爱站程序员基地
爱站程序员基地今天在复习shell的过程中,想起来之前遇到过的一道面试题,如何去除两个文件中的重复数据?
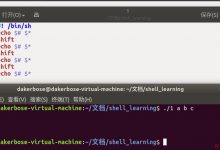
我的第一反应就是用 uniq
cat file1 file2|sort|uniq > resultfile
当然这个回答上来面试官就会继续往下问扩展内容,其实也是日常工作中经常遇到的。
log文件中记录访问信息,里面包含ip地址等信息,想统计每个ip地址访问的次数
(我老板在面试别人的时候也很喜欢面这道题???每次我坐在旁边的时候一直都在想,我能不能写出来)
先思考一下最简单的处理情况,log中的格式是固定的,ip地址出现在第三列。
eg:
cat test.logPOST 200 192.168.1.1POST 200 192.168.10.1POST 200 192.168.1.1POST 200 192.168.20.1
awk -F\" \" \'{print $3} text.log|sort |uniq -c|sort -n -r|head -n 5
取出ip地址所在的第三列,排序才能去重,-c记录出现次数,sort -r 表示从大到小 -n表示按数值排序,head -n 5 取top5
然后如果这个答上来,还有可能的进一步的扩展就是,当前的日志文件并不是有很好的格式化,不一定都在相同列
这时候怎么办?那就是用正则筛选出来ip,然后后面的操作应该是一样。
ip地址的正则表达式
\'[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\'
egrep -o \'[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\' test.log|sort |uniq -c|sort -n -r|head -n 5
sed -nr \'s/.*[^0-9](([0-9]+\\.){3}[0-9]+).*/\\1/p\' test.txt|sort |uniq -c|sort -n -r|head -n 5
我真的不太会正则,这两个匹配时在网上找的我需要稍后拿电脑测试一下