爱站程序员基地
爱站程序员基地钉钉、微博极速扩容黑科技,点击观看阿里云弹性计算年度发布会!>>>
前叙:
今天上班的时候,测试老师发邮件反馈了一个投诉系统的缺陷,说是不同的投诉件在不同的处理阶段,会出现无法继续处理的现象。
我一看系统版本,原来是PgSQL版本出现的问题(因为最近和一个同事在做数据库迁移的工作,从Orale迁移到PgSQL~)。
因为需要迁移的东西非常多,所以难免会暴露出来一些问题和缺陷。好了,闲话不多说,我们来看看问题吧。
问题:
投诉系统现阶段有5种不同类型的投诉件,每种投诉件的业务流程也都各不相同。我们通过投诉系统来处理不同类型投诉件,并且每个业务处理步骤我们都可以在页面上查看,其目的是方便追责和查看处理方式等。
一般来说,页面显示的处理步骤都是倒序的,即马上要进行的处理步骤是显示在页面最顶部的,上一步处理的信息显示在这条记录的下面,以此类推,最底部显示的就是该投诉件第一次进行业务处理的信息。
但是因为数据库迁移,页面上显示的处理步骤的信息的顺序乱掉了,并且在乱掉后,案件就无法继续处理了。
分析:
经过排查,发现两个关键:
1.投诉系统是从数据库中,根据序列生成的Task_ID倒序获取投诉件的业务状态,然后将其和当前操作的业务状态进行比较,如果不同,该投诉件就无法处理;
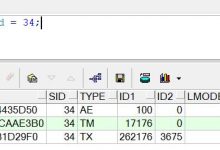
2.数据库中,同一投诉件的Task_ID倒序查询结果,和页面显示的一样,是乱掉的,这导致倒序获取的业务状态,很可能不是最新的业务状态(即已经处理过的业务状态)。
举个栗子:
投诉件一开始先提交,提交的时候在数据库同步生成业务状态为“待调查”(生成的Task_ID为2023)的记录;
然后投诉件继续处理,进行案件调查,这个时候数据库再次生成业务状态为“待查勘”(生成的Task_ID为2021)的记录;
当进行到第三步案件查勘的时候,系统根据倒序查询,从数据库中取出的案件状态为“待调查”,但是当前操作的业务为“待查勘”,两者不相符,所以该投诉件就被系统PASS了。
那么,为什么序列生成的Task_ID不是逐渐递增的呢?而是偶尔会出现穿插的现象呢?
原因:
这个现象,我们称之为“序列跳跃”(也有叫做序列跳号的)。之所以会出现这个现象,其实就是因为创建序列的时候,设置了序列的高速缓存的缘故。
序列的高速缓存原本是用于提高性能的,但是它也有自己的一些特性:
1.序列的高速缓存默认值为20;
2.序列的高速缓存值有锁一样的特性(假如将一个SQL称为会话,那么这个会话存在期间,2023——2043这20个序列值就是它独有的,其他会话无法使用);
3.序列的高速缓存值用不完就会被废弃(假如当前会话只使用了3个序列值,会话结束时,剩下的17个序列值会被直接废弃掉);
解决:
既然知道了原因,那么解决办法就十分简单了,我们现阶段测试的数据库是PGSQL,那么直接将相关序列高速缓存值设置为1即可(PGSQL高速缓存最低为1,不允许为0,Oracle可以设置为0或不设置)。
题外话:
虽然序列跳号的现象,会让主键值不连续、甚至错乱,但是依旧能够保证唯一性,并且能够提高性能。所以我们可以将设置了高速缓存的序列用在不需要保证递增或连续的字段上~