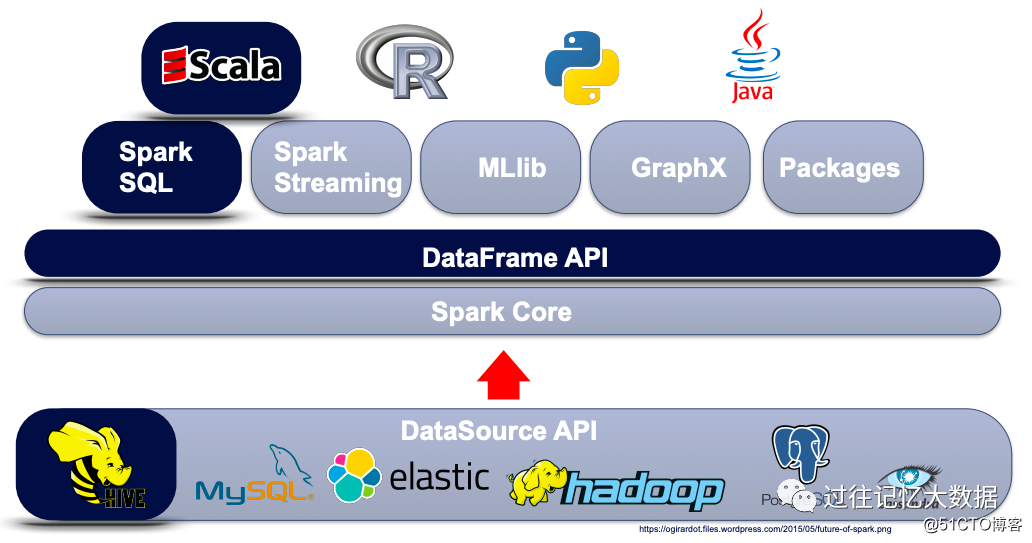
但是在 Airbnb,99%的作业是使用 Scala 编写的,主要使用 Spark SQL 和 DataFrame API 进行,而且只读写 Hive 里面的数据。所以在 Airbnb,Spark 提供如此多的功能,反而给工程师带来了麻烦。

对于 Airbnb 的数据开发工程来说,其实他们的焦点应该是编写一个类似于 transform 的函数,在里面处理各种业务逻辑。这就是我们称为的 Job Logic。
Job Logic 和 Run Logic 的区别如下:
Job Logic 只需要关注业务逻辑,比如如何计算每个 url 的访问量;作业的输入和输出的表;分区的处理以及结果的校验。
Run Logic 需要处理输入的数据范围;将结果保存到表时需要处理表不存在的情况;在测试模式下运行时需要将表以 “_testing” 结尾,这样可以区分线上表和测试表。
为了帮助数据开发工程师,Airbnb 基于 Apache Spark 开发了名为 Sputnik 的数据工作框架。使用这个框架,所有的 Run Logic 都是 Sputnik 来处理,业务人员只需要关注 Job Logic 的实现。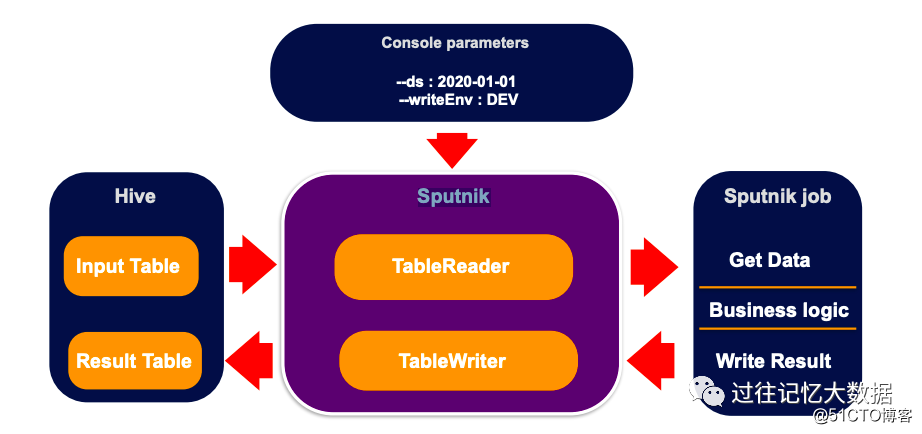
使用 Sputnik 平台时,用户只需要扩展 SputnikJob 类来实现自己的业务逻辑,使用 HiveTableReader 来读取表的数据: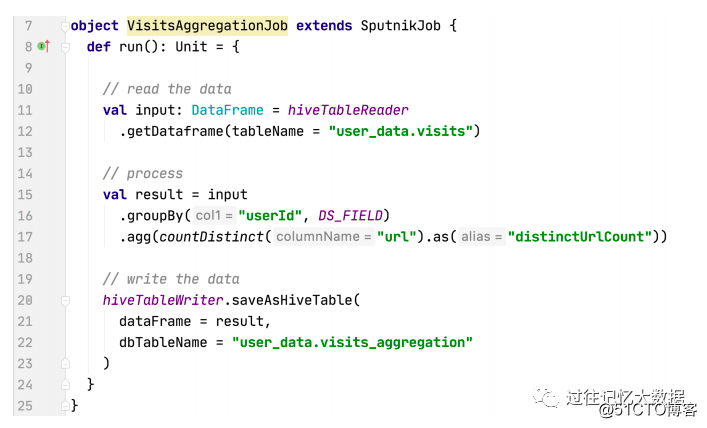
使用 hiveTableWriter 来将结果保存到 Hive 的相关表中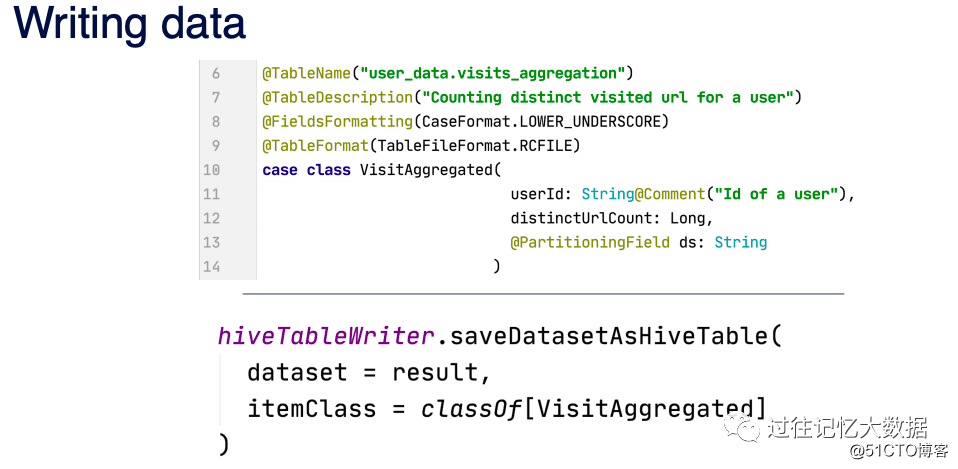

最后使用 SputnikJobRunner 来运行作业。
用户全程不需要处理前面说的各种参数解析,然后处理数据的读取;在将结果写到 Hive 表是也不需要关心表是不是不存在等需求。

Sputnik HiveTableWriter 主要做了以下的事情:
- 在写出的表不存在时,使用 Hive 的CREATE TABLE 来创建表;
- 更新表的元数据;
- 根据输出表来规范化 DataFrame Schema;
- 读输出的表进行 repartition,以便减少写到磁盘的文件个数;
- 在写数据之前进行一些校验;
- 根据不同的运行模式来修改输出表的表名。

Sputnik 提供了将数据转换成 DataFrame 和 DataSet 的接口,用户只需要输出表名以及表的处理时间范围,就可以得到表的 DataFrame 或 DataSet,而不需要处理前面说的各种参数解析等问题。

Sputnik 也支持配置文件,以便用户给作业进行一些配置。业务人员只需要给出相关配置文件,然后使用 Sputnik 获取相关参数的值。
对于输出结果,我们一般需要做一些 Null 值校验或者空的输出校验等,Sputnik 内置提供了一些比较常见的校验类,比如 NullCheck、NotEmptyCheck 等。业务人员只需要在输出表的时候直接配置相关校验类即可。
图片对于日常的作业只需要配置 –ds 2020-01-07 来处理某一天的数据。比如我们通过这个很容易进行 T+1 的数据处理。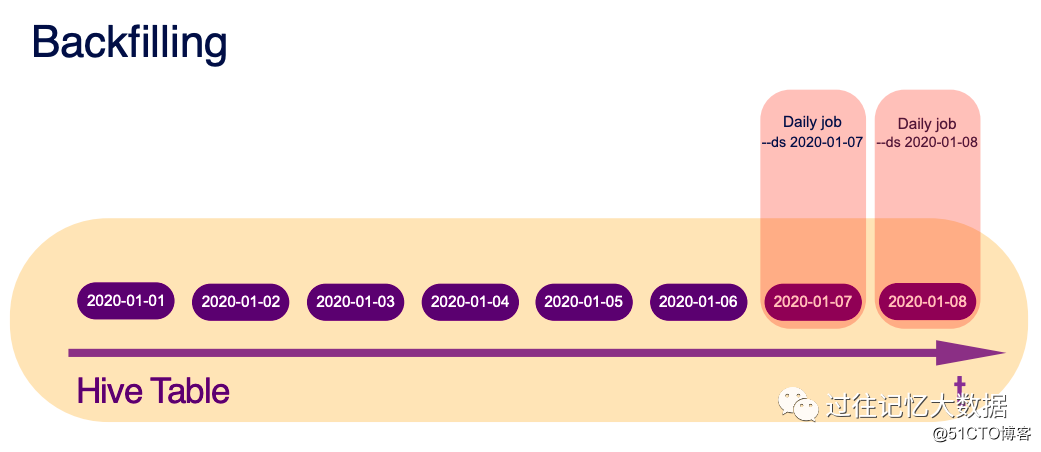
如果由于某种原因需要处理某一个时间范围的数据,可以使用 –startDate 2020-01-01 –endDate 2020-01-06 来实现。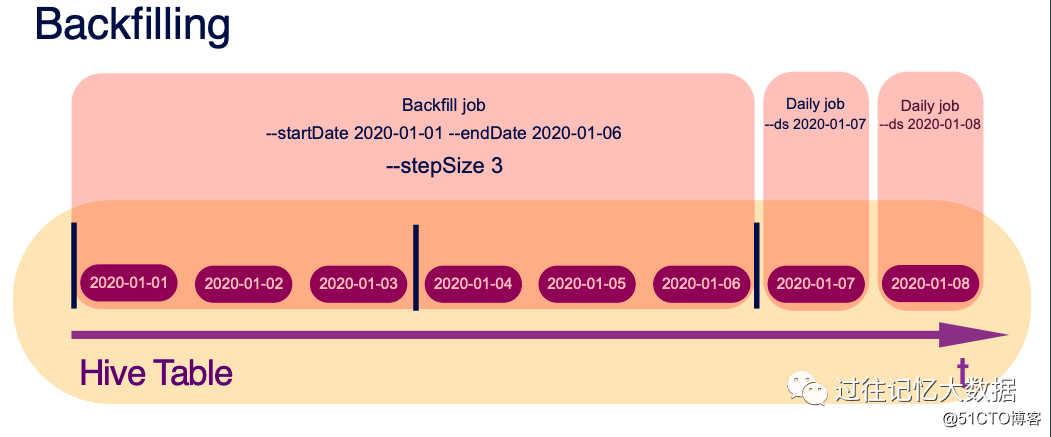
如果需要隔一段时间处理数据,可以使用 –startDate 2020-01-01 –endDate 2020-01-06 –stepSize 3 类实现。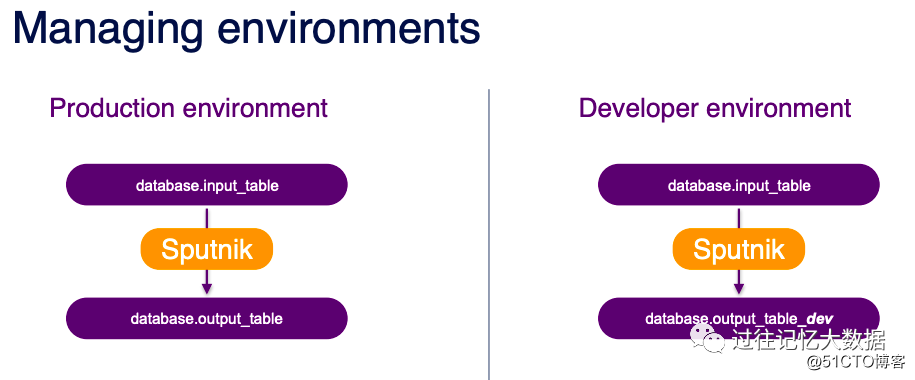
在业务实现之前,我们一般需要在开发环境进行一些测试,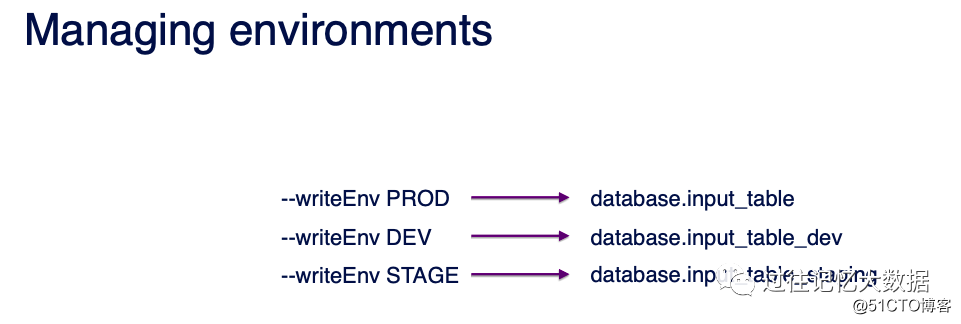
我们只需要使用 –writeEnv 参数来设置运行环境。比如 –writeEnv PROD 代表线上环境;–writeEnv DEV 代表开发环境,输入输出的表结尾自动加上 dev。
其他一些参数包括 dropResultTables、sample、repartition、jobArgument 等。

![[翻译] Backpressure explained — the resisted flow of data through software-爱站程序员基地](https://aiznh.com/wp-content/uploads/2021/05/4-220x150.jpeg)

