 爱站程序员基地
爱站程序员基地
Python 基础
一、前言 一如既往,开始前先唠叨几句,这两年有点满足于现状了,最近出去找虐了,发现自己的技术有点渣,可以用几个不够来概括:不够扎实,不够深入,不够系统化。好了,啰嗦完了,学习的热情又上来了,计划用一个月的时间把同事遗留给我的书看完,哈哈...
一、前言 一如既往,开始前先唠叨几句,这两年有点满足于现状了,最近出去找虐了,发现自己的技术有点渣,可以用几个不够来概括:不够扎实,不够深入,不够系统化。好了,啰嗦完了,学习的热情又上来了,计划用一个月的时间把同事遗留给我的书看完,哈哈...

关于 StatsModels statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化。 文档 最新版本的文档位于:https://www.g...

一.算法流程 adaboost回归模型与分类模型类似,主要的不同点在于错误率的计算、基模型的权重计算以及样本权重的更新,下面就直接介绍算法流程部分 输入:训练集\\(T=\\{(x_1,y_1),(x_2,y_2),…,(x_N...
简介 前面已经介绍过了一些模型,它们各有各的优缺点: (1)比如SVM中,虽然它的最大化间隔能带来不错的泛化能力,但如果某些支持向量恰好是异常点,那么它的决策边界可能会错的很离谱; (2)对于决策树,虽然它的非线性拟合能力很强,但如果放纵树...

TIOBE 编程语言排行榜 7 月更新已公布,排名前十的分别是:Java, C, Python, C++, C#, Visual Basic .NET, JavaScript, PHP, SQL 和汇编语言。 TIOBE 编程社区指数(Th...
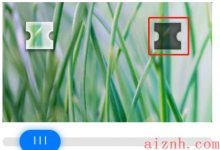
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈。 今天分享个如何简单处理滑动图片的验证码的案例。 ...

一. 简介 Bagging的思路很简单,对大小为\\(n\\)的样本集进行\\(n\\)次重采样得到一个新的样本集,在新样本集上训练一个基学习器,该过程执行\\(m\\),最后对这\\(m\\)个基学习器做组合即得到最后的强学习器: 二.代...
一.简介 上一节已经介绍了提升树的算法流程,这一节只需要将下面的优化过程替换成求解具体的梯度即可: \\[w_m^*=arg\\min_{w_m}\\sum_{i=1}^NL(y_i,f_{m-1}(x_i)+T(x_i,w_m))\\] ...

Locust是一款Python技术栈的开源的性能测试工具。Locust直译为蝗虫,寓意着它能产生蝗虫般成千上万的并发用户: Locust并不小众,从它Github的Star数量就可见一斑: 截止文章写作时,一共15951Star。 Locu...
一.简介 为了让学习器越发的不同,randomforest的思路是在bagging的基础上再做一次特征的随机抽样,大致流程如下: 二.RandomForest:分类实现 import osos.chdir(\'../\')from ml_m...