 爱站程序员基地
爱站程序员基地[TOC](第6章 使用事件溯源开发业务逻辑)
前言
事件溯源是一种以事件为中心的编写业务逻辑和持久化领域对象的方法。事件溯源可以消除一些可能的编程错误,因为这项技术可以保证在创建或更新聚合时一定会发布事件。
这是一本关于微服务架构设计方面的书,这是本人阅读的学习笔记。下面对一些符号做些说明:
()为补充,一般是书本里的内容;[]符号为笔者笔注;
1. 使用事件溯源开发业务逻辑概述
事件溯源模式:使用一系列便是状态更改的领域事件来持久化聚合。
1.1 传统持久化技术的问题
- 对象与关系的“阻抗失调”:关系型数据的表格结构模式,与领域模型及其复杂关系的图状结构之间,存在基本的概念不匹配的问题;
- 缺乏聚合历史:聚合更新后,其先前的状态将丢失;
- 实施升级功能将非常繁琐且容易出错:耗时,负责记录审计日志的代码可能会和业务逻辑代码发生偏离;
- 事件发布凌驾于业务逻辑之上:无法把自动发布消息作为更新数据事务的一部分;
1.2 事件溯源通过事件来持久化聚合
事件溯源采用基于领域事件的概念来实现聚合的持久化;它将每个聚合持久化为数据库中的一系列事件,称为事件存储。
 图解:
图解:
- 事件溯源不是将每个Order作为一行存储在ORDER表中,而是将每个Order聚合持久化为EVENTS表中的一行或多行;
- 应用程序创建或更新聚合时,它会将聚合发出的事件插入到EVENTS表中;
- 应用程序通过从事件存储中检索并重放事件来加载聚合(如Eventuate Client框架),加载聚合的步骤:加载聚合的事件;
- 使用其默认构造函数创建聚合实例;
- 调用apply()方法遍历事件;
1.3 事件溯源对领域事件提出的新需求
- 事件代表状态的改变;
- 聚合方法都和事件相关;
1.4 事件代表状态的改变
- 在事件溯源情况下,聚合主要决定事件及其结构;
- 包括创建在内的每一个聚合状态变化,都由领域事件表示;
- 每当聚合的状态发生改变时,它必须发出一个事件;
- 事件中必须包含聚合执行状态变化所需的数据;
- 聚合的状态由构成聚合对象的字段值组成;

1.5 聚合方法都和事件相关;
- 基于事件溯源的应用程序中的命令方法通过生成事件来处理对聚合更新的请求;
- 调用聚合命令方法的结果是一系列事件,表示必须进行的状态更改;

- 生成事件并应用(apply)事件的做法将导致对业务逻辑的重构;事件溯源将命令方法重构为两个或更多个方法;第一个方法
process()
接收命令对象参数,该参数表示具体的请求,并确定需要自行哪些状态更改;它验证命令对象的参数,并且在不更改聚合状态的情况下,返回表示状态更改的事件列表;如果无法执行该命令,则此方法通常会引发异常;
- 其他方法
apply()
都将特定事件类型作为参数来更新聚合;这些方法与聚合产生的事件类型一一对应;重要的是要注意执行这些方法不会出现失败,因为这些事件代表了一个已经发生的状态变化;每个方法都会根据事件更新聚合;
- 一个例子如下:

图解:
-
reviseOrder()
方法被
process()
方法和
apply()
方法替代;
-
process()
方法将ReviseOrder命令作为参数;
-
process()
方法要么返回OrderRevisionProposed事件,要么抛出异常;如时间太晚已不能修改订单或建议订单修订不满足订单最小值的时候;
apply()
方法将Order的状态更改为REVISION_PENDING;
1.6 创建与更新聚合的步骤
创建聚合的步骤:
- 使用聚合的默认构造函数实例化聚合根;
- 调用process()以生成新事件;
- 遍历新生成的事件并调用apply()来更新聚合的状态;
- 将新事件保存在事件存储库中;
更新聚合的步骤:
- 从事件存储库加载聚合事件;
- 使用其默认构造函数实例化聚合根;
- 遍历加载的事件,并在聚合根上调用apply()方法;
- 调用其process()方法以生成新事件;
- 遍历新生成的事件并调用appply()来更新聚合的状态;
- 将新事件保存在事件储存库中;
1.7 基于事件溯源的Order聚合

- 业务逻辑通过命令来实现,这些命令发出事件并应用那些更新其状态的事件;
- 创建或更新基于JPA的聚合的每个方法,如
createOrder()
和
reviseOrder()
,在事件溯源版本中都由
process()
和
apply()
方法替代;

- 基于JPA聚合的修改订单业务逻辑由三个方法组成:
reviseOrder()
、
confirmRevision()
和
rejectRevision()
;
- 事件溯源版本使用三个
process()
方法和一些
apply()
方法替代这三个的方法;
1.8 使用乐观锁处理并发更新
指两个或多个请求同时更新同一聚合的情况;
- 乐观锁通常使用版本列(映射到VERSION列)来检测聚合自读取以来是否已更改;
- 每当更新聚合时,VERSION列的值会增加;
- 两个有两个事物读取相同的聚合,第一个成功,第二个不成功;因为版本号已更改;
1.9 事件溯源和发布事件
- 使用轮询发布事件;如下图所示:
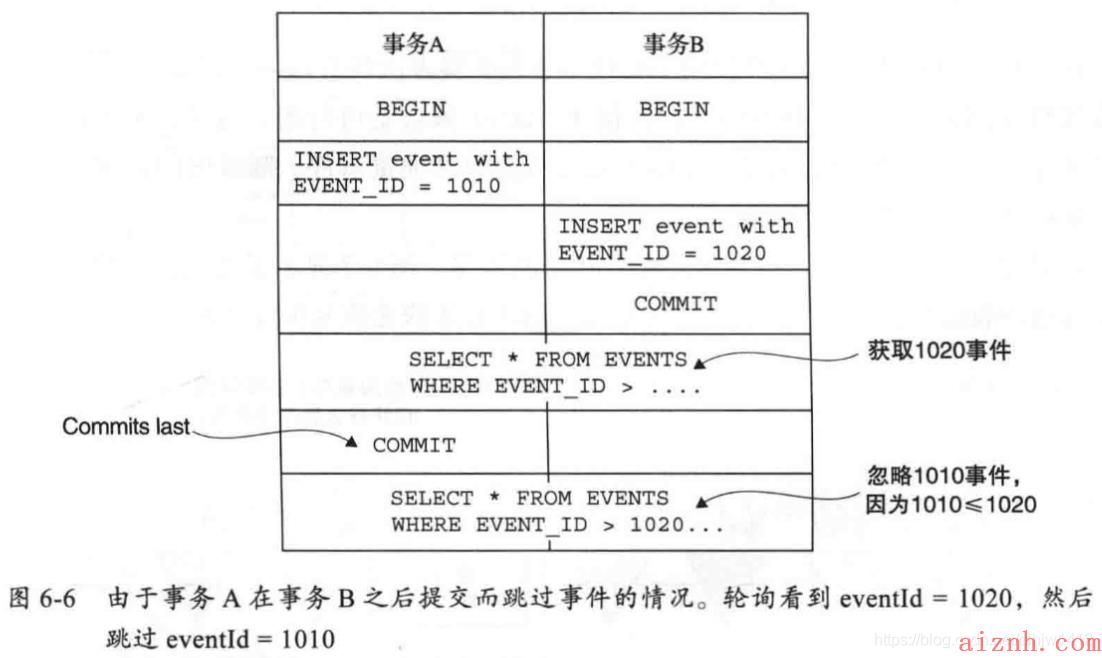

- 本篇第2点详解;
1.10 使用快照提升性能
长生命周期的聚合可能会有大量事件;随时间推移,加载和重放这些事件会变得越来越低效;常见解决方法是定期持久保存聚合状态的快照;

1.11 幂等方式的消息处理
使用相同的消息多次安全地调用消息接收方,则消息接收方是幂等的;具体实现方式取决于事件储存库是关系型数据库还是NoSQL数据库;
- 基于关系型数据库事件储存库的幂等消息处理;可以将消息ID插入PROCESSED_MESSAGES表,作为插入EVENTS表的事件的事务的一部分 [相同消息被接受时,若数据库中已经存在ID,则忽略该消息请求];
- 往往功能有限,需要使用不同的机制来实现幂等消息处理;
1.12 领域事件的演化
事件溯源应用程序的结构分三个层次:
- 由一个或多个聚合组成;
- 定义每个聚合发出的事件;
- 定义事件的结构;
每个级别可能发生的不同类型的更改:

- 服务的领域模型随着时间的推移而发展,这些变化会自然发生;
- 不向后兼容段更改都需要更改该事件类型的消费者;
通过向上转换(Upcasting)来管理结构的变化:
- 事件溯源框架不是将事件迁移到新的版本,而是在从事件存储库加载事件时执行转换;
- 通常用称为“向上转换”的组件将各个事件从旧版本更新为更新的版本;
1.13 事件溯源的好处与弊端
好处:
- 可靠地发布领域事件;
- 保留聚合的历史;
- 最大限度地避免对象与关系的“阻抗失调”问题(持久化事件而不是聚合本身);
- 为开发者提供一个“时光机”;
弊端:
- 这类编程模式有一定的学习曲线;
- 基于消息传递的应用程序的复杂性;指处理非等幂事件时;
- 解决方法:为每个事件分配单调递增的ID;
- 指事件和快照的结构随时间推移变得臃肿;
- 欧洲的GDPR给予用户对其数据的擦除权,而用户信息可能嵌入在事件结构中,如邮箱作为聚合的主键,应用程序必须在不删除事件的情况下清除特定用户信息;
- 指可能会使用嵌套的更为复杂的且可能低效的查询;
2. 实现事件存储库
使用事件溯源的应用程序将事件存储在事件存储库中;事件存储库是数据库和消息代理功能的组合;它表现为数据库和消息代理;
- 实现事件存储库有多种方法,一种是实现自己的事件存储库和事件溯源代码框架;另一种是使用专用事件存储库;
- 专用事件存储库通常提供丰富的功能集、更好的性能和可扩展性;
- 如:Event Store、Lagom、Axon、Eventuate SaaS;
2.1 Eventuate Local事件存储库的工作原理
Eventuate Local的事件数据库结构:
- events:存储事件(最核心);与本篇1.2点的图类似;
- 储存每个实体的当前版本;用于实现乐观锁;
- 储存每个实体的快照;
通过订阅Eventuate Local的事件代理接受事件:
- 服务通过订阅事件代理来使用事件,事件代理具有每个聚合类型的主题;
- 主题是分区的消息通道,使接收方能够在保持消息排序的同时进行水平扩展;
Eventuate Local的事件中继把事件从数据库传播到消息代理:
- 事件中继将插入事件数据库的事件传播到事件代理;
- 它尽可能使用事务日志拖尾,或轮询其他数据库;
- 事件部署为独立进程;
2.2 针对Java语言的Eventuate Client框架提供的主要类和接口
Eventuate Client框架使开发人员能够使用Eventuate Local事件存储库编写基于事件溯源的应用程序;它为开发基于事件溯源的聚合、服务和事件处理程序提供了框架基础;

图解:
- 通过ReflectiveMutableCommandProcessingAggregate类定义聚合;该类是聚合的基类,是一个泛型类;
- 有两个类型参数:具体的聚合类、聚合命令类的超类;
- 使用反射将命令和事件分别分派给process()和apply()方法;
- 聚合的命令类必须扩展特定于聚合的基接口,该接口本身必须扩展Command接口;
- 聚合的事件类必须扩展Event接口,这是一个没有方法的标识接口;
- 该类是一个泛型类,它接收的参数是聚合类和聚合的基命令类;
- Eventuate Client框架还提供了用于编写事件处理程序的API,如:
@EventSubscriber
注解指定持久化订阅方的ID;
@EventHandlerMethod
注解将creditReserved()方法标识为事件处理程序;
3. 同时使用Saga和事件溯源
事件溯源可以轻松使用基于协同式的Saga;将事件溯源的业务逻辑与基于编排的Saga相结合更具挑战性;
3.1 使用事件溯源实现协同式Saga
- 事件溯源的事件驱动属性使得实现基于协同式的Saga非常简单;
- 当聚合被更新时,它会发出一个事件;不同聚合的事件处理程序可以接受该事件,并更新该聚合;事件溯源框架自动使每个事件处理程序具有幂等性;
- 事件溯源代码提供了Saga所需的机制,包括基于消息传递的进程间通信、消息去重,以及原子化状态更新和消息发送;
- 弊端:事件体现双重目的性,即事件溯源使用事件来表示状态更改,但使用事件实现Saga协同,需要聚合即使没有状态更改也必须发出事件;解决方法:使用编排式来实现复杂的Saga;
3.2 创建编排式Saga
Saga编排器由服务的方法创建,会执行创建和更新聚合两项操作,该服务必须保证则两个操作在同一个事物中完成;因此取决于使用的事件数据库类型;
当关系型数据库作为事件存储库时,应该如何创建Saga编排器:
- 比较简单,使用
@Transactional
注解,使Eventuate Local框架与Eventuate Tram Saga框架在同一个ACID事务中更新时间存储库并创建Saga编排器即可;
当非关系型数据库作为事件存储库时,应该如何创建Saga编排器:
- 由于NoSQL数据库的事务模型功能有限,应用程序将无法以原子方式创建或更新两个不同的对象;
- 服务必须具有一个事件处理程序,该事件处理程序将创建Saga编排器来响应聚合发出的领域事件;
3.3 使用事件处理程序创建Saga编排器的案例
 好处:保证松耦合,因为OrderService之类的服务不再明确地实例化Saga;
好处:保证松耦合,因为OrderService之类的服务不再明确地实例化Saga;
问题:如何处理重复事件保证幂等性,解决方法如下:
- 从事件的唯一属性中导出Saga的ID;有多种选择,其中一种是使用发出事件的聚合的ID作为Saga的ID,适用于为响应聚合创建事件而创建的Saga;
- (有效)使用事件ID作为Saga ID;因为事件ID的唯一性能保证Saga ID也是唯一的;
3.4 实现基于事件溯源的Saga参与方
- 命令式消息的幂等处理;很容易解决:Saga参与方在处理消息时生成的事件中记录消息ID;在更新聚合之前,Saga参与方通过在事件中查找消息ID来验证它之前是否处理过该消息;
- 解决方法:让Saga参与方继续向Saga编排器的回复通道发送回复消息;当Saga命令处理程序创建或更新聚合时,它会安排将SagaReplyRequested伪事件与聚合发出的实际事件一起保存在事件存储库中;
3.5 基于事件溯源的Saga参与方的例子
下图显示了Accounting Service如何处理Saga发送的Authorize Command;Accounting Service使用Eventuate Saga框架,该框架用于编写使用事件溯源的Saga;

3.6 实现基于事件溯源的Saga编排器
- 使用事件溯源持久化Saga编排器;可以使用以下事件持久化Saga:SagaOrchestratorCreated:Saga编排器已创建;
- SagaOrchestratorUpdated:Saga编排器已更新;
- 关键在于如何以原子方式更新Saga的状态并发送命令;

- 确保只处理一次回复消息;类似前面描述的机制;编排器将回复消息的ID存储在处理回复时发出的事件中;
4. 本章小结
- 事件溯源将聚合作为一系列事件持久化保存。每个事件代表聚合的创建或状态更改。应用程序通过重放事件来重建聚合的当前状态。事件溯源保留领域对象的历史记录,提供准确的审计日志,并可靠地发布领域事件;
- 快照通过减少必须重放的事件数来提高性能;
- 事件存储在事件存储库中,该存储库是数据库和消息代理的混合。当服务在事件存储库中保存事件时,它会将事件传递给订阅者;
- Eventuate Local是一个基于MySQL和Apache Kafka的开源事件存储库。开发人员使用Eventuate Client框架来编写聚合和事件处理程序;
- 使用事件溯源的一个挑战是处理事件的演变。应用程序在重放事件时可能必须处理多个事件版本。一个好的解决方案是使用向上转换,当事件从事件存储库加载时,它会将事件升级到最新版本;
- 在事件溯源应用程序中删除数据非常棘手。应用程序必须使用加密和假名等技术,以遵守欧盟GDPR等法规,确保在应用程序中彻底清除个人数据;
- 事件溯源可以很简单实现基于协调的Saga。服务具有事件处理程序,用于监听基于事件溯源的聚合发布的事件;
- 我们也可以使用事件溯源技术实现Saga编排器。你可以编写专门使用事件存储库的应用程序;
最后
新人制作,如有错误,欢迎指出,感激不尽!欢迎关注公众号,会分享一些更日常的东西!如需转载,请标注出处!



