爱站程序员基地
爱站程序员基地项目背景
最近做项目,发现oracle中存在重复数据,导致项目查询结果冗余,特此需要对数据进行去重。比如下面截图所示:
场景一:根据单个字段(Id)来判断重复记录
1、查找表中多余的重复记录,重复记录是根据单个字段(Id)来判断
select * from 表 where Id in (select Id from 表 group byId having count(Id) > 1);
2、删除表中多余的重复记录,重复记录是根据单个字段(Id)来判断,只留有rowid最小的记录
DELETE from 表 WHERE (id) IN ( SELECT id FROM 表 GROUP BY id HAVING COUNT(id) > 1) AND ROWID NOT IN (SELECT MIN(ROWID) FROM 表 GROUP BY id HAVING COUNT(*) > 1);
场景二:根据多个字段来判断重复记录
1、查找表中多余的重复记录(多个字段)
select * from 表 a where (a.Id,a.seq) in(select Id,seq from 表 group by Id,seq having count(*) > 1);
2、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from 表 a where (a.Id,a.seq) in (select Id,seq from 表 group by Id,seq having count(*) > 1) and rowid not in (select min(rowid) from 表 group by Id,seq having count(*)>1);
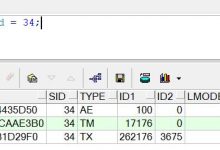
执行结果
执行完毕,可以看到重复的数据已经被删除了。
只要朝着一个方向努力,一切都会变得得心应手。——勃朗宁