昨日内容回顾
# 僵尸进程:所有的进程在运行结束之后并不会立刻销毁(父进程需要获取该进程的资源)# 孤儿进程:子进程正常运行 但是产生该子进程的父进程意外死亡# 守护进程:守护进程的结束取决于被守护的对象的进程何时结束
# 锁:将并发变成串行 牺牲了效率 但是保证了数据的安全# 代码:mutex.require() 抢锁mutux.release() 释放锁\'\'\'锁虽然好用 但是不要轻易使用容易造成死锁现象(今后也不会让我们自己处理锁 但是要理解原理)\'\'\'
# 目的:为了确保供需平衡
几乎与进程对象的方法一致
消息队列就是一个可以存放数据的地方 并且数据遵循先进先出的原则主要是用于解决生产者与消费者处理能力不一致的问题
今日内容概要
- GIL全局解释器锁(重要理论)
- 验证GIL的存在及功能
- 验证python多线程是否有用
- 死锁现象
- 进程池与线程池
- IO模型
内容详细
1、GIL全局解释器锁
# 官网解释In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiplenative threads from executing Python bytecodes at once. This lock is necessary mainlybecause CPython’s memory management is not thread-safe. (However, since the GILexists, other features have grown to depend on the guarantees that it enforces.)"""翻译:1.python解释器其实有很多版本(默认使用的是CPython)Cpython、Jpython、pypython2.在CPython中GIL全局解释器锁其实也是一把互斥锁 主要用于阻止同一个进程下的多个线程同时被运行(python的多线程无法使用多核优势)3.GIL肯定存在于CPython解释器中 主要原因就在于CPython解释器的内存管理不是线程安全的4.内存管理>>>就是:垃圾回收机制三大特征:引用计数标记清除分代回收"""# 特点1.GIL仅仅是Cpython解释器的特点(跟python语言没有任何关系)2.python同一个进程内的多个线程无法利用多核优势(不能并行但可以并发)3.同一个进程内的多个线程想要运行必须先抢GIL锁4.所有的解释型语言几乎都无法实现同一个进程下的多个线程同时被运行
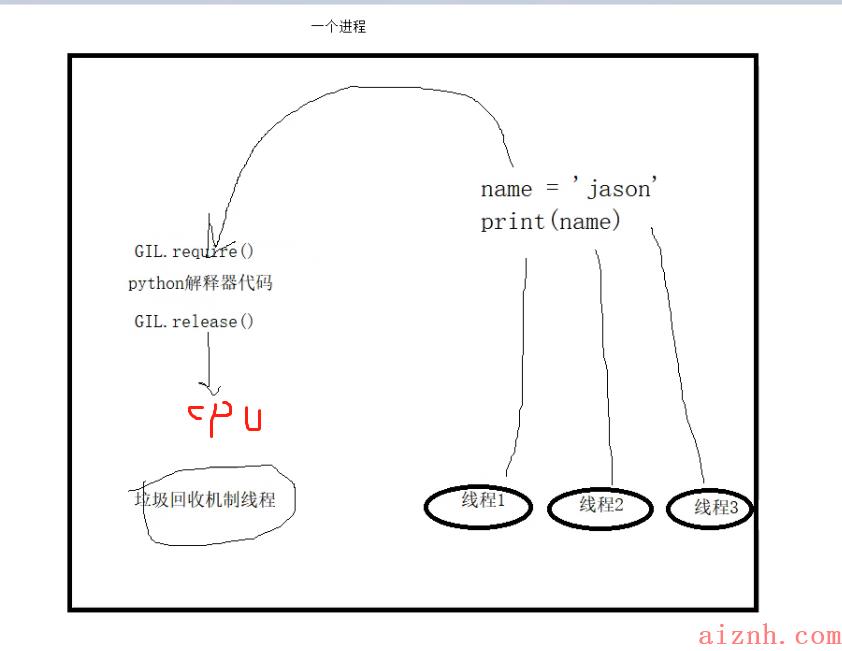
2、验证GIL的存在
# 验证一import timefrom threading import Threadm = 100def test():global mtmp = mtmp -= 1m = tmpfor i in range(100):t = Thread(target=test)t.start()time.sleep(2) # 相当于 t.join()print(m)"""执行结果:0数据没有错乱 因为默认的GIL锁让每个线程实现串行"""# 验证二import timefrom threading import Threadm = 100def test():global mtmp = mtime.sleep(1)tmp -= 1m = tmpfor i in range(100):t = Thread(target=test)t.start()time.sleep(2) # 相当于 t.join()print(m)"""执行结果:99因为所有的子线程执行到 time.sleep(1) 时候 会释放GIL锁其他子线程再去抢锁 抢到之后还是以 tmp=100 来减 1"""# 总结:同一个进程下的多个线程 虽然有GIL锁的存在不会出现并行效果但是如果线程内有IO操作 还是会造成数据的错乱这个时候需要我们额外添加互斥锁
3、死锁现象
# 1.复习class MyClass():passA = MyClass()B = MyClass()print(A == B) # Falseprint(A is B) # False"""只要类加括号实例化出来的对象 无论参数是否一致实例化几次就会产生几个完全不一样的对象"""# 2.死锁现象from threading import Thread, Lockimport timeA = Lock()B = Lock()class MyThread(Thread):def run(self):self.func1()self.func2()def func1(self):A.acquire()print(\'%s 抢到了A锁\' % self.name) # self.name获取线程的名字B.acquire()print(\'%s 抢到了B锁\' % self.name)time.sleep(1)B.release()print(\'%s 释放了B锁\' % self.name)A.release()print(\'%s 释放了A锁\' % self.name)def func2(self):B.acquire()print(\'%s 抢到了B锁\' % self.name)A.acquire()print(\'%s 抢到了A锁\' % self.name)A.release()print(\'%s 释放了A锁\' % self.name)B.release()print(\'%s 释放了B锁\' % self.name)for i in range(10):obj = MyThread()obj.start()"""执行结果:卡住Thread-1 抢到了A锁Thread-1 抢到了B锁Thread-1 释放了B锁Thread-1 释放了A锁Thread-1 抢到了B锁Thread-2 抢到了A锁线程1要抢A锁 但是A锁在线程2手上线程2要强B锁 但是B锁在线程1手上因为都没有抢到所需要的锁 所以也不能释放已经抢到的锁就会造成死锁现象就算知道锁的特性及使用方式 也不要轻易的使用 因为容易产生死锁现象"""
4、python多线程是否没用
是否有用需要看情况而定(程序的类型)# 1.IO密集型(代码体中有停顿、等待...)例如:四个任务 每个任务耗时 10s01 开设多进程没有太大的优势 遇到IO就需要切换 并且开设进程还需要申请内存空间和拷贝代码 10s+02 开设多线程有优势 不需要消耗额外的资源(不需要额外申请内存空间) 10s+(要比 01的10s短)from threading import Threadfrom multiprocessing import Processimport osimport timedef work():time.sleep(2)if __name__ == \'__main__\':l = []print(os.cpu_count()) # 查看本机可用核数 8start = time.time()for i in range(400):# p = Process(target=work) # 开设400个进程时间 18s多p = Thread(target=work) # 开设400个线程时间 2s多l.append(p)p.start()for p in l:p.join()stop = time.time()print(\'运行时间是%s\'%(stop-start))"""IO密集型开设多线程更有优势"""# 2.计算密集型(实时计算数据)例如:四个任务 每个任务耗时10s01 开设多进程可以利用多核优势(每个核处理自己的任务) 10s+02 开设多线程无法利用多核优势 40s+from threading import Threadfrom multiprocessing import Processimport osimport timedef work():res = 0for i in range(100000000):res *= iif __name__ == \'__main__\':l = []print(os.cpu_count()) # 查看本机可用核数 8start = time.time()for i in range(8):p = Process(target=work) # 开设多进程时间 21s多# p = Thread(target=work) # 开设多线程时间 71s多l.append(p)p.start()for p in l:p.join()stop = time.time()print(\'运行时间是%s\' % (stop - start))\'\'\'提升效率方式:多进程结合多线程\'\'\'
5、进程池与线程池
# 能否无限制的开设进程或者线程?肯定是不能无限制开设的"""如果单从技术层面上来说 无限开设肯定是可以的并且是最高效的但是从硬件层面上来说 是无法实现的(硬件的发展永远跟不上软件的发展速度)"""# 池:在保证计算机硬件不崩溃的前提下 开设多进程和多线程降低了程序的运行效率 但是保证了计算机硬件的安全# 进程池与线程池进程池:提前开设了固定个数的进程 之后反复调用这些进程完成工作(后续不再开设新的)线程池:提前开设了固定个数的线程 之后反复调用这些线程完成工作(后续不再开设新的)# 代码实现:import timefrom concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor# 创建进程池或线程池# pool = ProcessPoolExecutor() # 默认是池子里面的进程数与当前计算机CPU核数保持一致 也可以自定义pool = ThreadPoolExecutor() # 默认是池子里面的线程数是当前计算机CPU核数的五倍 也可以自定义def task(n):print(\'开始\')res = 1for i in range(n):res += itime.sleep(1)# print(res)return \'结果:%s\' % res# 往池中提交任务l = []for i in range(100):ret = pool.submit(task, i) # 异步提交任务 也相当于 .start()l.append(ret)pool.shutdown() # 等待池子中所有任务运行完毕之后关闭池子 再往后运行主代码体 相当于并发串行for i in l:print(i.result()) # 同步提交任务 获取任务的执行结果\'\'\'结果实现并发\'\'\'
 爱站程序员基地
爱站程序员基地



