爱站程序员基地
爱站程序员基地Shell有两种执行命令的方式:
交互式(Interactive):解释执行用户的命令,用户输入一条命令,Shell就解释执行一条。
批处理(Batch):用户事先写一个Shell脚本(Script),其中有很多条命令,让Shell一次把这些命令执行完,而不必一条一条地敲命令。
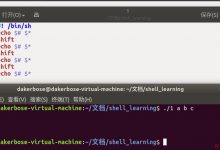
文本编辑器,新建一个文件,扩展名为sh(sh代表shell),扩展名并不影响脚本执行
“#!” 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行
#!/bin/bash
echo “Hello World !”
运行Shell脚本有两种方法
chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本
作为解释器参数(可以不给权限就执行)
这种运行方式是,直接运行解释器,其参数就是shell脚本的文件名
/bin/sh test.sh
bash test.sh
定义变量时,变量名不加美元符号($)
name=“sb”
使用变量 加花括号是为了帮助解释器识别变量的边界
KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 6: name &̲nbsp; 或者 {name}
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变
readonly name
删除变量
unset name
运行shell时,会同时存在三种变量:
- 局部变量
局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 环境变量
所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- shell变量
shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
特殊变量列表
变量 含义
$0 当前脚本的文件名
$n 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是$1,第二个参数是$2。
$# 传递给脚本或函数的参数个数。
$* 传递给脚本或函数的所有参数。
$@ 传递给脚本或函数的所有参数。被双引号(\” “)包含时,与 $* 稍有不同,下面将会讲到。
$? 上个命令的退出状态,或函数的返回值。
$$ 当前Shell进程ID。对于 Shell 脚本,就是这些脚本所在的进程ID。
echo “File Name: $0”
echo “First Parameter : $1”
echo “First Parameter : $2”
echo “Quoted Values: $@”
echo “Quoted Values: $\”
echo “Total Number of Parameters : $#”
$./test.sh Zara Ali
File Name : ./test.sh
First Parameter : Zara
Second Parameter : Ali
Quoted Values: Zara Ali
Quoted Values: Zara Ali
Total Number of Parameters : 2
$ 和 @的区别<br>当它们被双引号(\”\”)包含时\”@ 的区别<br>当它们被双引号(\” \”)包含时\”@的区别<br>当它们被双引号(\”\”)包含时\”\” 会将所有的参数作为一个整体,以\”$1 $2 … n\”的形式输出所有参数;\”n\”的形式输出所有参数;\”n\”的形式输出所有参数;\”@\” 会将各个参数分开,以\”$1\” “2\”…\”2\” … \”2\”…\”n” 的形式输出所有参数
#!/bin/bash
echo \”$=” $
echo “”$”=\” “$\”
echo “$@=” $@
echo “”$@\”=\” “$@”
echo \”print each param from $”
for var in KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 14: *<br>do<br>&̲nbsp; ec…var\”
done
echo “print each param from $@”
for var in KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 14: @<br>do<br>&̲nbsp; ec…var\”
done
echo “print each param from “$\”\”
for var in “KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 15: *\”<br>do<br>&̲nbsp; ec…var”
done
echo “print each param from “$@””
for var in “KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 15: @\”<br>do<br>&̲nbsp; ec…var”
done
执行 ./test.sh “a” “b” “c” “d”,看到下面的结果:
KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 4: *= &̲nbsp;a b c d<br…“= a b c d
KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 4: @= &̲nbsp;a b c d<br…@”= a b c d
print each param from $
a
b
c
d
print each param from @<br>a<br>b<br>c<br>d<br>printeachparamfrom\”@<br>a<br>b<br>c<br>d<br>print each param from \”@<br>a<br>b<br>c<br>d<br>printeachparamfrom\”\”
a b c d
print each param from “$@”
a
b
c
d
退出状态
$?可以获取上一个命令的退出状态 echo $?
一般情况下,大部分命令执行成功会返回 0,失败返回 1。
命令别名
alias vi=‘vim’ 写入环境变量 root用户/etc/profile 普通用户 ~/.bashrc
Bash 支持很多运算符,包括算数运算符、关系运算符、布尔运算符、字符串运算符和文件测试运算符
expr 是一款表达式计算工具,使用它能完成表达式的求值操作
val=
expr 2 + 2
echo “Total value : $val”
两点注意:
表达式和运算符之间要有空格
完整的表达式要被
包含,注意这个字符不是常用的单引号,在 Esc 键下边
算术运算符
#!/bin/sh
a=10
b=20
val=
expr $a + $b
echo “a + b : $val”
val=
expr $a - $b
echo “a – b : $val”
val=
expr $a \\* $b
echo “a * b : $val”
val=
expr $b / $a
echo “b / a : $val”
val=
expr $b % $a
echo “b % a : $val”
if [ $a == $b ]
then
echo “a is equal to b”
fi
if [ $a != $b ]
then
echo “a is not equal to b”
fi
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字
a=10
b=20
if [ $a -eq KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a -eq KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 35: …\”<br>else<br>&̲nbsp; ech…a -eq $b: a is not equal to b”
fi
if [ $a -ne KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a -ne KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 38: …\”<br>else<br>&̲nbsp; ech…a -ne $b : a is equal to b”
fi
if [ $a -gt KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a -gt KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 38: …\”<br>else<br>&̲nbsp; ech…a -gt $b: a is not greater than b\”
fi
if [ $a -lt KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a -lt KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 35: …\”<br>else<br>&̲nbsp; ech…a -lt $b: a is not less than b\”
fi
if [ $a -ge KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a -ge KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 20: … is greater or &̲nbsp;equal to b…a -ge $b: a is not greater or equal to b\”
fi
if [ $a -le KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a -le KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 17: …: a is less or &̲nbsp;equal to b…a -le $b: a is not less or equal to b\”
fi
运算符 说明 举例
-eq 检测两个数是否相等,相等返回 true。
[ $a -eq $b ] 返回 true。-ne 检测两个数是否相等,不相等返回 true。
[ $a -ne $b ] 返回 true。-gt 检测左边的数是否大于右边的,如果是,则返回 true。
[ $a -gt $b ] 返回 false。-lt 检测左边的数是否小于右边的,如果是,则返回 true。
[ $a -lt $b ] 返回 true。-ge 检测左边的数是否大等于右边的,如果是,则返回 true。
[ $a -ge $b ] 返回 false。-le 检测左边的数是否小于等于右边的,如果是,则返回 true。
[ $a -le $b ] 返回 true。布尔运算符
#!/bin/sh
a=10
b=20
if [ $a != KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a != KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 39: …\”<br>else<br>&̲nbsp; ech…a != $b: a is equal to b\”
fi
if [ $a -lt 100 -a KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 25: …]<br>then<br>&̲nbsp; ech…a -lt 100 -a KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 39: …\”<br>else<br>&̲nbsp; ech…a -lt 100 -a $b -gt 15 : returns false\”
fi
if [ $a -lt 100 -o KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 26: …]<br>then<br>&̲nbsp; ech…a -lt 100 -o KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 40: …\”<br>else<br>&̲nbsp; ech…a -lt 100 -o $b -gt 100 : returns false\”
fi
if [ $a -lt 5 -o KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 26: …]<br>then<br>&̲nbsp; ech…a -lt 100 -o KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 40: …\”<br>else<br>&̲nbsp; ech…a -lt 100 -o $b -gt 100 : returns false\”
fi
运算符 说明 举例
! 非运算,表达式为 true 则返回 false,否则返回 true。
[ ! false ] 返回 true。-o 或运算,有一个表达式为 true 则返回 true。
[ $a -lt 20 -o $b -gt 100 ] 返回 true。-a 与运算,两个表达式都为 true 才返回 true。
[ $a -lt 20 -a $b -gt 100 ] 返回 false。字符串运算符
#!/bin/sh
a=“abc”
b=“efg”
if [ $a = KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a = KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 35: …\”<br>else<br>&̲nbsp; ech…a = $b: a is not equal to b\”
fi
if [ $a != KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a != KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 39: …\”<br>else<br>&̲nbsp; ech…a != $b: a is equal to b\”
fi
if [ -z $a ]
then
echo “-z $a : string length is zero”
else
echo “-z $a : string length is not zero”
fi
if [ -n $a ]
then
echo “-n $a : string length is not zero”
else
echo “-n $a : string length is zero”
fi
if [ KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 18: …]<br>then<br>&̲nbsp; ech…a : string is not empty\”
else
echo “$a : string is empty”
fi
运算符 说明 举例
= 检测两个字符串是否相等,相等返回 true。
[ $a = $b ] 返回 false。!= 检测两个字符串是否相等,不相等返回 true。
[ $a != $b ] 返回 true。-z 检测字符串长度是否为0,为0返回 true。
[ -z $a ] 返回 false。-n 检测字符串长度是否为0,不为0返回 true。
[ -z $a ] 返回 true。str 检测字符串是否为空,不为空返回 true。
[ $a ] 返回 true。文件测试运算符
#!/bin/sh
file=\”/opt/tools/myshell/test.sh\”
if [ -r $file ]
then
echo “File has read access”
else
echo “File does not have read access”
fi
if [ -w $file ]
then
echo “File has write permission”
else
echo “File does not have write permission”
fi
if [ -x $file ]
then
echo “File has execute permission”
else
echo “File does not have execute permission”
fi
if [ -f $file ]
then
echo “File is an ordinary file”
else
echo “This is sepcial file”
fi
if [ -d $file ]
then
echo “File is a directory”
else
echo “This is not a directory”
fi
if [ -s $file ]
then
echo “File size is zero”
else
echo “File size is not zero”
fi
if [ -e $file ]
then
echo “File exists”
else
echo “File does not exist”
fi
操作符 说明 举例
-b file 检测文件是否是块设备文件,如果是,则返回 true。
[ -b $file ] 返回 false。-c file 检测文件是否是字符设备文件,如果是,则返回 true。
[ -b $file ] 返回 false。-d file 检测文件是否是目录,如果是,则返回 true。
[ -d $file ] 返回 false。-f file 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。
[ -f $file ] 返回 true。-g file 检测文件是否设置了 SGID 位,如果是,则返回 true。
[ -g $file ] 返回 false。-k file 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。
[ -k $file ] 返回 false。-p file 检测文件是否是具名管道,如果是,则返回 true。
[ -p $file ] 返回 false。-u file 检测文件是否设置了 SUID 位,如果是,则返回 true。
[ -u $file ] 返回 false。-r file 检测文件是否可读,如果是,则返回 true。
[ -r $file ] 返回 true。-w file 检测文件是否可写,如果是,则返回 true。
[ -w $file ] 返回 true。-x file 检测文件是否可执行,如果是,则返回 true。
[ -x $file ] 返回 true。-s file 检测文件是否为空(文件大小是否大于0),不为空返回 true。
[ -s $file ] 返回 true。-e file 检测文件(包括目录)是否存在,如果是,则返回 true。
[ -e KaTeX parse error: Expected \’EOF\’, got \’#\’ at position 30: …<br><br><br>以“#̲”开头的行就是注释,会被解释器…your_name\”! \\n\”拼接字符串
your_name=“qinjx”
greeting=“hello, “$your_name” !”
greeting_1=“hello, ${your_name} !”
echo $greeting $greeting_1
获取字符串长度
string=“abcd”
echo ${#string} #输出 4
提取子字符串
string=“alibaba is a great company”
echo KaTeX parse error: Expected \’EOF\’, got \’#\’ at position 14: {string:1:4} #̲输出liba<br>查找子字…string\” is`
定义数组
用括号来表示数组,数组元素用“空格”符号分割开
array_name=(value0 value1 value2 value3)
array_name=(
value0
value1
value2
value3
)
单独定义数组的各个分量:
array_name[0]=value0
读取数组
${array_name[index]}
使用@ 或 * 可以获取数组中的所有元素,例如:
${array_name[*]}
${array_name[@]}
获取数组的长度
取得数组元素的个数
length=${#array_name[@]}
或者
length=${#array_name[*]}
取得数组单个元素的长度
lengthn=KaTeX parse error: Expected \’}\’, got \’#\’ at position 2: {#̲array_name
}<…[23]
num2=$[1+5]
if test $[num1] -eq $[num2]
then
echo ‘The two numbers are equal!’
else
echo ‘The two numbers are not equal!’
fi
case 语句匹配一个值或一个模式,如果匹配成功,执行相匹配的命令
case 值 in
模式1)
command1
command2
command3
;;
模式2)
command1
command2
command3
;;
)
command1
command2
command3
;;
esac
aNum=1
case $aNum in
1) echo ‘You select 1’
;;
2) echo ‘You select 2’
;;
3) echo ‘You select 3’
;;
4) echo ‘You select 4’
;;
) echo ‘You do not select a number between 1 to 4’
;;
esac
for循环一般格式为:
for 变量 in 列表
do
command1
command2
…
commandN
done
for loop in 1 2 3 4 5
do
echo “The value is: $loop”
done
for str in ‘This is a string’
do
echo $str
done
for FILE in $HOME/.bash
do
echo $FILE
done
while循环
while command
do
Statement(s) to be executed if command is true
done
COUNTER=0
while [ $COUNTER -lt 5 ]
do
COUNTER=‘expr $COUNTER+1’
echo $COUNTER
done
break命令允许跳出所有循环(终止执行后面的所有循环)
break
在嵌套循环中,break 命令后面还可以跟一个整数,表示跳出第几层循环
break n
continue它不会跳出所有循环,仅仅跳出当前循环
continue
continue 后面也可以跟一个数字,表示跳出第几层循环
continue n
Shell 函数的定义格式如下:
function_name () {
list of commands
[ return value ]
}
调用函数只需要给出函数名,不需要加括号
Hello () {
echo “Url is http://see.xidian.edu.cn/cpp/shell/”
}
Hello
带有return语句的函数:函数返回值在调用该函数后通过 KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 6: ? 来获得&̲nbsp;<br>funWi…?
echo $ret
删除函数 unset 命令,加上 .f 选项
$unset .f function_name
调用函数时可以向其传递参数
通过 $n 的形式来获取参数的值
funWithParam(){
echo “The value of the first parameter is $1 !”
echo “The value of the second parameter is $2 !”
echo “The value of the tenth parameter is $10 !”
echo “The value of the tenth parameter is ${10} !”
echo “The value of the eleventh parameter is ${11} !”
echo “The amount of the parameters is $# !” # 参数个数
echo \”The string of the parameters is $ !\” # 传递给函数的所有参数
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
注意,10不能获取第十个参数,获取第十个参数需要10 不能获取第十个参数,获取第十个参数需要10不能获取第十个参数,获取第十个参数需要{10}。当n>=10时,需要使用${n}来获取参数。
特殊变量 说明
$# 传递给函数的参数个数。
$ 显示所有传递给函数的参数。
@<span></span>与@ <span></span>与@<span></span>与*相同,但是略有区别,参考前面对比
$? 函数的返回值。
重定向:将输出到屏幕的信息写到到文件里面
标准输出重定向 文件描述符为1
命令>文件 ls>log.log 覆盖写入(文件不存在自动创建)
命令>>文件 ls>>log.log 追加写入
标准错误输出重定向 文件描述符为2
命令 2>文件 lsmm 2>log.log 覆盖写入(文件不存在自动创建)
命令 2>>文件 lsmm 2>>log.log 追加写入
标准输出与标准错误输出重定向
$command >> file 2>&1 $command &>> file
KaTeX parse error: Expected \’EOF\’, got \’&\’ at position 9: command &̲gt; file 2>&…command &> file
输入重定向
command < file
命令 说明
command > file 将输出重定向到 file。
command < file 将输入重定向到 file。
command >> file 将输出以追加的方式重定向到 file。
n > file 将文件描述符为 n 的文件重定向到 file。
n >> file 将文件描述符为 n 的文件以追加的方式重定向到 file。
n >& m 将输出文件 m 和 n 合并。
n <& m 将输入文件 m 和 n 合并。
<< tag 将开始标记 tag 和结束标记 tag 之间的内容作为输入。
Here Document嵌入文档 作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。
command << delimiter
document
delimiter
通过 wc -l 命令计算 document 的行数:
wc -l << EOF
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.
EOF
通过cat将 document保存到hello.sh文件
cat <<‘EOF’ > hello.sh
#!/bin/sh
name=“bitch”
echo “$name”
EOF
/dev/null 文件
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null:
$ command > /dev/null
/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃
Shell将外部脚本的内容合并到当前脚本
Shell 中包含脚本可以使用:
. filename
source filename
subscript.sh
url=“http://see.xidian.edu.cn/cpp/view/2738.html”
main.sh 注意:被包含脚本不需要有执行权限。 chomd +x main.sh
#!/bin/bash
. ./subscript.sh
echo $url
shell 执行多个命令的方法
(1)在每个命令之间用;(分号)隔开
(2)在每个命令之间用&&隔开
&&表示:若前一个命令执行成功,才会执行下一个
(3)在每个命令之间用||隔开
||表示:若前一个命令执行成功,就不会执行下一条了。
shell常见通配符:
字符 含义 实例
- 匹配 0 或多个字符 a*b a与b之间可以有任意长度的任意字符, 也可以一个也没有, 如aabcb, axyzb, a012b, ab。
? 匹配任意一个字符 a?b a与b之间必须也只能有一个字符, 可以是任意字符, 如aab, abb, acb, a0b。
[list] 匹配 list 中的任意单一字符
a[xyz]b a与b之间必须也只能有一个字符, 但只能是 x 或 y 或 z, 如: axb, ayb, azb。[!list] 匹配 除list 中的任意单一字符
a[!0-9]b a与b之间必须也只能有一个字符, 但不能是阿拉伯数字, 如axb, aab, a-b。[c1-c2] 匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z]
a[0-9]b 0与9之间必须也只能有一个字符 如a0b, a1b… a9b。{string1,string2,…} 匹配 sring1 或 string2 (或更多)其一字符串
a{abc,xyz,123}b a与b之间只能是abc或xyz或123这三个字符串之一。 - 代表0个或者多个特殊字符
例子 yum.* 代表的可以使yum.也可以是yum.a、yum.ab、yum.abc 当然小数点后面可以有多个字母
? 代表的是任意一个字符
例子 yum.? 可以是yum.a yum.b yum.c“““`但是要注意小数点后面必须有任意一个字符
[]代表的是中括号中的任意一个
例子[abcdef] 可以是a b c d e f 中的任意一个字母当然也可以是数字
[-]代表的是一个范围
例子 [a-z] 表示的是字母a到z之间的所有字母
[]是反向选择符号从字面意思可以知道也就是非的意思
例子[^abc]表示只要不a b c 这三个字符中的任意一个就选择
特殊符号
注释说明
$ 变量符号
\\ 转义字符 一般用在写很长的通配符上 我们可以把特殊字符或者通配符 转义成一般的字符 $ 输出 $
; 连续命令执行分割符号
{} 中间是命令块
& 把作业放到后台去执行
~ 用户的主文件夹
’ – 单引号,不具有变量置换功能
\” – 双引号,具有变量置换功能,调用变量的值
$() 括号里是系统命令
管道符”|”,就是把前面的命令运行的结果丢给后面的命令 yum list | grep [相关关键词]
vim编辑器
命令行调到文件第n行
vim +n filename
:w 保存编辑的内容
:q! 不想保存修改强制离开
:wq 保存后离开
ZZ 若文件没有更动,则不保存离开,若文件已经被更改过,则保存后离开
磁盘管理
df 查看已挂载磁盘的总容量、使用容量、剩余容量等,可以不加任何参数,默认是按k为单位显示的
-h 使用合适的单位显示,例如G
-k -m 分别为使用K,M为单位显示
-i 使用inodes 显示结果
du 用来查看某个目录所占空间大小 du [-abckmsh] [文件或者目录名]
-a:全部文件与目录大小都列出来
-b:列出的值以bytes为单位输出,默认是以Kbytes
-k:以KB为单位输出
-m:以MB为单位输出
-s:只列出总和
-h:系统自动调节单位 du –sh filename 这样的形式
【磁盘的分区和格式化】
列出系统中所有的磁盘设备以及分区表,加上设备名会列出该设备的分区表
fdisk [-l ] [设备名称]
对磁盘进行分区操作
fdisk
刚进入该模式下,会有一个提示Command (m for help): m则会打印出帮助列表,常用的有p, n,d, w, q.
m 打印出帮助列表
P:打印当前磁盘的分区情况。
n:重新建立一个新的分区。
w:保存操作。
q:退出。
d:删除一个分区
用n创建一个新的分区,
会提示要建立e (extended 扩展分区)或者p (primary partition主分区)
输入First cylinder 你或者直接回车或者输入一个数字(开始位置)
此时会提示要分多大 可以输入+sizeK或者+sizeM(终止位置)
在linux中最多只能创建4个主分区,那如果你想多创建几个分区如何做?很容易,在创建完第三个分区后,创建第四个分区时选择扩展分区
建立一个扩展分区
直接回车,即把所有空间都分给了这个扩展分区 扩展分区并不能往里写数据 需要继续在这个空壳中继续创建分区
当建立完扩展分区,然后按n创建新分区时你会发现不再提示是要建立p还是e了因为我们已经不能再创建p了
hdb5 其实只是 hdb4 中的一个子分区
然后按w保存,该模式自动退出,如果你不想保存分区信息直接按q即可退出。
安装RPM包或者安装源码包
1)安装一个rpm包
rpm -ivh xxxx.rpm
-i :安装的意思
-v :可视化
-h :显示安装进度
2)升级一个rpm包
rpm -Uvh filename -U :即升级的意思
3)卸载一个rpm包
rpm -e filename
4)查询一个包是否安装
rpm -q rpm包名
5)得到一个rpm包的相关信息
rpm -qi 包名
6)列出一个rpm包安装的文件
rpm -ql 包名
【yum工具】
1) 列出所有可用的rpm包 “yum list “
2)搜索一个rpm包 “yum search [相关关键词]”
利用grep来过滤 yum list | grep [相关关键词]
3)安装一个rpm包 “yum install [-y] [rpm包名]”
如果不加-y选项,则会以与用户交互的方式安装 输入y则安装,输入n则不安装
4)卸载一个rpm包 “yum remove [-y] [rpm包名]”
4)升级一个rpm包 “yum update [-y] [rpm包]”
【安装源码包】
- 下载一个源码包
- 解压源码包
- 配置相关的选项,并生成Makefile
./config –help 查看可用的选项
一般常用的有”–prefix=PREFIX “ 这个选项的意思是定义软件包安装到哪里 ./config –prefix=/usr/local/apache2
回车后,开始执行check操作。等check结束后生成了Makefile文件 ls -l Makefile - 进行编译 通过这个命令”echo $?”来判定上一步操作是否成功完成 0成功
make - 安装
make install 安装步骤,生成相关的软件存放目录和配置文件的过程split :切割文档,常用选项:
-b :依据大小来分割文档,单位为byte
【grep / egrep】
grep [-cinvABC] ‘word’ filename
-c :打印符合要求的行数
-i :忽略大小写
-n :在输出符合要求的行的同时连同行号一起输出
-v :打印不符合要求的行
-A :后跟一个数字(有无空格都可以),例如 –A2则表示打印符合要求的行以及下面两行
-B :后跟一个数字,例如 –B2 则表示打印符合要求的行以及上面两行
-C :后跟一个数字,例如 –C2 则表示打印符合要求的行以及上下各两行
【sed 工具的使用】sed和awk都是流式编辑器,是针对文档的行来操作的
把替换的文本输出到屏幕上
- 打印某行 sed -n \’n’p filename 单引号内的n是一个数字,表示第几行sed -n \’2’p test.txt sed -n \’2,4’p test.txt
- 打印多行 打印整个文档用 sed -n \’1,$\’p test.txt
- 打印包含某个字符串的行1 sed -n \’/root/\’p test.txt
4,-e 可以实现多个行为 sed -e \’2’p -e \’/root/\’p -n test.txt
- 把/etc/passwd 复制到/root/test.txt,用sed打印所有行;
- /bin/cp /etc/passwd /root/test.txt ; sed -n \’1,$\’p test.txt
- 打印test.txt的3到10行;
- sed -n \’3,10’p test.txt
- 打印test.txt 中包含’root’的行;
- sed -n \’/root/\’p test.txt
- 删除test.txt 的15行以及以后所有行;
- sed \’15,$\’d test.txt
- 删除test.txt中包含’bash’的行;
- sed \’/bash/\’d test.txt
- 替换test.txt 中’root’为’toor’;
- sed ‘s/root/toor/g’ test.txt
- 替换test.txt中’/sbin/nologin’为’/bin/login’
- sed ‘s#sbin/nologin#bin/login#g’ test.txt
- 删除test.txt中5到10行中所有的数字;
- sed ‘5,10s/[0-9]//g’ test.txt
- 删除test.txt 中所有特殊字符(除了数字以及大小写字母);
- sed ‘s/[^0-9a-zA-Z]//g’ test.txt
- 把test.txt中第一个单词和最后一个单词调换位置;
- sed ‘s/[a−zA−Z][a−zA−Z]∗[a−zA−Z][a−zA−Z]∗#\\1\\3\\2#’ test.txt
- 在test.txt 20行到末行最前面加’aaa:’;
- sed ‘20,s/.∗s/^.*s/.∗/aaa:&/’ test.txt
【awk工具的使用】
- 用awk 打印整个test.txt (以下操作都是用awk工具实现,针对test.txt);Print为打印的动作,用来打印出某个字段。
$1为第一个字段,$2为第二个字段,依次类推,有一个特殊的那就是$0,它表示整行
- awk ‘{print $0}’ test.txt
- 查找所有包含’bash’的行;
- awk ‘/bash/’ test.txt
- 用’:’作为分隔符,查找第三段等于0的行;
- awk -F’:’ ‘$3==“0”’ test.txt
- 用’:’作为分隔符,查找第一段为’root’的行,并把该段的’root’换成’toor’(可以连同sed一起使用);
- awk -F’:’ ‘$1==“root”’ test.txt |sed ‘s/root/toor/’
- 用’:’作为分隔符,打印最后一段;NF :用分隔符分隔后一共有多少段;
- awk -F’:’ ‘{print $NF}’ test.txt
- 打印行数大于20的所有行;NR :行数
- awk -F’:’ ‘NR>20’ test.txt
- 用’:’作为分隔符,打印所有第三段小于第四段的行;
- awk -F’:’ ‘$3<$4’ test.txt
- 用’:’作为分隔符,打印第一段以及最后一段,并且中间用’@’连接 (例如,第一行应该是这样的形式 “root@/bin/bash”;
- awk -F’:’ ‘{print 1\”@\”1\”@\”1\”@\”NF}’ test.txt
- 用’:’作为分隔符,把整个文档的第四段相加,求和;
- awk -F’:’ ‘{(sum+=$4)}; END {print sum}’ test.txt
date命令%Y表示年,%m表示月,%d表示日期,%H表示小时,%M表示分钟,%S表示秒
date “+%Y%m%d %H:%M:%S”
注意%y和%Y的区别 2015 %y 15 %Y2015
-d 选项也是经常要用到的,它可以打印n天前或者n天后的日期,当然也可以打印n个月/年前或者后的日期。
date -d “+1 day” “+%Y%m%d %H:%M:%S”
date -d “+1 month” “+%Y%m%d %H:%M:%S”
date -d “-1 year” “+%Y%m%d %H:%M:%S”
星期几也是常用的
date +%w
read命令了,它可以从标准输入获得变量的值,后跟变量名。”read x”表示x变量的值需要用户通过键盘输入得到
- 编写shell脚本,计算1-100的和;
- #! /bin/bash
sum=0
for i in
seq 1 100
; do
sum=[[[i+$sum]
done
echo $sum
- 编写shell脚本,要求输入一个数字,然后计算出从1到输入数字的和,要求,如果输入的数字小于1,则重新输入,直到输入正确的数字为止;
- #! /bin/bash
n=0
while [ $n -lt “1” ]; do
read -p “Please input a number, it must greater than “1”:” n
done
sum=0
for i in
seq 1 $n
; do
sum=[[[i+$sum]
done
echo $sum
- 编写shell脚本,把/root/目录下的所有目录(只需要一级)拷贝到/tmp/目录下;
- #! /bin/bash
for f in
ls /root/
; do
if [ -d $f ] ; then
cp -r $f /tmp/
fi
done
- 编写shell脚本,批量建立用户user_00, user_01, … ,user_100并且所有用户同属于users组;
- #! /bin/bash
groupadd users
for i in
seq 0 9
; do
useradd -g users user_0KaTeX parse error: Expected group after \’_\’ at position 67: …d -g users user_̲j
done
- 编写shell脚本,截取文件test.log中包含关键词’abc’的行中的第一列(假设分隔符为”:”),然后把截取的数字排序(假设第一列为数字),然后打印出重复次数超过10次的列;
- #! /bin/bash
awk -F’:’ ‘$0~/abc/ {print $1}’ test.log >/tmp/n.txt
sort -n n.txt |uniq -c |sort -n >/tmp/n2.txt
awk ‘$1>10 {print $2}’ /tmp/n2.txt
- 编写shell脚本,判断输入的IP是否正确(IP的规则是,n1.n2.n3.n4,其中1<n1<255, 0<n2<255, 0<n3<255, 0<n4<255)。
- #! /bin/bash
checkip() {
if echo KaTeX parse error: Can\’t use function \’\\.\’ in math mode at position 25: …-q \’^[0-9]{1,3}\\̲.̲[0-9]{1,3}\\.[0-…’ ; then
a=
echo $1 | awk -F. \'{print $1}\'b=
echo $1 | awk -F. \'{print $2}\'c=
echo $1 | awk -F. \'{print $3}\'d=
echo $1 | awk -F. \'{print $4}\'for n in $a $b $c $d; do
if [ $n -ge 255 ] || [ $n -le 0 ]; then
echo “the number of the IP should less than 255 and greate than 0”
return 2
fi
done
else
echo “The IP you input is something wrong, the format is like 192.168.100.1”
return 1
fi
}
rs=1
while [ $rs -gt 0 ]; do
read -p “Please input the ip:” ip
checkip $ip
rs=
echo $?
done
echo “The IP is right!”
【监控系统的状态】
- w 查看当前系统的负载
- vmstat 监控系统的状态
1)procs 显示进程相关信息
r :表示运行和等待cpu时间片的进程数,如果长期大于服务器cpu的个数,则说明cpu不够用了;
b :表示等待资源的进程数,比如等待I/O, 内存等,这列的值如果长时间大于1,则需要你关注一下了;
2)memory 内存相关信息
swpd :表示切换到交换分区中的内存数量 ;
free :当前空闲的内存数量;
buff :缓冲大小,(即将写入磁盘的);
cache :缓存大小,(从磁盘中读取的);
3)swap 内存交换情况
si :由内存进入交换区的数量;
so :由交换区进入内存的数量;
4)io 磁盘使用情况
bi :从块设备读取数据的量(读磁盘);
bo: 从块设备写入数据的量(写磁盘);
5)system 显示采集间隔内发生的中断次数
in :表示在某一时间间隔中观测到的每秒设备中断数;
cs :表示每秒产生的上下文切换次数;
6)CPU 显示cpu的使用状态
us :显示了用户下所花费 cpu 时间的百分比;
sy :显示系统花费cpu时间百分比;
id :表示cpu处于空闲状态的时间百分比;
wa :表示I/O等待所占用cpu时间百分比;
st :表示被偷走的cpu所占百分比(一般都为0,不用关注)
- top 显示进程所占系统资源
- sar 监控系统状态
1)查看网卡流量 ‘sar -n DEV ‘
2)查看历史负载 ‘sar -q’
- free查看内存使用状况
- ps 查看系统进程
- netstat 查看网络状况
【linux网络相关】
- ifconfig 查看网卡IP
- 查看网卡连接状态
mii-tool link ok等字样说明连接正常,否则会显示’no link’字样
- 更改主机名
hostname
vim /etc/sysconfig/network
【linux系统的任务计划】service crond status查看一下crond服务是否启动
关于cron任务计划功能的操作都是通过crontab这个命令来完成的。其中常用的选项有:
-u :指定某个用户,不加-u选项则为当前用户;
-e :制定计划任务;
-l :列出计划任务;
-r :删除计划任务。
前面部分为时间,后面部分要执行的命令
前面的时间是有讲究的,这个时间共分为5段,用空格隔开
第一段表示分钟(0-59),第二段表示小时(0-23),第三段表示日(1-31),第四段表示月(1-12),第五段表示周(0-7,0或者7都可以表示为周日)。
从左至右依次是:分,时,日,月,周(一定要牢记)!
crontab -e
- 每天凌晨1点20分清除/var/log/slow.log这个文件;
- 20 1 * * * echo “”>/var/log/slow.log
- 每周日凌晨3点执行’/bin/sh /usr/local/sbin/backup.sh’;
- 0 03 * * 0 /bin/sh /usr/local/sbin/backup.sh
- 每月14号4点10分执行’/bin/sh /usr/local/sbin/backup_month.sh’;
- 10 04 14 * * /bin/sh /usr/local/sbin/backup_month.sh
- 每隔8小时执行’ntpdate time.windows.com’;
- 0 */8 * * * ntpdate time.windows.com
- 每天的1点,12点,18点执行’/bin/sh /usr/local/sbin/test.sh’;
- 0 1,12,18 * * /bin/sh /usr/local/sbin/test.sh
- 每天的9点到18点执行’/bin/sh /usr/local/sbin/test2.sh’;
- 0 9-18 * * * /bin/sh /usr/local/sbin/test2.sh
【screen工具介绍】
- 使用nohup 直接加一个’&’虽然丢到后台了,但是当退出该终端时很有可能这个脚本也会退出的,而在前面加上’nohup’就没有问题了
nohup的作用就是不挂断地运行命令
- screen工具的使用 如果你没有screen命令,请用’yum install -y screen’安装
screen
2)screen -ls 查看已经打开的screen会话
3)Ctrl +a 再按d退出该screen会话,只是退出,并没有结束。结束的话输入Ctrl +d 或者输入exit
4)退出后还想再次登录某个screen会话,使用screen -r [screen 编号],这个编号就是上图中那个2082
当你有某个需要长时间运行的命令或者脚本时就打开一个screen会话,然后运行该任务。按ctrl +a 再按d退出会话,不影响终端窗口上的任何操作
【linux下同步时间服务器】
ntpdate 请使用’yum install -y ntpdate’安装
同步时间的命令为:‘ntpdate timeserver’ timeserver为时间服务器的IP或者hostname
常用的timeserver有210.72.145.44, time.windows.com(windows的时间服务器)
如果你想每隔6小时同步一次那么请指定一个计划任务。
00 */6 * * * /usr/sbin/ntpdate 210.72.145.44 >/dev/null
【配置NFS】用于在网络上共享存储
编辑配置文件/etc/exports即可
先创建一个简单的NFS服务器
cat /etc/exports
/home/ 10.0.2.0/24(rw,sync,all_squash,anonuid=501,anongid=501)
第一部分就是本地要共享出去的目录,第二部分为允许访问的主机(可以是一个IP也可以是一个IP段)第三部分就是小括号里面的,为一些权限选项
其中要共享的目录为/home,信任的主机为10.0.2.0/24这个网段,权限为读写,同步,限定所有使用者,并且限定的uid和gid都为501。
启动NFS服务
service portmap start; service nfs start
用shoumount -e 加IP就可以查看NFS的共享情况
【nohup工具介绍】
nohup命令及其输出文件
nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思( no hang up)。
该命令的一般形式为:nohup command & 使用nohup命令提交作业
如果使用nohup命令提交作业,那么在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中,除非另外指定了输出文件:
nohup command > myout.file 2>&1 &
在上面的例子中,输出被重定向到myout.file文件中。
使用 jobs 查看任务。 命令:jobs 命令:jobs -l
使用 fg %n 关闭。让后台运行的进程n到前台来。
-
a-zA-Z ↩︎