爱站程序员基地
爱站程序员基地前言
上一篇文章我们讲述了序列化,这篇就带大家一起来实现以下序列化
Serializer
我们使用序列化类
Serializer
,我们来看下源码结构,这里推荐使用
pycharm
左边导航栏的
Structure
,可以清晰的看到一个文件的结构,如下图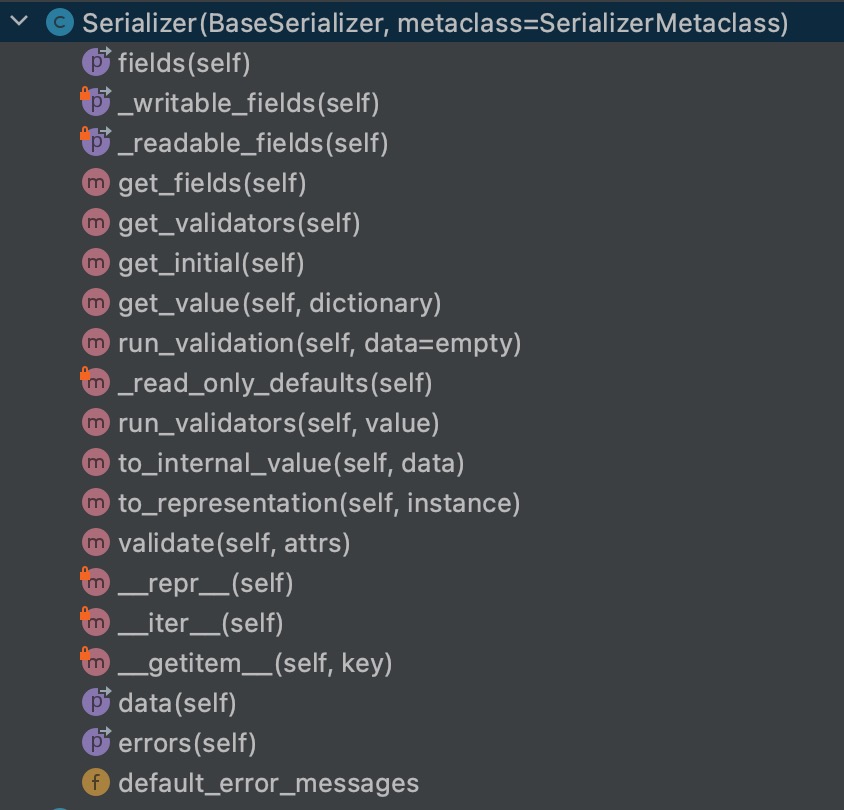
我们会发现
Serializer
继承自
BaseSerializer
和
SerializerMetaclass
,但是
Serializer
类中又没有
create
方法和
update
方法,所以我们使用的时候
必须
自己手动定义这2个方法
准备工作
1.新建一个项目
drf_demo
,在项目中新建一个app
drf_app
,在app中新建一个文件
urls.py
,项目结构如下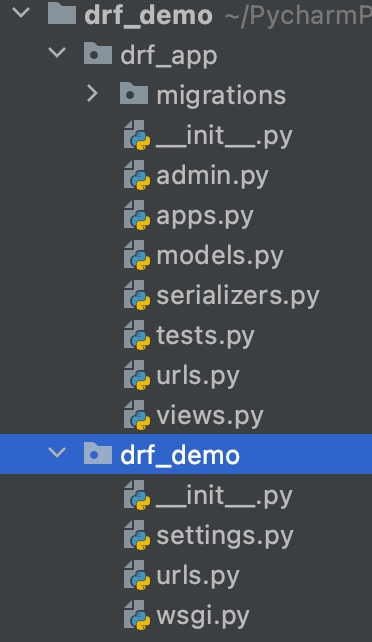
2.在
models.py
文件中写入如下代码
class Student(models.Model):SEX_CHOICES = ((1,\'男\'),(2, \'女\'))name = models.CharField(max_length=20, verbose_name=\'姓名\')age = models.IntegerField(null=True, blank=True, verbose_name=\'年龄\')sex = models.IntegerField(choices=SEX_CHOICES, default=1, verbose_name=\'性别\')class Meta:db_table = \"student\"
3.在
drf_demo.urls.py
和
drf_app.urls.py
中分别写入如下代码
# drf_demo.urls.pyurlpatterns = [path(\'drf/\', include(\'drf_app.urls\')),]# drf_app.urls.pyapp_name = \"drf_app\"urlpatterns = [path(\'student/\', views.student),]
4.在
settings.py
文件的
MIDDLEWARE
中注释掉
django.middleware.csrf.CsrfViewMiddleware
,并在
INSTALLED_APPS
中加入2个app
\'rest_framework\',\'drf_app\'
5.在命令行输入以下命令,将orm对象映射到数据库
python manage makemigrationspython manage migrate
6.写序列化类一般我们都在app项目中新建
serializers.py
文件,接下来可以正式编写序列化类了
序列化类编写
# Serializer的构造函数的参数:# 1. instance:需要传递一个orm对象,或者是一个queryset对象,用来将orm转成json# 2. data:把需要验证的数据传递给data,用来验证这些数据是不是符合要求# 3. many:如果instance是一个queryset对象,那么就需要设置为True,否则为Falseclass StudentSerializer(serializers.Serializer):# 序列化提供给前台的字段个数由后台决定,可以少提供# 但是提供的数据库对应的字段,名字一定要与数据库字段相同id = serializers.IntegerField(read_only=True)name = serializers.CharField(required=True, max_length=200)sex = serializers.IntegerField(required=True)age = serializers.IntegerField(required=True)def create(self, validated_data):\"\"\"根据提供的验证过的数据创建并返回一个新的`Student`实例\"\"\"return Student.objects.create(**validated_data)def update(self, instance, validated_data):\"\"\"根据提供的验证过的数据更新和返回一个已经存在的`Student`实例。\"\"\"instance.name = validated_data.get(\'name\', instance.name)instance.age = validated_data.get(\'name\', instance.age)instance.sex = validated_data.get(\'name\', instance.sex)instance.save()return instance# 局部钩子 validate_要校验的字段名(self, 当前要校验字段的值)def validate_name(self, value):if \'j\' in value.lowead8r():raise exceptions.ValidationError(\"名字非法\")return valuedef validate_sex(self, value):if not isinstance(value, int):raise exceptions.ValidationError(\"只能输入int类型\")if value != 1 and value != 2 :raise exceptions.ValidationError(\"只能输入男和女\")return value# 全局钩子 validate(self, 系统与局部钩子校验通过的所有数据)def validate(self, attrs):age = attrs.get(\'age\')sex = attrs.get(\'sex\')if age < 22 and sex == 1:raise exceptions.ValidationError({\"age&sex\": \"男的必须22周岁以上才能结婚\"})return attrs
我们上面代码首先定义了序列化的字段,字段中的参数都继承自
Field
类,参数如下
def __init__(self, read_only=False, write_only=False,required=None, default=empty, initial=empty, source=None,label=None, help_text=None, style=None,error_messages=None, validators=None, allow_null=False):
- read_only:当为
True
时表示这个字段只能读,只有在返回数据的时候会使用。
- write_only:当为
True
时表示这个字段只能写,只有在新增数据或者更新数据的时候会用到。比如我们的账号密码,只允许用户提交,后端是不返回密码给前台的
- required:当为
True
时表示这个字段必填,不填状态码会返回400
- default:默认值,没什么好说的
- allow_null:当为
True
时,允许该字段的值为空
之后我们又定义了局部钩子,校验特殊的字段,比如需求规定,用户的性别只能输入男和女,此时你就可以定义一个钩子,当然
drf
自动帮我们做了一些校验,比如需要的字段是
int
类型,你输入
string
类型,会自动触发系统的
error
,不需要我们额外定义,后面我们会进行测试
接下来我们又定义了一个全局的钩子,意思就是针对整个数据进行校验,最适合的场景比如密码重复输入,一般我们注册的时候,需要输入2次密码,第二次用来确认,这个场景就适合用全局钩子
编写完
serializers
后,我们最后一步,编写视图函数,如下:
def student(request):# 获取所有的学生if request.method == \"GET\":# 创建一个queryset对象stu = Student.objects.all()# 将对象序列化为dictstu_data = StudentSerializer(instance=stu, many=True).data103creturn JsonResponse(status=200, data=stu_data, safe=False)elif request.method == \"POST\":data = JSONParser().parse(request)serializer = StudentSerializer(data=data)# 校验字段是否符合规范if serializer.is_valid():# 符合则保存到数据库serializer.save()return JsonResponse(data=serializer.data, status=200)return JsonResponse(serializer.errors, status=400)
测试
测试分为
GET
请求和
POST
请求
GET请求
我们打开接口测试工具
postman
或者
apifox
,这里以
apifox
为例,输入
127.0.0.1:8000/drf/student/
,得到了以下结果
[{\"id\": 1,\"name\": \"jkc\",\"sex\": 1,\"age\": 18},{\"id\": 2,\"name\": \"mary\",\"sex\": 2,\"age\": 20}]
说明序列化成功,成功地将数据库的数据通过
json
的格式返回给了前台
POST请求
同样打开接口工具,输入
127.0.0.1:8000/drf/student/
,在
body
中选择
json
格式,输入如下数据
{\"name\": \"aaaa\",\"sex\": 2,\"age\": 18}
运行结果如下:
{\"id\": 13,\"name\": \"aaaa\",\"sex\": 2,\"age\": 18}
说明我们反序列化也成功了,小伙伴们自己实践时可以查看数据库,会多了一条这样的数据
接下来我们是否能触发钩子函数
测试validate_name钩子
输入测试数据
{\"name\": \"jjj\",\"sex\": 2,\"age\": 18}
返回结果如下:
{\"name\": [\"名字非法\"]}
测试validate_sex钩子
输入测试数据
{\"name\": \"kkk\",\"sex\": 3,\"age\": 18}
返回结果如下:
{\"sex\": [\"只能输入男和女\"]}
测试默认的输入类型错误
输入测试数据
{\"name\": \"kkk\",\"sex\": \"???\",\"age\": 18}
返回结果如下:
{\"sex\": [\"请填写合法的整数值。\"]}
测试默认的必填项不填
输入测试数据
{\"name\": \"kkk\"}
返回结果如下:
{\"sex\": [\"该字段是必填项。\"],\"age\": [\"该字段是必填项。\"]}
测试全局钩子
输入测试数据
{\"name\": \"kkk\",\"sex\": 1,\"age\": 18}
返回结果如下:
{\"age&sex\": [\"男的必须22周岁以上才能结婚\"]}
总结
- 设置必填与选填序列化字段,设置校验规则
- 为需要额外校验的字段提供局部钩子函数,如果该字段不入库,且不参与全局钩子校验,可以将值取出校验
- 为有联合关系的字段们提供全局钩子函数,如果某些字段不入库,可以将值取出校验
- 重写
create
方法,完成校验通过的数据入库工作,得到新增的对象