爱站程序员基地
爱站程序员基地写在前面
此系列是本人一个字一个字码出来的,包括示例和实验截图。本人非计算机专业,可能对本教程涉及的事物没有了解的足够深入,如有错误,欢迎批评指正。 如有好的建议,欢迎反馈。码字不易,如果本篇文章有帮助你的,如有闲钱,可以打赏支持我的创作。如想转载,请把我的转载信息附在文章后面,并声明我的个人信息和本人博客地址即可,但必须事先通知我。
你如果是从中间插过来看的,请仔细阅读**(一)羽夏看C语言——简述** ,方便学习本教程。本篇是C番外篇,会将零碎的东西重新集合起来介绍,可能会与前面有些重复或重合。
☀️ C语言和反汇编
C语言的入口main函数反汇编指令
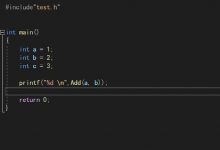
int main(){return 0;}
反汇编:
push ebpmov ebp,espsub esp,0x40push ebxpush esipush edilea edi,[ebp-0x40]mov ecx,0x10mov eax,0xccccccccrep stosdxor eax,eaxpop edipop esipop ebxmov esp,ebppop ebpret
☀️ 函数调用详解
C语言
int Plus(int x,int y){return x+y;}void main(){Plus(1,2);}
反汇编:
/*main函数*/push ebpmov ebp,espsub esp,0x40push ebxpush esipush edilea edi,[ebp-0x40]mov ecx,0x10mov eax,0xccccccccrep stosdpush 2 //压入倒数第一个参数push 1 //压入倒数第二个参数call 0x40100c //调用函数,假设Plus函数的地址为0x40100cadd esp,8 //保存堆栈平衡,恢复参数占用的堆栈pop edipop esipop ebxmov esp,ebppop ebpret/*Plus函数:地址<0x40100c>*/push ebp //将ebp的值压入堆栈中mov ebp,esp //将esp的值赋给ebpsub esp,0x40 //提升堆栈,提供缓冲区push ebxpush esipush edi/*===============================*/lea edi,[ebp-0x40] //获取esp-0x40处的值赋给edi,提供目标mov ecx,0x10 //将0x10赋给ecx,提供计数mov eax,0xcccccccc //将4个CC断点赋给eax,提供数据源rep stosd //从edi处填充eax的数据ecx次,每次edi+8hmov eax,dword ptr[ebp+8h] //eax=xadd eax,dword ptr[ebp+0xCh] //eax+=y//eax作为函数的返回值/*==========恢复下面的值==========*/pop edipop esipop ebx/*====下面的操作是恢复栈底栈顶====*/mov esp,ebppop ebpret
☀️ 全局变量
1、编译的时候就已经确定了内存地址和宽度,变量名就是内存地址的别名。2、如果不重写编译,全局变量的内存地址不变。
☀️ 局部变量
1、局部变量是函数内部申请的,如果函数没有执行,那么局部变量没有内存空间。2、局部变量的内存是在堆栈中分配的,程序执行时才分配。我们无法预知程序何时执行,这也就意味着,我们无法确定局部变量的内存地址。3、因为局部变量地址内存是不确定的,所以,局部变量只能在函数内部使用,其他函数不能使用。
☀️ 堆栈图
☀️ 数据类型
| 整型类型数据 | |||
|---|---|---|---|
| char | 8BIT | 1字节 | 0~0xFF |
| short | 16BIT | 2字节 | 0~0xFFFF |
| int | 32BIT | 4字节 | 0~0xFFFFFFFF |
| long | 32BIT | 4字节 | 0~0xFFFFFFFF |
☀️ 有符号与无符号的区别:
<1>正数有符号数与无符号数无区别<2>拓展时与比较时才有区别
| 浮点类型数据 | |
|---|---|
| float | 4字节 |
| double | 8字节 |
| long double | 8字节(某些平台的编译器可能是16个字节) |
float和double在存储方式上都是遵从IEEE编码规范的。对于整数部分,转化方式递归取余除以2,再逆序就是。而小数部分是递归乘二取整,正序就是。故用二进制描述小数,不可能做到完全精确。
☀️ 将一个float型转化为内存存储格式的步骤为:
<1>先将这个实数的绝对值化为二进制格式<2>将这个二进制格式实数的小数点左移或右移n位,直到小数点移动到第一个有效数字的右边。❤️>从小数点右边第一位开始数出二十三位数字放入第22到第0位。<4>如果实数是正的,则在第31位放入“0”,否则放入“1”。<5> 如果n是左移得到的,说明指数是正的,第30位放入“1”。如果n是右移得到的或n=0,则第30位放入“0”。<6> 如果n是左移得到的,则将n减去1后化为二进制,并在左边加“0”补足七位,放入第29到第23位。<7> 如果n是右移得到的或n=0,则将n化为二进制后在左边加“0”补足七位,再各位求反,再放入第29到第23位。
☀️ 浮点类型的精度
float和double的精度是由尾数的位数来决定的:
- float:2^23= 8388608,一共7位,这意味着最多能有7位有效数字;
- double:2^52,一共16位,这意味着最多能有16位有效数字;
☀️ 当分支比较多的时候,switch为什么效率比if-elif高:
switch语句
switch (x)0xBF10F8 mov eax,dword ptr [x]0xBF10FB mov dword ptr [ebp-0D0h],eax0xBF1101 mov ecx,dword ptr [ebp-0D0h]0xBF1107 sub ecx,10xBF110A mov dword ptr [ebp-0D0h],ecx0xBF1110 cmp dword ptr [ebp-0D0h],40xBF1117 ja $LN8+0Fh (0BF1171h)0xBF1119 mov edx,dword ptr [ebp-0D0h]0xBF111F jmp dword ptr [edx*4+0BF11A4h]{case 1:printf("1");0xBF1126 push offset string "1" (0C711B0h)0xBF112B call printf (0BF11C0h)0xBF1130 add esp,4break;0xBF1133 jmp $LN8+1Ch (0BF117Eh)case 2:printf("2");0xBF1135 push offset string "2" (0C711B4h)0xBF113A call printf (0BF11C0h)0xBF113F add esp,4break;0xBF1142 jmp $LN8+1Ch (0BF117Eh)case 3:printf("3");0xBF1144 push offset string "3" (0C711B8h)0xBF1149 call printf (0BF11C0h)0xBF114E add esp,4break;0xBF1151 jmp $LN8+1Ch (0BF117Eh)case 4:printf("4");0xBF1153 push offset string "4" (0C711BCh)0xBF1158 call printf (0BF11C0h)0xBF115D add esp,4break;0xBF1160 jmp $LN8+1Ch (0BF117Eh)case 5:printf("5");0xBF1162 push offset string "5" (0C711C0h)0xBF1167 call printf (0BF11C0h)0xBF116C add esp,4break;0xBF116F jmp $LN8+1Ch (0BF117Eh)default:printf("-1");0xBF1171 push offset string "-1" (0C711C4h)0xBF1176 call printf (0BF11C0h)0xBF117B add esp,4break;}
if-elif
if (x==1)0x6810F8 cmp dword ptr [x],10x6810FC jne main+4Dh (068110Dh){printf("1");0x6810FE push offset string "1" (07011B0h)0x681103 call printf (06811A0h)0x681108 add esp,40x68110B jmp main+0AEh (068116Eh)}else if (x==2)0x68110D cmp dword ptr [x],20x681111 jne main+62h (0681122h){printf("2");0x681113 push offset string "2" (07011B4h)0x681118 call printf (06811A0h)0x68111D add esp,4}0x681120 jmp main+0AEh (068116Eh)else if (x==3)0x681122 cmp dword ptr [x],30x681126 jne main+77h (0681137h){printf("3");0x681128 push offset string "3" (07011B8h)0x68112D call printf (06811A0h)0x681132 add esp,4}0x681135 jmp main+0AEh (068116Eh)else if (x==4)0x681137 cmp dword ptr [x],40x68113B jne main+8Ch (068114Ch){printf("4");0x68113D push offset string "4" (07011BCh)0x681142 call printf (06811A0h)0x681147 add esp,4}0x68114A jmp main+0AEh (068116Eh)else if (x==5)0x68114C cmp dword ptr [x],50x681150 jne main+0A1h (0681161h){printf("5");0x681152 push offset string "5" (07011C0h)0x681157 call printf (06811A0h)0x68115C add esp,4}0x68115F jmp main+0AEh (068116Eh)else{printf("-1");0x681161 push offset string "-1" (07011C4h)0x681166 call printf (06811A0h)0x68116B add esp,4}
由上可知,当条件比较多且比较有规律的时候,switch会生成装有内存地址位置的序列表,通过计算直接跳转到要去的位置,不需要多次判断。
☀️ 字节对齐
1、一个变量占用n个字节,则该变量的起始地址必须是n的整数倍,即:存放起始地址%n= 0。2、如果是结构体,那么结构体的起始地址是其最宽数据类型成员的整数倍。
☀️ 当对空间要求较高的时候,可以通过#pragma pack(n)来改变结构体成员的对齐方式
#pragma pack(1)struct Test{char a;int b;};#pragma pack()
1、
#pragma pack(n)
中n用来设定变量以n字节对齐方式,可以设定的值包括:1、2、4、8 ,VC编译器默认是8。2、结构体大总大小:N=Min(最大成员,对齐参数),是N的整数倍。
☀️ 指针类型的加减
1、不带"*"类型的变量,""或者"- -"都是加1或者减12、带"*"类型的变量,""或者"- -"新增(减少)的数量是去掉一个 * 后变量的宽度3、指针类型的变量可以加、减一个整数,但不能乘或者除4、指针类型变量与其他整数相加或者相减时:指针类型变量 + N=指针类型变量 + N *(去掉一个 * 后类型的宽度)指针类型变量 – N=指针类型变量 – N *(去掉一个 * 后类型的宽度)
☀️ 取值: *()与[]可以相互转换
*(p+i)= p[i]*(*(p+i)+k)= p[i][k]*(*(*(p+i)+k)+m)= p[i][k][m]*(*(*(*(*(p+i)+k)+m)+w)+t)= p[i][k][m][w][t]
☀️ 常见的调用约定
| 调用约定 | 参数压栈顺序 | 平衡堆栈 |
|---|---|---|
| cdecl | 从右至左入栈 | 调用者清理栈 |
| stdcall | 从右至左入栈 | 自身清理堆栈 |
| fastcall | 从右至左入栈,ECX/EDX传送前两个,剩下的通过堆栈 | 自身清理堆栈 |
☀️ 常见的预编译指令
| 指令 | 用途 |
|---|---|
| #define | 定义宏 |
| #undef | 取消已定义的宏 |
| #if | 如果给定条件为真,则编译下面代码 |
| #elif | 如果前面的lif给定条件不为真,当前条件为真,则编译下面代码 |
| #else | 同else |
| #endif | 结束一个#if ……#else条件编译块 |
| #ifdef | 如果宏已经定义,则编译下面代码 |
| #ifndef | 如果宏没有定义,则编译下面代码 |
| #include | 包含文件 |
☀️ C碎碎念
- 变量是什么?是装数据的一个容器。变量类型来约束数据的宽度。
- 在传参的时候,参数以堆栈的形式进行传递
- 缓冲区是干什么的?来存局部变量的
- 文字显示其实就是查表,然后将它在屏幕上画出来
- 常见的文字编码:ASCII、GB2312、Unicode
- ">>"右移运算符对于有符号数使用sar(算数右移,二进制数据右移,左边补符号位),无符号数为shr(逻辑右移,二进制数据右移,左边补0)
- "&"和"&&","|"和"||"虽然计算结果是一样的,但"&&"和"||"效率高,只要前面的满足表达式一定成立/不成立条件,就不再进行。
- 多维数组和一维数组在内存布局没有任何区别,都是线性存储的,只是为了开发人员方便使用。比如定义一个 int a[3][3][4],如果我使用 a[1][2][3],相当于在一维数组 a[3*3*4]中查询 a[1*3*4+2*4+3]。
- 提升的堆栈(缓冲区的大小)与声明的变量所占的字节数有关,如果变量不声明提升40个字节,如声明1个int,则会提升40+4个字节。但是,如果声明的变量不是本机宽度的正数倍,则按本机宽度的整数倍+1再乘以本机宽度处理。
本机宽度是指在硬件层面最擅长处理数据位数,比如声明一个char[10]的变量,在32位的系统下,本机宽度为4(64位的为8),由于10/4还有余数2故提升 40+4*(2+1)=52 个字节。10. 结构体在内存是连续存储的11. 指针只是一个新的类型,像普通的变量一样,所有的指针类型的宽度为四个字节,本质为无符号类型12. 宏定义本质是在编译器进行编译之前预处理器对代码文件进行替换13. 编译发现重复定义的问题时,而单独编译各模块不会出错,则很可能为重复包含导致的重定义。14. 如何解决重复包含问题? 条件编译 ;前置声明(如果一个类型在另一个头文件的函数或者类型,而头文件尽量不能重复包含,直接在此头文件声明一下就行);