爱站程序员基地
爱站程序员基地简介
从业也有些年头了,用过不少监控相关的开源系统,ganglia,nagios,cacti,zabbix,grafana,Prometheus等等,其实随着软件的越发犀利,模板的越加通用,人会懒,甚至不再会去在意一些参数为啥要监控,有什么用,那么多数据,如果判断。
想法是写一个小的系列吧,大致的总结下系统一些主要的性能,如何判断,对应的值有什么样的作用等等。
不讲什么很深奥的东西,尽量浅显易懂。尽量从使用的角度来陈述相关参数。从系统判断和监控布局的角度出发。
一步步来,先说vmstat和系统CPU的关系。
vmstat
vmstat (virtual memory statistics),看名字挺明显的对不对,展示系统虚拟内存性能的,但实际上它的功能远不止于此,比如说针对CPU,他可以活动如下信息:
1,正在运行的进程个数
2,CPU当前的使用情况
3,CPU接收的中断次数
4,调度器执行的上下文的切换次数
作为对于系统的纵览,墙裂推荐vmstat
基本使用方案
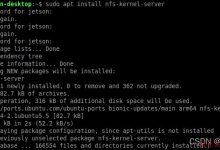
Example: vmstat 1 5
1 -> 时间间隔为1s,每隔1s输出当前到上一次输出之间的系统情况
5 -> 输出5次

如上图:第一行是系统启动至今的平均值,如果看起来很怪不用太在意,后面四行表示当前状态
PS:vmstat可以非root执行,很贴心,毕竟很多监控必须root。
和CPU相关每一列代表什么
1,正在运行的进程个数r: CPU 可运行队列,这个队列代表当前可运行的且正在等待cpu时间资源的进程,理想情况下,数量不要超过vcpu数量。b: 阻塞队列,就是现在卡着的,不需要系统时间资源。2,CPU当前的使用情况us: 用户进程消耗的总的cpu时间的百分比 (包括nice time)。sy: 系统代码消耗的总的cpu时间的百分比(包括 system irq和softirq时间)。id: 系统空闲时间消耗的总的cpu时间的百分比。wa: 等待IO资源消耗的总的cpu时间的百分比。st: 虚拟机向宿主机申请资源消耗的总的cpu时间的百分比。总结下:us+sy+id+wa+st=100%3,CPU接收的中断次数in: 系统发生中断的次数4,调度器执行的上下文的切换次数cs:系统发生上下文切换的次数
这个指令很适合监控,嗯,为什么?
1,不需要root执行,基本谁都行。
2,所有参数直接读取文本文件,发生提取异常的几率非常低。
如何直观的判断CPU的当前状况
下述的顺序就是cpu发生异常时的判断顺序,系统发生异常一个个看即可。
正在运行的进程个数
1,r 参数的数量,不要超过当前系统的cpu核数2,理论上来说b的数量过大代表IO阻塞严重,这时候要分类讨论(1)r 的值大的话,,就是cpu太忙了,查看系统进程为啥那么多。(2)r 的值明显持续小于cpu数量,说明有大量的IO阻塞,根据wa参数和当前硬盘读写情况进行问题检索。
CPU当前的使用情况
再强调下先决条件:us+sy+id+wa+st=100%1,id大于90:别看了,挺闲的,没啥问题。2,wa大于20,短板在于IO,考虑下硬盘情况吧。3,st大于10:当前物理机资源有问题,导致虚拟机申请出问题,找服务商,找网管,或者自己看下物理机(宿主机)的情况吧。4,us和sy:这个属于细节分析了,看系统消耗主要卡在用户自有模块还是内核模块,描述起来有点大,不赘述了,看上面三个差不多了
CPU接收的中断次数
调度器执行的上下文的切换次数
1,这俩一起说比较直观:上下文切换的数量(cs)小于系统中断的数量(in)的话,那说明系统还是比较空闲的,反之则说明切换太过频繁,系统状态不佳
vmstat数据来源
/proc/meminfo/proc/stat/proc/*/stat上述都是系统的文件,vmstat其实是做了个宏观的数据展示而已当然,展示的很不错,有助于运维更直观的进行系统的判断
总结
CPU的判断并不困难,上述主要描述的是如何初步的定位当前系统的大致CPU状态已经根源所在。
其实,找到真正的捣蛋的程序并从运维的角度窥的更为详细的状况才是经验的体现。
当然vmstat也非全能,其实真正的信息系统都提供在了自身的文件系统里面,之后的文章会想办法阐述如何定位CPU异常的精确信息以及其他的一些用于系统判断的指令。